







 本文深入探讨Java集合框架中的排序与搜索优化技术,包括Collections类如何避免链表结构排序带来的性能瓶颈,通过将List转换为数组,利用Arrays.sort()方法实现高效排序,并介绍TimSort与LegacyMergeSort的区别;同时解释了binarySearch方法的实现,以及针对不同大小链表的indexBinarySearch()和iteratorBinarySearch()方法的区别;最后讨论了shuffle方法在链表排序时的特殊策略。
本文深入探讨Java集合框架中的排序与搜索优化技术,包括Collections类如何避免链表结构排序带来的性能瓶颈,通过将List转换为数组,利用Arrays.sort()方法实现高效排序,并介绍TimSort与LegacyMergeSort的区别;同时解释了binarySearch方法的实现,以及针对不同大小链表的indexBinarySearch()和iteratorBinarySearch()方法的区别;最后讨论了shuffle方法在链表排序时的特殊策略。
- sort()
可以看到,Collections并不是直接对List进行排序操作,这是因为排序过程中可能会涉及大量的随机访问,类似于LinkedList这样的链表结构就会十分耗时。所以先将List转换为Arrays(普通数组),然后调用Arrays.sort()进行排序。完成排序之后,再一个一个地,把Arrays的元素复制到List中。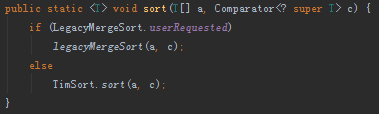 在Arrays.sort()方法中,由LegacyMergeSort.userRequested决定是采用MergeSort还是TimSort。LegacyMergeSort.userRequested由"java.util.Arrays.useLegacyMergeSort"设置。
在Arrays.sort()方法中,由LegacyMergeSort.userRequested决定是采用MergeSort还是TimSort。LegacyMergeSort.userRequested由"java.util.Arrays.useLegacyMergeSort"设置。![]()
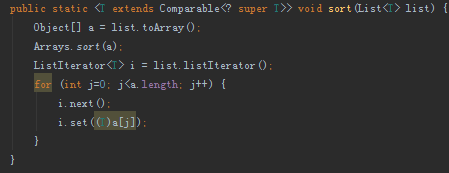

TimSort是改进后的归并排序,对归并排序在已经反向排好序的输入时表现为O(n^2)的特点做了特别优化。对已经正向排好序的输入减少回溯。对两种情况(一会升序,一会降序)的输入处理比较好(摘自百度百科)。
- binarySearch()
binarySearch存在两种方法:indexedBinarySearch()和iteraotrBinarySearch(),前者针对具备随机存取能力的List以及小的链表,后者适用于大的链表。
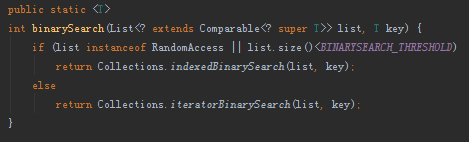
BINARYSEARCH_THRESHOLD用于判断一个链表是大还是小,它的值为5000。
indexBinarySearch()和iteratorBinarySearch()只在一个地方存在区别。
indexBinarySearch():

iteratorBinarySearch():
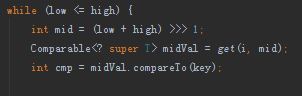
可以看到,它们在取midVal采用了不同的方法。前者使用了list默认的get()方法,后者使用了Collections.get()方法。
对于链表而言,区别在于:list默认的get()方法每次都是从头部开始遍历,直到指定位置。Collections.get()方法会记住上次查询的位置,然后从该位置开始遍历,直到指定位置。
- shuffle()

shuffle()方法一样对链表采用了特殊策略,当链表长度大于SHUFFLE_THRESHOLD(设置为5)时,会先把链表转换为数组,然后再洗牌。
洗牌用了随机数。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









