






计算机只能处理数字。如果要处理文本,就必须先把文本转换为数字才能处理。
最早的计算机在设计时采用8个比特(bit)作为一个字节(byte),所以,一个字节能表示的最大的整数就是255。
ASCII : 0- 255被用来表示大小写英文字母、数字和一些符号,这个编码表被称为ASCII 编码,比如大写字母 A 的编码是65,小写字母 z 的编码是122。
GB2312 :如果要表示中文,显然一个字节是不够的,至少需要两个字节,而且还不能和ASCII编码冲突,所以,中国制定了GB2312 编码,用来把中文编进去。
Unicode就是把所有语言都统一到一套编码里。
Unicode通常用两个字节表示一个字符,原有的英文编码从单字节变成双字节,只需要把高字节全部填为0就可以。
因为Python的诞生比Unicode标准发布的时间还要早,所以最早的Python只支持ASCII编码,普通的字符串’ABC’在Python内部都是ASCII编码的。
Unicode字符串
Python在后来添加了对Unicode的支持,以Unicode表示的字符串用u’…’表示,比如:
# -*- coding: utf-8 -*-
print u'中文'#Unicode字符串
print u'中文\n日文\n韩文'#转义在Unicode字符串中仍然有效
print u'''静夜思
窗前明月光,
疑是地上霜。
举头望明月,
低头思故乡。'''
print ur'''Python的Unicode字符串支持"中文",
"日文",
"韩文"等多种语言'''注1:添加# -- coding: utf-8 --,是为了让Python在处理字符串时使用中文处理器。
# -*- coding: utf-8 -*-注2:Unicode字符串格式
u'*******'注3:多行输出格式
u'''********
*******
******'''raw字符串
raw字符串表示对字符不需要转义,直接输出。
单行输出:
r'*******'print r'>_<'多行输出:
r'''**********
**********
**********''' 注1:raw字符串中不能包含\n , \’等转义字符。
例:请把下面的字符串用r”’…”’的形式改写,并用print打印出来:
‘\”To be, or not to be\”: that is the question.\nWhether it\’s nobler in the mind to suffer.’
print r'''"To be, or not to be ": that is the question.
Whether it's nobler in the mind to suffer.'''print u'''\"To be, or not to be\": that is the question.\nWhether it\'s nobler in the mind to suffer.'''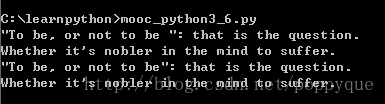














 876
876











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









