







http://blog.csdn.net/pipisorry/article/details/48901217
海量数据挖掘Mining Massive Datasets(MMDs) -Jure Leskovec courses学习笔记之关联规则Apriori算法的改进:基于hash的方法:PCY算法, Multistage算法, Multihash算法
Apriori算法的改进
{All these extensions to A-Priori have the goal of minimizing the number of pairs that actually have to be counted on the second pass.}
当频繁项对的数量比较大时,内存放不下,而这时对频繁项对进行计数时,可能会产生内存抖动,即内存页面频繁换入换出,因为不同的频繁项对计数器可能放在不同的页面上。
Apriori算法的改进算法
这些算法可以用在海量数据上的关联规则挖掘中。
(1)基于hash的方法。一个高效地产生频集的基于杂凑(hash)的算法由Park等提出来。通过实验可以发现寻找频集主要的计算是在生成频繁2-项集Lk上,Park等就是利用了这个性质引入杂凑技术来改进产生频繁2-项集的方法。
基于哈希的算法仍是将所有所有数据放入内存的方法。只要在计算的过程中能够满足算法对内存的大量需求,Apriori算法能够很好的执行。但在计算候选项集时特别是在计算候选项对C2时需要消耗大量内存。针对C2候选项对过大,一些算法提出用来减少C2的大小。这里我们首先考虑PCY算法,这个算法使用了在Apriori算法的第一步里大量没使用的内存。接着,我们考虑Multistage算法,这个算法使用PCY的技巧,但插入了额外的步骤来更多的减少C2的大小。类似的还有Multihash。
(2)基于划分的方法。Savasere等设计了一个基于划分(partition)的算法.这个算法先把数据库从逻辑上分成几个互不相交的块,每次单独考虑一个分块并对它生成所有的频集,然后把产生的频集合并,用来生成所有可能的频集,最后计算这些项集的支持度。这里分块的大小选择要使得每个分块可以被放入主存,每个阶段只需被扫描一次。而算法的正确性是由每一个可能的频集至少在某一个分块中是频集保证的。
(3)基于采样的方法。基于前一遍扫描得到的信息,对此仔细地作组合分析,可以得到一个改进的算法,Mannila等先考虑了这一点,他们认为采样是发现规则的一个有效途径。
Apriori算法回顾
Apriori算法流程步骤图解
数据挖掘概念与技术中对Apriori算法的图解
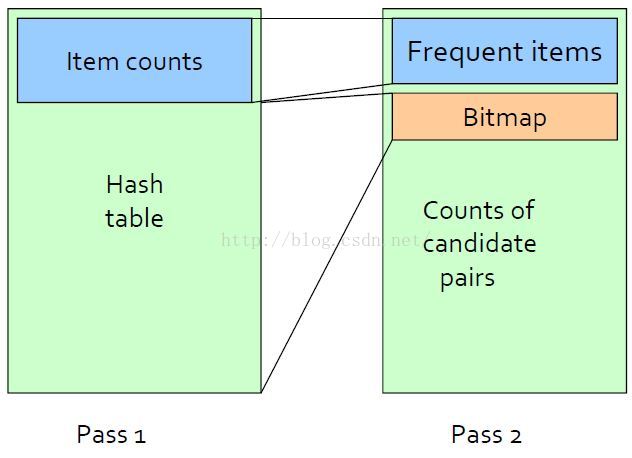
Apriori算法的内存的使用情况
左边为第一步时的内存情况,右图为第二步时内存的使用情况
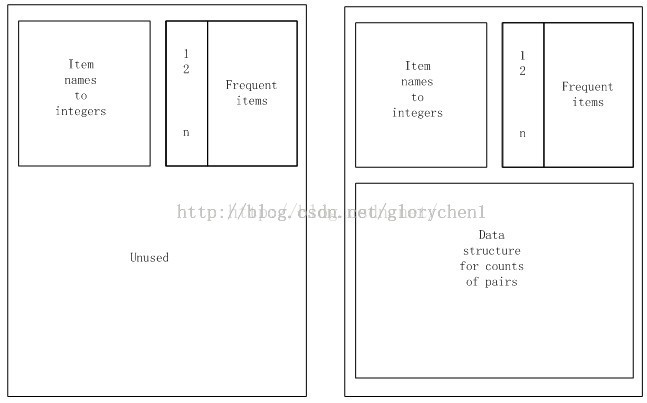
在第一步(对所有item扫描计数,并选出频繁一项集)里,我们只需要两个表,一个用来保存项的名字到一个整数的映射,用这些整数值代表项,一个数组来计数这些整数。
PCY算法使用了在Apriori算法的第一步里大量没使用的内存,该算法关注在频繁项集挖掘中的第一步有许多内存空间没被利用的情况。如果有数以亿计的项,和以G计的内存,在使用关联规则的第一步里我们将会仅仅使用不到10%的内存空间,会有很多内存空闲。
对Aprior进行改进:第一步扫描
从basket中统计项的个数用于寻找频繁一项集,并从每个basket中产生所有项对,并为项对创建一张hash表,hash表只是统计hash到本桶的项对的个数。

数据挖掘概念与技术中对PCY算法解释的一个示例
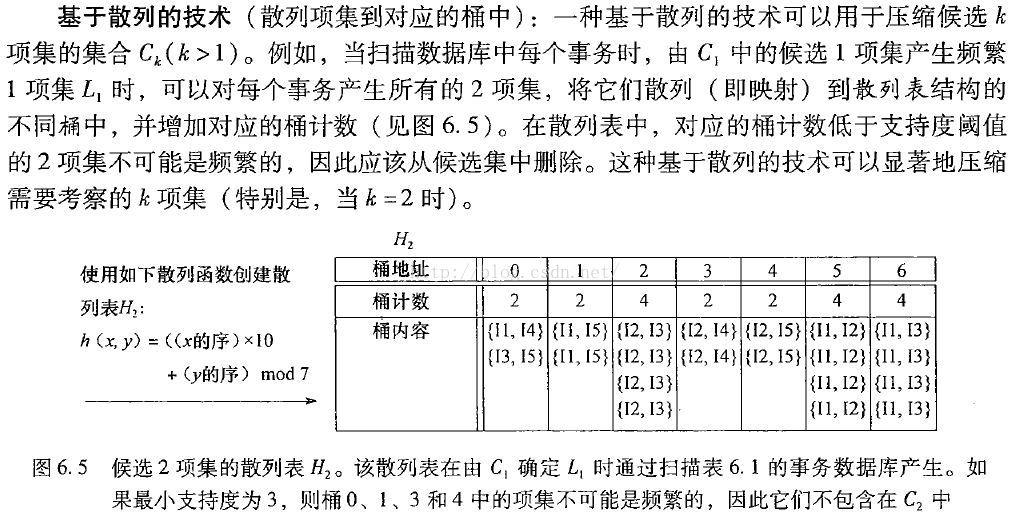
1. 这一步相当于提前进行一次非频繁项对的筛选,如果将所有不同项对hash到不同桶中,当然就相当于Apriori算法对所有项对进行计数了,内存还是会超的!但是,这里我们项对hash时会有不同的项对hash到同一个桶中,即使是多个项对,如果它们都是非频繁的,加起来也很可能是非频繁的(很多情况下)。删除掉这些包含许多非频繁项对的非频繁桶,就筛选掉了很多完全不必进入候选二项集C2的的项对。
2. 图中桶内容只是便于理解,实际只存储桶计数,不存储桶内容。
假设我们有1G的内存可用来在第一步做hash表存放,并假设数据文件包含在10亿篮子,每个篮子10个项。一个桶为一个整数,通常定义为4个字节,于是我们可以保存2.5亿个桶。
所有篮子的项对的数量总数为即
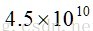
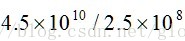
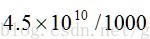
PCY算法pass1伪代码

对Aprior进行改进:第二步扫描
统计哪些是频繁桶,并只需对哈希到频繁桶的两个频繁项进行计数处理,只有频繁桶中的项对才会当作是候选项对。这样每个频繁桶内的频繁项集比较少,寻找更大频繁项集的计算量就大大降低了。


在PCY算法第二步操作前,哈希表被压缩为bitmap,在这里,每一个bit用作一个桶。若桶为频繁桶,则位置1,否则置0。这样32bit的整数被压缩为只有1bit。然后再PCY的第二步操作中,bitmap只占了原来所用空间的1/32。
如果大部分的桶都是非频繁桶,我们可以预料,在第二步的项对计数后产生的频繁项集会更小。这样,PCY算法就能直接在内存中处理这些数据集而不会耗尽内存。
PCY中的候选集C2为这样的项对{i, j}:
1. i和j是频繁项
2. {i,j}哈希到一个频繁桶(这是PCY与Apriori的区别)
Note:1. 候选集C2中候选项对{i, j}在Apriori中的唯一条件是:i和j是频繁项
2. When we count pairs on the second pass,we have to use the tabular method.
lz分析的pass2的算法应该是这样的:扫描每个basket中所有的项对,如果项对中每一项都是频繁项(频繁一项集),并且 {i,j}哈希后对应到一个频繁桶,则将这个项对加入到{item, item, count}中,组成一个Tabular Table。
PCY算法内存使用分析
PCY算法的内存组织形式,左图为步骤1的内存使用情况,右图为步骤2的内存使用情况
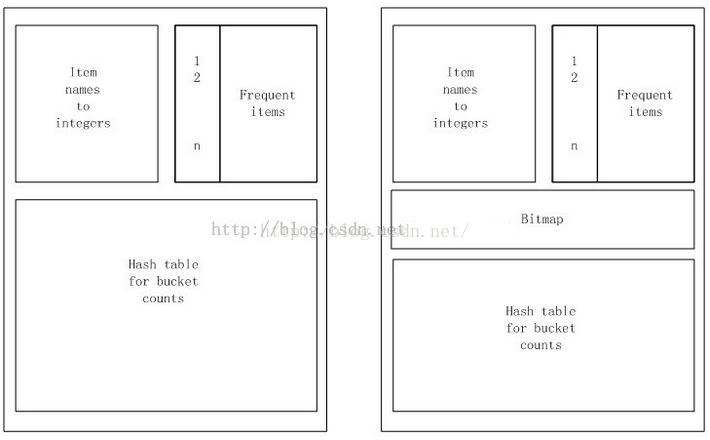
第一步内存使用详解

PCY算法使用第一步空闲的内存来保存一个整数数组。将这个数组看做一个哈希表,表的桶中装的是整数值而不是一组key值。项对被哈希到这些桶中。在第一步扫描篮子的处理中,我们不但将这些项对加一,并且通过两步循环,我们创造出所有的项对。我们将项对哈希到哈希表中,并且将哈希到的位置加一。注意,项本身不会进入桶,项对的加入只是影响桶中的整数值。On the first pass when we read a basket we not only increment the count for each of it's items.We also hash each pair that is contained in the basket.And for each resulting bucket,we increment it's count by one.
实际上每个bucket只需要使用2bytes来计数,因为支持度S一般不会超过2bytes大小的数,而计数等于S后没必要再+1。In many cases we can get by with two bytes per bucket.The reason is that it is sufficient to count after this poor threshold S, What we really want to do is,if the current count is less than S, and increment the count,otherwise leave the count at S.
第二步内存使用详解

但是频繁桶中也可能都是非频繁项对。Even without any frequent pair, a bucket can be frequent.Because each bucket's count is the sum of the counts of all of the pairs that hash to it.
But the only time that we have to count a pair in the second pass, and that pair turns out to not to be frequent,is when the pair consists of two frequent items.
However, we get a lot of leverage when a bucket is not frequent.In that case, we do not have to count any of the pairs that count for that bucket even if that pair consist of two frequent items.
在PCY算法第二步操作前,哈希表被压缩为bitmap,在这里,每一个bit用作一个桶。若桶为频繁桶,则位置1,否则置0。这样32bit的整数被压缩为只有1bit。然后再PCY的第二步操作中,bitmap只占了原来所用空间的1/32。
如果大部分的桶都是非频繁桶,我们可以预料,在第二步的项对计数后产生的频繁项集会更小。这样,PCY算法就能直接在内存中处理这些数据集而不会耗尽内存。
使用tabular方法

When we count pairs on the second pass,we have to use the tabular method.[关于triangular和tabular存储方式参考关联规则与频繁项集挖掘]
The problem is that the pairs that are eliminated because they hash to an infrequent bucket, are scattered all over the place, and cannot be organized into a nice triangular array.因为riangular要确定的项对的数目,然而删除了(bitmap对应位为0)多少个项对并不知道。
PCY算法的取舍
1. As a result, we should not use PCY unless we can eliminate at least two-thirds of the candidate pairs when compared with A-Priori.
2. 在步骤1中使用hash表可能并不能带来好处,这取决于数据大小和空闲内存大小。在最坏的情形下,所有的桶都是频繁的,PCY计算的项对与A-priori是一样的。然而,在通常的情况下,大多数的桶都是非频繁的。这种情况下,PCY算法降低了第二步内存的使用。也就是说,只有桶平均计数值<阈值S,则大多数桶是非频繁的,可以删除很多非频繁项对,这时PCY算法才更有效。
3. The number of buckets will be fraction of the size of main memory,typically almost half or a quarter.The only time that would not be true is if there were so many different items, that we needed all of most of main memory just to count them.In that case we could not use the PCY algorithm.
Mutistage 算法 多步哈希算法
Multistage算法是在PCY算法的基础上使用一些连续的哈希表来进一步降低候选项对。相应的,Multistage需要不止两步来寻找频繁项对。
我们知道,在PCY第一次遍历后,得到的频繁桶中也可能都是非频繁项对。如果我们能再次对PCY的候选项对进行一次hash(使用另一种hash函数),就能进一步删除掉候选项对中的非频繁项对。。


Multistage算法步骤
Multistage的第一步跟PCY的第一步相同。
在第一步后,频繁桶集也被压缩为bitmap,这也和PCY相同。但是在第二步,Multistage不计数候选项对。而是使用空闲主存来存放另一个哈希表,并使用另一个哈希函数。因为第一个哈希表的bitmap只占了1/32的空闲内存,第二个哈希表可以使用几乎跟第一个哈希表一样多的桶。
Multistage的第二步,我们同样是需要遍历篮子文件。只是这步不需要再对候选项进行计数了,我们哈希这些候选项对{i, j}到第二个哈希表的桶中。一个候选项对{i, j}如同PCY算法一样,被哈希仅当它满足两个条件:如果i和j都是频繁的且它们在第一步被哈希到频繁桶中。这样,第二个哈希表中的计数总数将比第一步明显减少,能再次对PCY的候选项对进行一次hash(使用另一种hash函数),就能进一步删除掉候选项对中的非频繁项对。可知即便是在第二步是由于第一步的bitmap占据了1/32的空闲空间,剩下的空间也照样够第二步的hash表使用。
Multistage的第三步--计算候选频繁项对,一开始第二个hash表同样被压缩成bitmap。该bitmap也同样保存在内存中。这时,两个bitmap加起来也只占到不到空闲内存的1/16,还有相当的内存可用来做第三步的计算候选频繁项对的处理。
一个相对{i,j}在C2中,当且仅当满足:
1、 i和j都是频繁项
2、 {i,j}在第一步哈希时被哈希到频繁桶中
3、 {i,j}在第二步哈希时被哈希到频繁桶中
Multistage方法和PCY方法的主要区别
在于第二步pass2,PCY直接在pass2中得到候选项对,并扫描所有basket对候选项对进行计数来筛选出频繁二项集;而Multistage将在pass2中得到候选项对再次进行hash,到pass3中再筛选出频繁二项集。
一步中使用多个hash函数
很显然,在算法中可用在第一步和最后一步中添加任意多的中间步骤。这里的限制就是在每一步中必须用一个bitmap来保存前一步的结果,最终这里会使得没有足够的内存来做计数。不管我们使用多少步骤,真正的频繁项对总是被哈希到一个频繁桶中。If PCY gives you an average count of 1 tenth of the support threshold,then you can use five hash tables instead.
Multistage算法图解
Multistage算法使用额外的哈希表来减少候选项对,左图为第一步内存使用情况,中图为第二步内存使用情况,右图为第三步内存使用情况
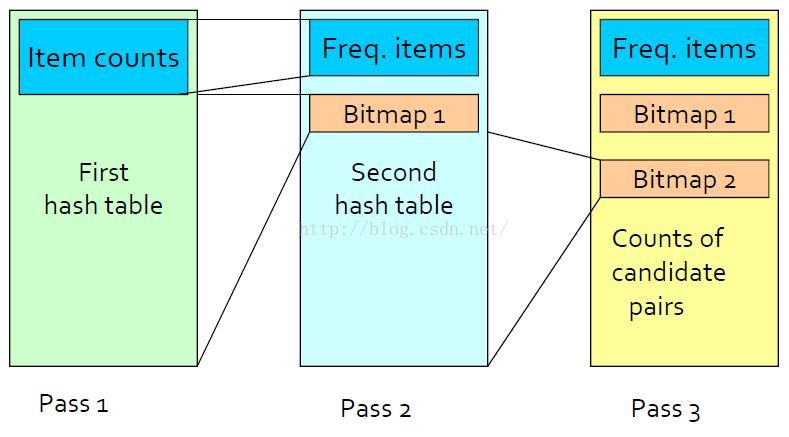
pass2中的hash table中hash的项对满足两个条件:i和j都是频繁项;{i,j}在第一步哈希时被哈希到频繁桶中。
pass3中的candidate pairs中项对满足三个条件:i和j都是频繁项; {i,j}在第一步哈希时被哈希到频繁桶中; {i,j}在第二步哈希时被哈希到频繁桶中。
要注意的问题

pass3中的candidate pairs中项对满足三个条件中必须要有:i和j都是频繁项; {i,j}在第一步哈希时被哈希到频繁桶中。
因为有这种情况:i和j都是频繁项;{i,j}在第一步哈希时被哈希到非频繁桶中;{i,j}在第二步哈希时被哈希到频繁桶中。(但是这个好像有问题?{i,j}在第二步哈希时,{i,j}必须满足在第一步哈希时被哈希到频繁桶中的条件)
Multihash算法 多次哈希算法

multistage算法和Multihash算法的区别及取舍
multistage算法在连续的两个步骤中使用两个哈希表,Multihash算法在一步中使用两个哈希算法和两个分离的哈希表。
在同一步里使用两个hash表的危险是每个哈希表仅有PCY算法的一半的桶, 这样每个桶上的平均计数会翻倍,我们必须保证大多bucket不会达到阈值S。只要PCY算法的桶的平均计数比支持度阈值低,我们就可以预见大部分的桶都是非频繁桶,并可以在这两个只有一半大小的哈希表上操作完成。在这种情形下,我们选择multihash方法。
对Multihash的第二步,每个hash表也会被转换为一个bitmap,并且两个bitmap占据的空间只有PCY算法的一个bitmap的大小。项对{i,j}被放入候选集C2的条件:i和j必须是频繁的,且{i,j}对在两个哈希表中必须被hash到频繁桶。
当然,在Multihash算法中,我们也可以不用限制只使用两个hash表。在Multihash算法的第一步中,我们也可以使用多个hash表。不过风险是桶的平均计数会超过阈值,在这种情况下,这里会只有很少的非频繁桶在每个hash表中。即使这样,一个项对必须被hash到每个hash表的频繁桶中并计数,并且我们会发现,一个非频繁项对作为一个候选的概率将上升,无利反而有害。
multistage算法图解
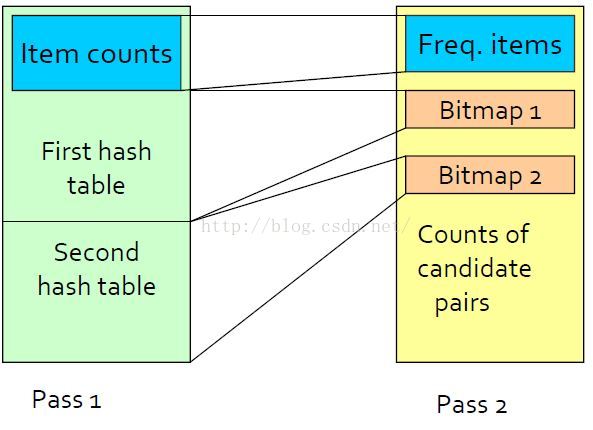
项对{i,j}被放入候选集C2的条件:i和j必须是频繁的;{i,j}对在两个哈希表中都被hash到频繁桶中。
Reviews复习
Note:
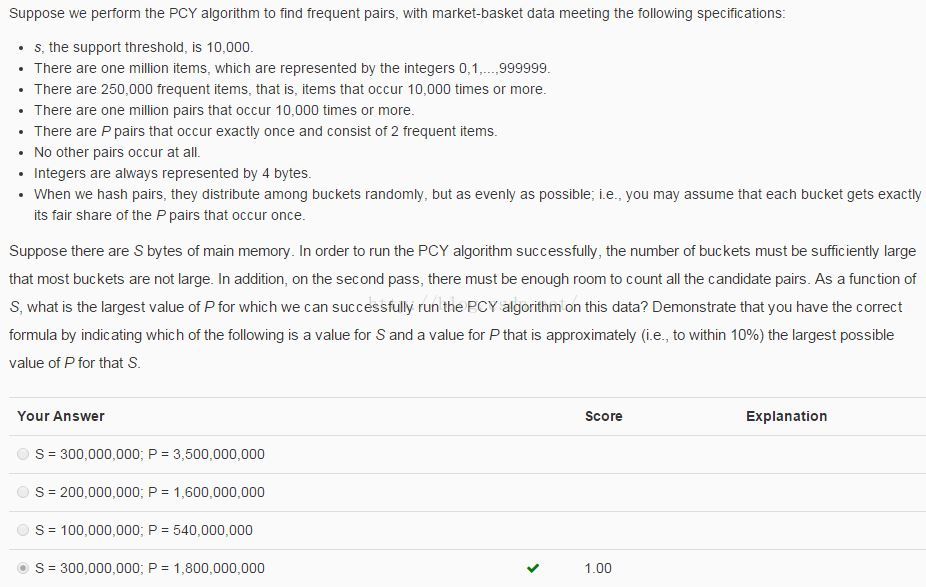
首先定义几个变量:桶buckets的数目为B,Items的数目为I = 10^6,频繁项对数目M = 10^6,我们要求的是P和S要满足的关系。
第一步中的内存消耗:4*B + 4*I <=S,由于4个选项中S的数量级都为10^8,故可认为4*B <=S, 也就是说桶的数目S最多为B = S/4,这也是保证PCY算法成功运行的条件(桶数目要足够大,题目中也有说明)
第二步中的内存消耗:12*(P/B*M + M) <=S(Tabular方式存储)。由于第二步的内存主要由候选项对消耗,而候选项对一定包含频繁项集M个,并且也包含不是频繁项对的项对{i, j}(就是P中的项对),其中i,j都是频繁项,并被随机hash到频繁桶(由于桶数目足够大,则频繁桶数目有M个)中,由于是均匀随机hash的,这样的项对{i, j}有P/B*M个。同时可以看出P/B远大于1,故可认为12*P/B*M <=S。
综上,可得出不等式:P <= S^2/(5*10^7),P的最大取值为P = S^2/(5*10^7)
S = 3*10^8, P = 2*10^9选项1过大,选项4差不多
S = 2*10^8, P = 10^9选项2过大
S = 1*10^8, P = 2*10^8选项3过大
ref:大数据:频繁项集
R. Agrawal, T. Imielinski, and A. Swami. Mining association rules between sets of items in large databases. Proceedings of the ACM SIGMOD Conference on Management of data, pp. 207-216, 1993.
A. Savasere, E. Omiecinski, and S. Navathe. An efficient algorithm for mining association rules in large databases. Proceedings of the 21st International Conference on Very large Database, 1995J. S. Park, M. S. Chen, and P. S. Yu. An effective hash-based algorithm for mining association rules. Proceedings of ACM SIGMOD International Conference on Management of Data, pages 175-186, San Jose, CA, May 1995.
H. Mannila, H. Toivonen, and A. Verkamo. Efficient algorithm for discovering association rules. AAAI Workshop on Knowledge Discovery in Databases, 1994, pp. 181-192.
J.Han,J.Pei,and Y.Yin.Mining frequent patterns without candidate generation.In Proc.2000 ACM-SIGMOD Int.Conf.Management of Data(SIGMOD’00),Dalas,TX,May 2000.
Edith Cohen, Mayur Datar, Shinji Fujiwara, Aristides Gionis, Piotr Indyk, Rajeev Motwani, Jeffrey D.Ullman, Cheng Yang. Finding Interesting Associations without Support Pruning. 1999
M. Fang, N. Shivakumar, H. Garcia-Molina, R. Motwani, and J. D. Ullman, “Computing iceberg queries efficiently,” Intl. Conf. on Very Large Databases, pp. 299-310, 1998.
H. Toivonen, “Sampling large databases for association rules,” Intl. Conf. on Very Large Databases, pp. 134–145, 1996.














 1581
1581











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









