其它资料:
http://blog.chinaunix.net/uid-26575352-id-3480687.html
http://blog.csdn.net/zhoukuanbin/article/details/51578538
以下转自:http://blog.csdn.net/zengraoli/article/details/9397853
1、先来看一下Xapian的介绍:
Xapian的官方网站是http://www.xapian.org,这是一个非常优秀的开源搜索引擎项目,搜索引擎其实只是一个通俗的说法,正式的说法其实是IR(Information Retrieval)系统。Xapian的License是GPL,这意味着允许使用者自由地修改其源码并发布之。Xapian的中文资料非常少,可以说现在互联网上连一篇完整详细的Xapian中文介绍文档,更别说中文API文档了。
Xapian由C++编写,但可以绑定到Perl, Python, PHP, Java, Tcl, C# 和Ruby甚至更多的语言,Xapian可以说是STL编程的典范,在这里您可以找到熟悉的引用计数型智能指针、容器和迭代器,甚至连命名也跟STL相似,相信一定能引起喜好C++和STL的你的共鸣(实际上,很少C++程序员完全不使用STL)。
注:
更详细的介绍请参考:http://www.162cm.com/p/xapian-learning.html
自己编译参考请参考:http://blog.csdn.net/visualcatsharp/article/details/4096639
当然你也可以直接下载我自己编译的版本:(包含在测试项目中,下载地址:)
http://download.csdn.net/detail/zengraoli/5791047
二、使用Xapian的一个例子(神马介绍都是浮云,能用起来才是王道)
-
-
-
- #include "../xapian.h"
- #include <iostream>
- using namespace std;
-
-
- #pragma comment(lib, "ws2_32.lib")
- #pragma comment(lib, "../xapian-lib/zdll.lib")
- #pragma comment(lib, "../xapian-lib/libapi.lib")
- #pragma comment(lib, "../xapian-lib/libapi.lib")
- #pragma comment(lib, "../xapian-lib/libbackend.lib")
- #pragma comment(lib, "../xapian-lib/libcommon.lib")
- #pragma comment(lib, "../xapian-lib/libexpand.lib")
- #pragma comment(lib, "../xapian-lib/libflint.lib")
- #pragma comment(lib, "../xapian-lib/libflintbtreecheck.lib")
- #pragma comment(lib, "../xapian-lib/libinmemory.lib")
- #pragma comment(lib, "../xapian-lib/liblanguages.lib")
- #pragma comment(lib, "../xapian-lib/libmatcher.lib")
- #pragma comment(lib, "../xapian-lib/libmulti.lib")
- #pragma comment(lib, "../xapian-lib/libnet.lib")
- #pragma comment(lib, "../xapian-lib/libquartz.lib")
- #pragma comment(lib, "../xapian-lib/libquartzbtreecheck.lib")
- #pragma comment(lib, "../xapian-lib/libqueryparser.lib")
- #pragma comment(lib, "../xapian-lib/libremote.lib")
- #pragma comment(lib, "../xapian-lib/libtest.lib")
- #pragma comment(lib, "../xapian-lib/libunicode.lib")
-
-
- #define INDEX_PATH "..\\index_data"
-
-
- int main(int argc, char **argv)
- {
- try
- {
-
- Xapian::WritableDatabase db(INDEX_PATH, Xapian::DB_CREATE_OR_OPEN);
-
- Xapian::TermGenerator indexer;
- string para;
- int flag = 0;
- while (flag++ < 8)
- {
- string line;
- if (cin.eof())
- {
- if (para.empty()) break;
- }
- else
- {
- getline(cin, line);
- }
- if (line.empty())
- {
- if (!para.empty())
- {
-
- Xapian::Document doc;
- doc.set_data(para);
-
- indexer.set_document(doc);
- indexer.index_text(para);
-
-
- db.add_document(doc);
- para.resize(0);
- }
- }
- else
- {
- if (!para.empty()) para += ' ';
- para += line;
- }
- }
-
- db.flush();
- }
- catch (const Xapian::Error &e)
- {
- cout << e.get_description() << endl;
- exit(1);
- }
- }
说说上面程序核心部分的意思:
以DB_CREATE_OR_OPEN方式打开INDEX_PATH路径下的数据库(这种方式是,不存在则创建出来,存在就直接追加);
在Xapian中也有这样一个概念,所有的Xapian操作都是围绕数据库来的,在索引建立的时候,所有文档(Document)都会被放入数据库中
所以我们下一步是来创建文档:Xapian::Documentdoc;假如从控制台输入的数据不为空,那么para是有数据的(控制台通过判断当前输入是否为empty,即空行的情况),我们去设置这个文档的内容:doc.set_data(para);
这样我们的文档里边是存在内容的了,那么我们需要通过分词器去为我们识别每一个词indexer.set_document(doc);,用indexer.index_text(para);设置我们的索引text(对于这个函数的说明是这样的):
Xapian默认是通过判断空格来区分每一个词的,所以这么设置之后,假若文档中有N个空格,那么单词数就有N+1个。
最后一步,要把这个已经分好词的文档,放到数据库中db.add_document(doc);。
这样之后,我们的数据库就有数据了,这里我的输入是:
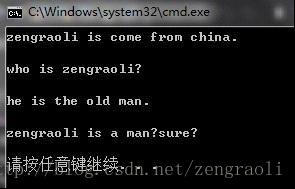
下面来看看,怎样对刚才数据库中的这几条语句,做检索:
-
-
-
- #include "stdafx.h"
- #include "../xapian.h"
- #include <iostream>
- using namespace std;
-
- #pragma comment(lib, "ws2_32.lib")
- #pragma comment(lib, "../xapian-lib/zdll.lib")
- #pragma comment(lib, "../xapian-lib/libapi.lib")
- #pragma comment(lib, "../xapian-lib/libapi.lib")
- #pragma comment(lib, "../xapian-lib/libbackend.lib")
- #pragma comment(lib, "../xapian-lib/libcommon.lib")
- #pragma comment(lib, "../xapian-lib/libexpand.lib")
- #pragma comment(lib, "../xapian-lib/libflint.lib")
- #pragma comment(lib, "../xapian-lib/libflintbtreecheck.lib")
- #pragma comment(lib, "../xapian-lib/libinmemory.lib")
- #pragma comment(lib, "../xapian-lib/liblanguages.lib")
- #pragma comment(lib, "../xapian-lib/libmatcher.lib")
- #pragma comment(lib, "../xapian-lib/libmulti.lib")
- #pragma comment(lib, "../xapian-lib/libnet.lib")
- #pragma comment(lib, "../xapian-lib/libquartz.lib")
- #pragma comment(lib, "../xapian-lib/libquartzbtreecheck.lib")
- #pragma comment(lib, "../xapian-lib/libqueryparser.lib")
- #pragma comment(lib, "../xapian-lib/libremote.lib")
- #pragma comment(lib, "../xapian-lib/libtest.lib")
- #pragma comment(lib, "../xapian-lib/libunicode.lib")
-
-
- #define INDEX_PATH "..\\index_data"
-
-
- int main()
- {
- try
- {
-
- Xapian::Database db(INDEX_PATH);
-
-
- Xapian::Enquire enquire(db);
- string query_string("zengraoli");
- Xapian::QueryParser qp;
- qp.set_database(db);
- qp.set_stemming_strategy(Xapian::QueryParser::STEM_SOME);
-
- Xapian::Query query = qp.parse_query(query_string);
- cout << "Parsed query is: " << query.get_description() << endl;
-
- enquire.set_query(query);
-
- Xapian::MSet matches = enquire.get_mset(0, 10);
-
- cout << matches.get_matches_estimated() << " results found.\n";
- cout << "Matches 1-" << matches.size() << ":\n" << endl;
-
- for (Xapian::MSetIterator i = matches.begin(); i != matches.end(); ++i)
- {
- cout << i.get_rank() + 1 << ": " << i.get_percent() << "% docid=" << *i
- << " [" << i.get_document().get_data() << "]\n\n";
- }
- }
- catch (const Xapian::Error &e)
- {
- cout << e.get_description() << endl;
- exit(1);
- }
- return 0;
-
- }
search程序核心部分:
首先打开数据库,生成一个临时会话(相当于数据库连接中的一条管道),设置我要查询的单词(这里是“zengraoli”);
再来生成一个查询分析器,设置查询分析器中对应的数据库(db),设置它的返回策略(这里选择的是部分:Xapian::QueryParser::STEM_SOME);
设置查询条件,也就是上面的单词;
输出我们的查询条件看看:query.get_description();
在刚才的临时会话(管道)中,设置我们上面的查询条件;
Xapian::MSet matches用来得到从数据库中返回的所以匹配的条目;
matches.get_matches_estimated()、matches.size()分别是显示出匹配的条目和大小;
我们需要一个迭代器,从匹配的条目中,逐个输出到控制台中:
- for (Xapian::MSetIterator i = matches.begin(); i != matches.end(); ++i)
- {
- cout << i.get_rank() + 1 << ": " << i.get_percent() << "% docid=" << *i
- << " [" << i.get_document().get_data() << "]\n\n";
- }
i.get_rank()从0开始,我们必须+1,才能和使用者的三观保持一致。i.get_percent()是匹配条目的相似度(在这里是按所占文档的权重排列)的信息,;i.get_document().get_data()返回含有匹配单词的文档内容。
好了,下面我们看看结果:
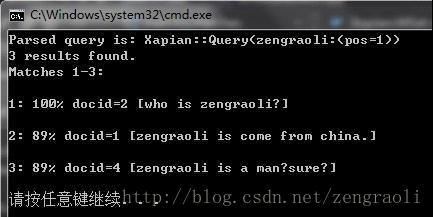
测试数据,在这里是很少的,仅仅有四条doc;
可以的话,下次测试多一些的数据,看看速度如何。
整个测试项目下载地址:
http://download.csdn.net/detail/zengraoli/5791047






















 1203
1203











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









