




 本文通过Python实现模拟登录山东大学成绩查询系统,抓取并计算绩点。详细介绍了使用HttpFox插件分析网络请求,理解POST数据和Cookie,以及如何构造请求并使用正则表达式提取所需信息。
本文通过Python实现模拟登录山东大学成绩查询系统,抓取并计算绩点。详细介绍了使用HttpFox插件分析网络请求,理解POST数据和Cookie,以及如何构造请求并使用正则表达式提取所需信息。
先来说一下我们学校的网站:
http://jwxt.sdu.edu.cn:7777/zhxt_bks/zhxt_bks.html
查询成绩需要登录,然后显示各学科成绩,但是只显示成绩而没有绩点,也就是加权平均分。

显然这样手动计算绩点是一件非常麻烦的事情。所以我们可以用python做一个爬虫来解决这个问题。
1.决战前夜
先来准备一下工具:HttpFox插件。
这是一款http协议分析插件,分析页面请求和响应的时间、内容、以及浏览器用到的COOKIE等。
以我为例,安装在火狐上即可,效果如图:
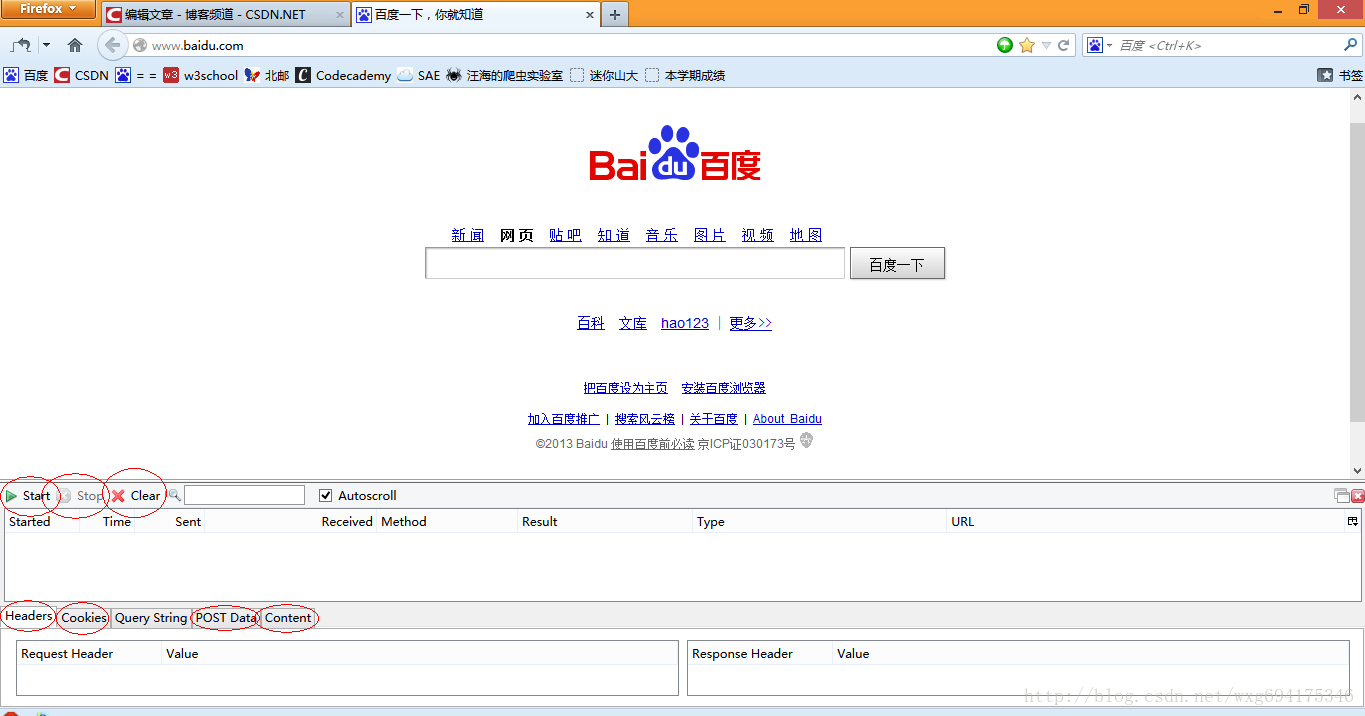
可以非常直观的查看相应的信息。
点击start是开始检测,点击stop暂停检测,点击clear清除内容。
一般在使用之前,点击stop暂停,然后点击clear清屏,确保看到的是访问当前页面获得的数据。
2.深入敌后
下面就去山东大学的成绩查询网站,看一看在登录的时候,到底发送了那些信息。
先来到登录页面,把httpfox打开,clear之后,点击start开启检测: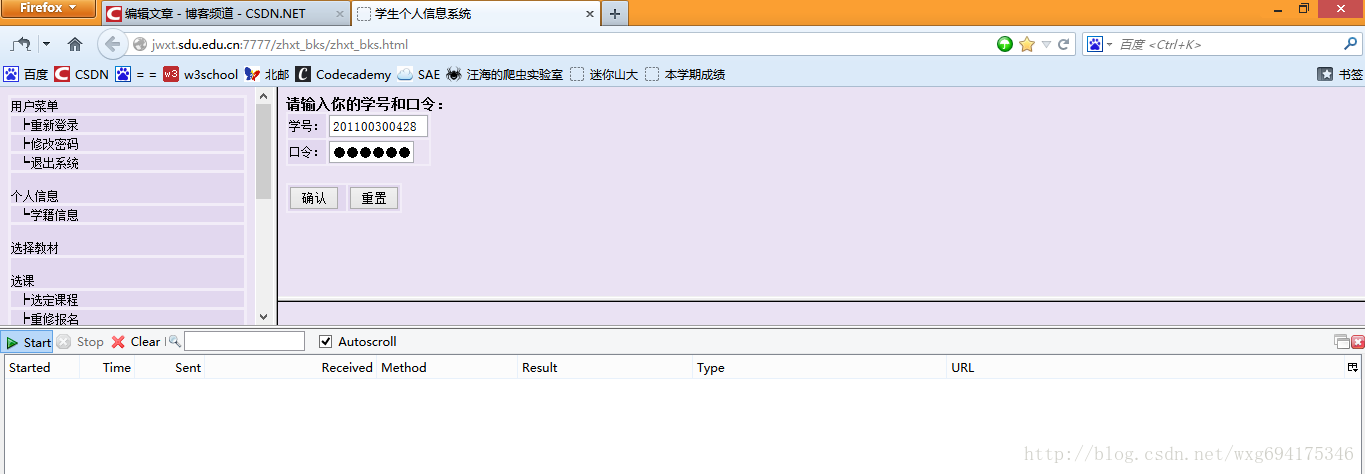
输入完了个人信息,确保httpfox处于开启状态,然后点击确定提交信息,实现登录。
这个时候可以看到,httpfox检测到了三条信息:
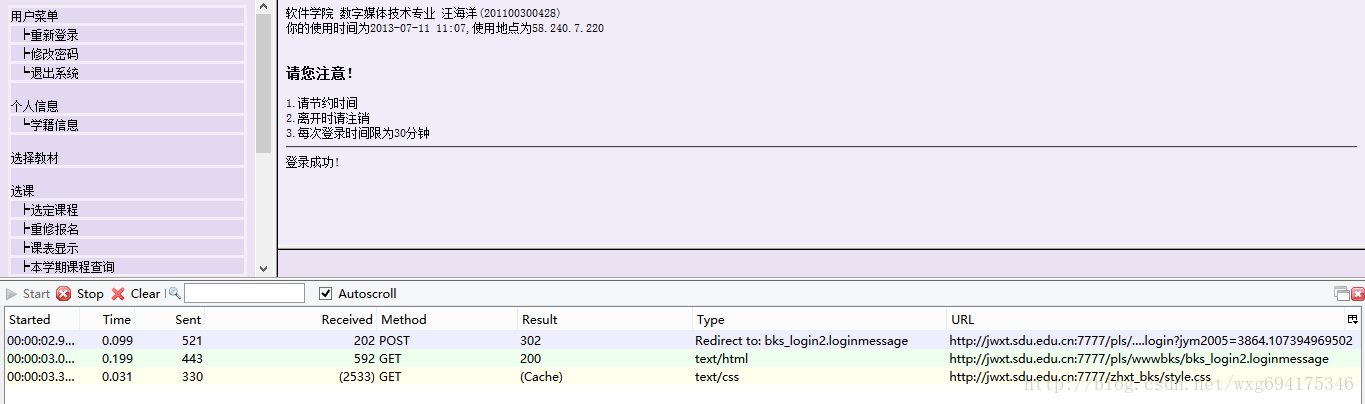
这时点击stop键,确保捕获到的是访问该页面之后反馈的数据,以便我们做爬虫的时候模拟登陆使用。
3.庖丁解牛
乍一看我们拿到了三个数据,两个是GET的一个是POST的,但是它们到底是什么,应该怎么用,我们还一无所知。
所以,我们需要挨个查看一下捕获到的内容。
先看POST的信息:
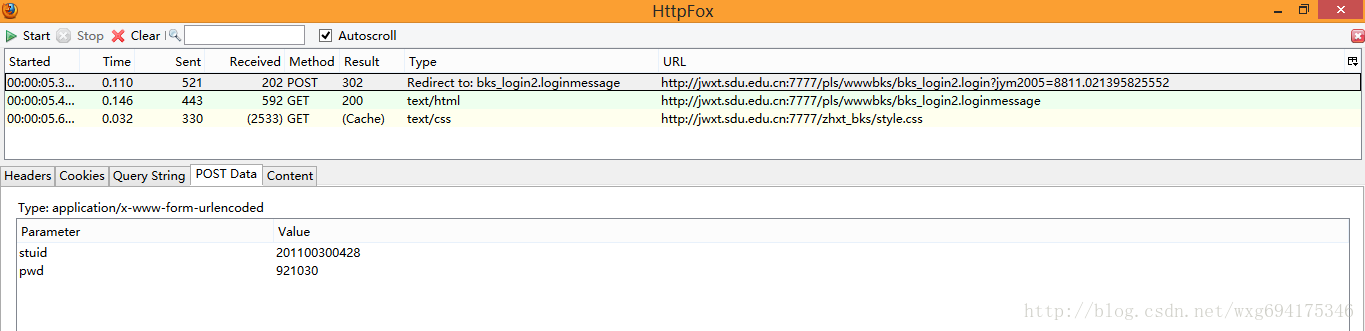
既然是POST的信息,我们就直接看PostData即可。
可以看到一共POST两个数据,stuid和pwd。
并且从Type的Redirect to可以看出,POST完毕之后跳转到了bks_login2.loginmessage页面。</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















:一个爬虫的诞生全过程(以山东大学绩点运算为例)&spm=1001.2101.3001.5002&articleId=9305229&d=1&t=3&u=e305f6743b6346b0aa4ce85b91944d5b)










 到【灌水乐园】发言
到【灌水乐园】发言







