







摘要:隐藏模型称为推荐系统的默认选择,因为他们的好表现以及可拓展性。然而,在此领域的调查主要关注在建模user-item之间的交互,很少隐藏模型为冷启动专门设计。受深度学习启发,提出了基于隐藏模型的神经网络称为DropoutNet来解决推荐系统中冷启动问题。不像现存方法其嵌入额外的基于内容的目标项,我们关注在优化上并展示神经网络模型可以为冷启动有效训练通过dropout.
1 简介
一个通常方法来建立精确推荐模型是协同过滤(collaborative filtering)CF是基于从其他用户得到的偏好信息来对个人偏好做出预测。现存的CF方法主要分成两类:基于近邻和基于模型。基于模型方法特别是隐藏模型是更好的选择,因为它为数据建立更紧密的表达。这些表达为快速检索优化,并能拓展到处理上百万用户。因为这些原因,我们本文关注隐藏方法。隐藏模型是典型地通过应用各种低秩近似来目标偏好矩阵来学习得到。当有很多偏好信息可用时它们表现很好,但在高度稀疏设定下就开始退化。极端稀疏的例子称为冷启动,当对给定的用户或者项目没有偏好信息可用。在这个例子中,唯一方式一个个性化推荐可以通过嵌入额外内容信息来生成推荐。基于隐藏方法不能嵌入内容,所以一堆混合模型被提出【3,21,22】去结合偏好和内容信息。然而大多数混合方法引入了额外目标项并发的学习和推断。并且目标的内容部分是生成式的,强迫模型去解释内容而不是使用内容去最大化推荐精度。
深度神经网络可以不需要特征工程而达到很好的精度,这些结果显示深度学习应该可以有效利用到为推荐系统建模内容。已有使用深度学习应用到CF中【7,22,6,23】很少的调查关于深度学习去解决冷启动问题。
本文提出的模型就是去解决这个间隙。方法是基于冷启动等于缺失数据问题的观察,其中偏好信息是缺失的。隐藏不去使用额外目标项去建模内容,我们协整学习过程去精确为缺失输入决定condition模型。关键的思想:通过应用dropout到输入的mini-batch中,训练DNN去泛化缺失的输入。通过选择一个合适的dropout量我们显示学习基于DNN的隐藏模型是可能的,其表现和热启动相当甚至更好。结果模型比大多数混合方法更简单,使用单个目标函数,共同优化所有成分去最大化推荐精度。
本方法额外优势在于它可以被应用到任何现存的隐藏模型去提供/增强冷启动能力。
2框架
在典型CF问题中有N个用户
U={u1,...,uN}
和M个项目
V={v1,...,vM}
,用户对于项目的反馈可以表示为
N×M
的偏好矩阵R,其中
Ruv
表示用户u对项目v的偏好程度,可以表示为rating,或者喜欢/不喜欢等等,或者通过暗含的互动推断例如观看,播放,购买等行为。精确设定R中包含分等级的相关性(例如1-5的打分),然而在暗含设定R经常是二元的;本文同时考虑这两种情况。当没有偏好信息可用时
Ruv=0
,使用
U(v)={u∈U|Ruv≠0}
表示对v表达了偏好的用户,
V(u)={v∈V|Ruv≠0}
表示u表达偏好的项目。在冷启动中没有偏好信息可用我们定义
V(u)=∅,U(v)=∅
。
在许多领域中我们经常能得到用户和项目的额外信息。对于项目,这个信息可以来自文本、音频、图像形式。对用户我们得到轮廓信息(年龄,性别,位置,设备等等),和社交媒体数据(Facebook)这数据可以提供高度有用的符号对于推荐模型,并在稀疏和冷启动设定中特别有用。应用相关转化后大多数内容信息可以由固定长度特征向量表示。我们使用
ΦU,ΦV
分别表示对于用户和项目的内容特征,其中
ΦUu
表示对于用户u的内容特征向量。当内容缺失时向量等于0。目标是和内容
ΦU,ΦV
特征和偏好信息R一起,学习精确和鲁棒的推荐模型。
3相关工作
大量混合隐藏方法被提出去解决CF中冷启动的问题。一个流行的模型是协同话题回归(collaborative topic regression)CTR【21】,其结合了Latent dirichlet allocation(LDA)【4】和加权矩阵分解(WMF)【13】。CTR插入LDA表达在冷启动中和WMF当偏好可用时,最近一些隐藏方法被提出。协同话题泊松分解CTPF【8】使用相似的插入架构但使用泊松分解【9】代替了LDA和WMF成分。协同深度学习collaborative deep learning(CDL)[22]是另一种方法使用类似架构,其中使用堆积的降噪自编码代替LDA。
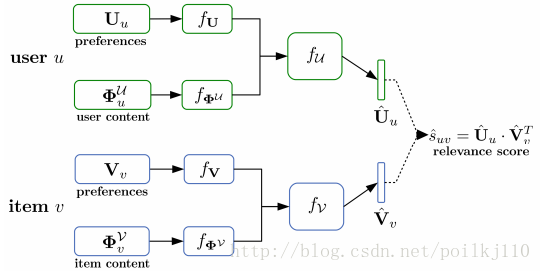
图1:Dropout架构图。对于每个用户u,其偏好
Uu
和内容
ΦUu
输入首先传到对应DNN
fU和fΦU
函数中。顶层激活值一起连接并传到fine-tuning 网络
fU
,其输出
Uu^
隐藏表达。项目也是相同的处理得到
Vv^
. 所有成分通过反向传播共同优化并在推断时保持固定。在新的隐藏空间使用
U^和V^
代替原始表达U和V表示检索完成。
这些模型完成较高的表现,他们也有一些共同的缺点。首先他们嵌入偏好和内容成分到目标函数,导致目标函数高度复杂。例如CDL,包含四个目标项并要求调试三个额外的结合权重到WMF和自编码参数。这使得在大数据上调试具有挑战性,其中每个参数设定都是昂贵和耗时的。第二每个模型的方差假设冷启动项不适用于冷启动用户。。大都数在线服务不许频繁增加新用户和项目,因此要求模型同时能处理。原则上推导类似模型杜宇用户和模型共同优化是可行的。一个主要的问题是我们旨在解决的问题是我们是否开发一个简单的冷启动模型,其可应用到用户和项目?
除了CDL, 一堆方法为CF被提出使用DNN。一个早期的方法DeepMusic【7】旨在通过一个隐藏模型使用内容只有DNN来预测隐藏表达。最近【6】描述了Youtube的两级推荐模型,利用用户的session(最近的play和搜索)和轮廓信息(profile information)作为输入的推荐系统。对于项目的隐藏表达在一个给定session中平均化,连接轮廓信息,并传到DNN输出一个依赖于session的隐藏表达。平均项目解决变长的输入问题,但会丢失session的时间信息。为了更精确建模用户的偏好是如何改变的,一个循环神经网络RNN方法被提出【23】。RNN被应用到一次一个项目的序列化,并所有项目之后被处理,隐藏层激活值被用作隐藏表达。
许多这些模型显示使用深度架构到CF的好处。然而,很少调查冷启动和稀疏设定表达当内容信息可用。我们希望深度学习在这些场景中是最有用的,因为它很好的泛化到不同内容类型。我们提出的方法旨在利用这个优点,很像【6】。我们也使用隐藏表达作为偏好特征输入对于用户和项目,并使用内容结合它们,去训练一个混合基于DNN 模型。不像[6]其主要关注在热启动用户,我们开发类似的模型对于用户和项目,并显示如何这些模型可以训练去精确处理冷启动。
4 方法
从输入表达开始,我们旨在开发一个模型其能够处理冷和热启动场景。结果是,输入到模型需要包含内容和偏好信息。一个选择是直接使用R的行和列以它们原来的形式。然而,当用户和项目量增多时矩阵会变大。我们采用类似【6】和【23】的方法,使用隐藏表达作为偏好输入。隐藏模型近似偏好矩阵使用低秩矩阵U和V的乘积:
其中 Uu和Vv 是对于用户u和项目v的隐藏表达。U和V都是密集并且低维的,其秩 D≪min(N,M) . 隐藏方法的强表现在大范围CF数据集中,充分假设隐藏表达精确地总结关于用户和项目的偏好信息。并且低维输入明显减少模型复杂度,当第一个隐藏层大小直接相关于输入大小。我们设定输入为 [Uu,ΦUu] 和 [Vu,ΦVv] .
4.1 模型架构
给定通过偏好-内容输入我们提出去应用DNN模型去映射到新的隐藏空间其嵌入内容和偏好信息。偏好 Uu 和内容 ΦUu 输入是第一次传输到对应DNN的 fU 和 fΦU .顶层激活值连接到一起并输入到一个微调网络 fU 其输出隐藏表达 Uu^ .items类似。














 1438
1438











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









