







简介
微信公众平台的消息回复格式多样,本文主要讲解其中的图文消息回复的开发。使用的是python语言。
其中微信消息回复请参考之前的文档,这里只需要修改相应的xml格式即可。
另外运用到一点简单的爬虫和正则的知识。
开发环境
sae + python
文档阅读
图文消息回复格式
<xml>
<ToUserName><![CDATA[toUser]]></ToUserName>
<FromUserName><![CDATA[fromUser]]></FromUserName>
<CreateTime>12345678</CreateTime>
<MsgType><![CDATA[news]]></MsgType>
<ArticleCount>2</ArticleCount>
<Articles>
<item>
<Title><![CDATA[title1]]></Title>
<Description><![CDATA[description1]]></Description>
<PicUrl><![CDATA[picurl]]></PicUrl>
<Url><![CDATA[url]]></Url>
</item>
<item>
<Title><![CDATA[title]]></Title>
<Description><![CDATA[description]]></Description>
<PicUrl><![CDATA[picurl]]></PicUrl>
<Url><![CDATA[url]]></Url>
</item>
</Articles>
</xml> 说明
| 参数 | 是否必须 | 说明 |
|---|---|---|
| ToUserName | 是 | 接收方帐号(收到的OpenID) |
| FromUserName | 是 | 开发者微信号 |
| CreateTime | 是 | 消息创建时间 (整型) |
| MsgType | 是 | news |
| ArticleCount | 是 | 图文消息个数,限制为10条以内 |
| Articles | 是 | 多条图文消息信息,默认第一个item为大图,注意,如果图文数超过10,则将会无响应 |
| Title | 否 | 图文消息标题 |
| Description | 否 | 图文消息描述 |
| PicUrl | 否 | 图片链接,支持JPG、PNG格式,较好的效果为大图360*200,小图200*200 |
| Url | 否 | 点击图文消息跳转链接 |
剖析
仔细阅读xml的格式,可以发现主要提供的是文章列表,每个文章需要四个字段,标题、描述、图片链接、消息跳转链接。
新闻可以通过爬虫爬取,然后通过正则表达式提取标题、图片、简介以及原文链接。
python代码封装xml
def getResponseImageTextXml(self, FromUserName, ToUserName, sourceList):
"""
source = [title, description, picurl, url]
"""
itemXml = []
for source in sourceList:
# source = [title1, description1, picurl, url]
singleXml = """
<item>
<Title><![CDATA[%s]]></Title>
<Description><![CDATA[%s]]></Description>
<PicUrl><![CDATA[%s]]></PicUrl>
<Url><![CDATA[%s]]></Url>
</item>
""" % (source[0], source[1], source[2], source[3])
itemXml.append(singleXml)
reply = """
<xml>
<ToUserName><![CDATA[%s]]></ToUserName>
<FromUserName><![CDATA[%s]]></FromUserName>
<CreateTime>%s</CreateTime>
<MsgType><![CDATA[news]]></MsgType>
<ArticleCount>%d</ArticleCount>
<Articles>
%s
</Articles>
</xml>
""" % (FromUserName, ToUserName, str(int(time.time())), len(sourceList), " ".join(itemXml))
response = make_response(reply)
response.content_type = 'application/xml'
return response说明
其他细节请参考本博客之前所发的文章
测试
搜索微信公众号iCasual并关注,回复新闻,然后回复相应的关键词即可测试,本文主要以“智取威虎山”、“小米”、“树莓派”作为测试用例。
大家可以输入其他关键词,尝试新闻检索系统的效果。
整理具体测试步骤如下:
打开公众号iCasual 》 回复关键词:新闻 》 回复相应的检索词,比如:小米 》 获取新闻检索结果。
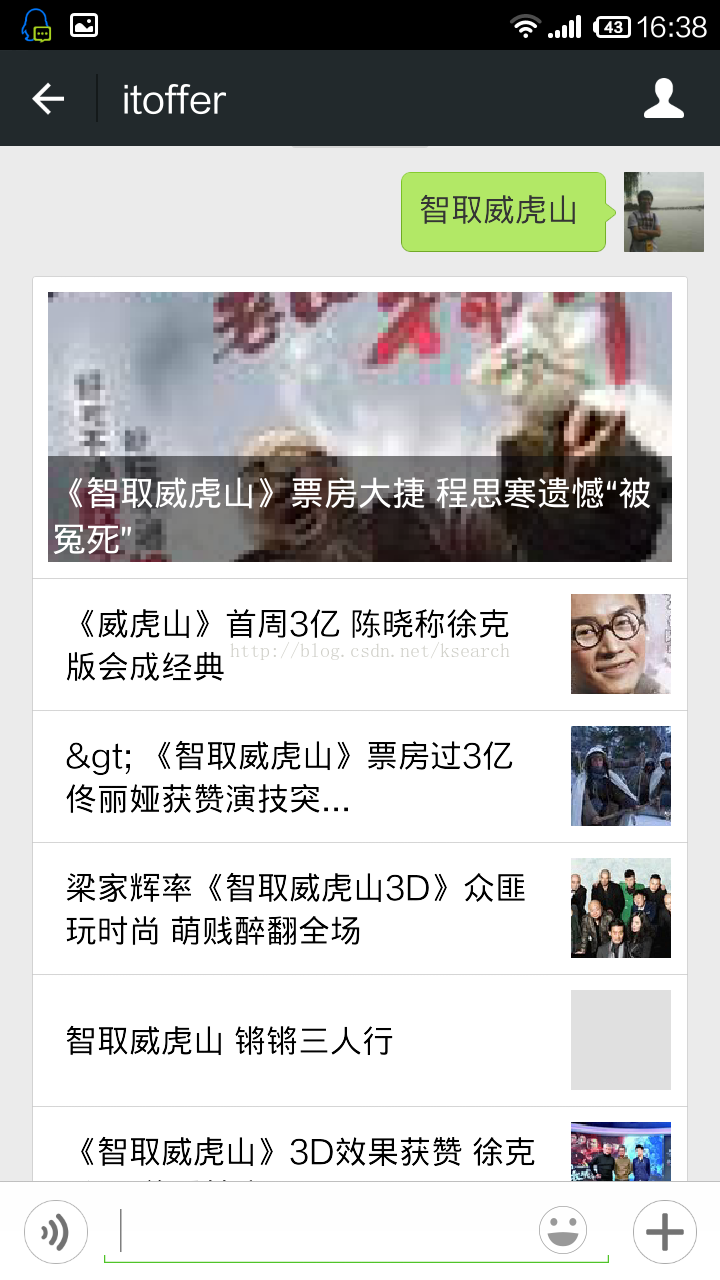


附:
用python开发的网站:
发诗词。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









