







0.下载安装IDEA
1.安装Scala插件
2.新建工程
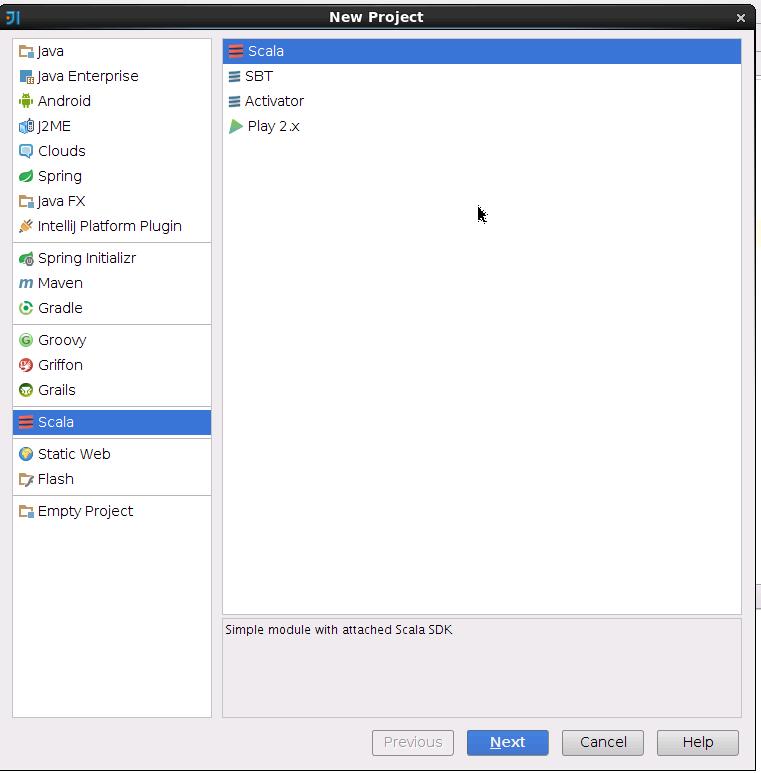
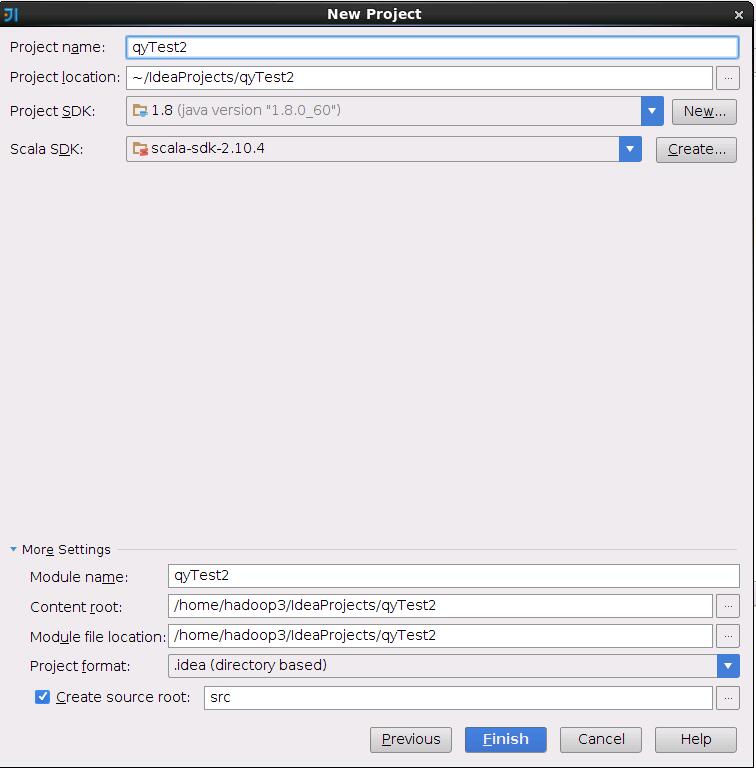
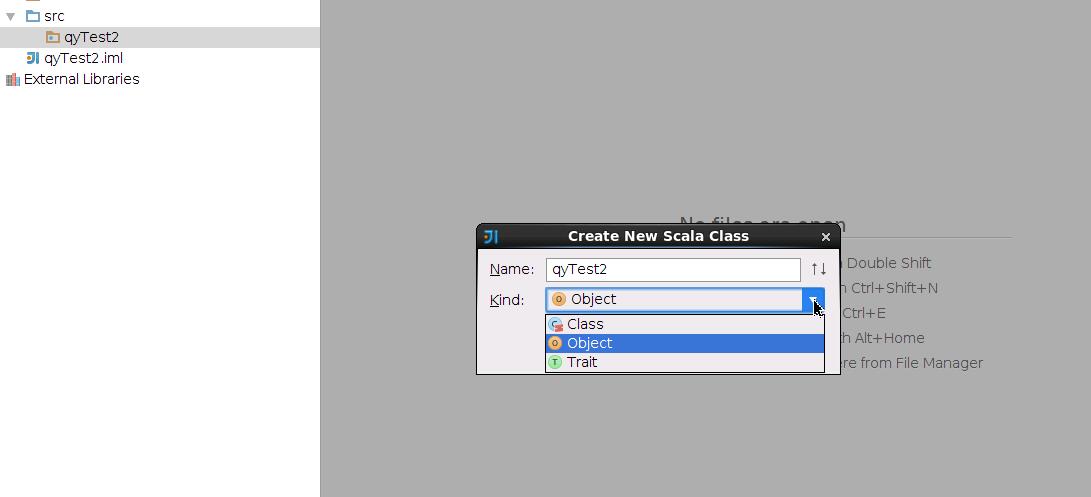
打开新工程后,在src文件夹下新建一个文件夹,名为qyTest2,在里面新建一个scala class,把class的类型改为object。
3.设置Project Structure
打开File-》Project Structure -》Libraries
加入新的lib(new project lib->java),选择Spark目录下的lib文件夹,
选择spark-assembly…..jar
再添加hbase目录下的lib文件夹
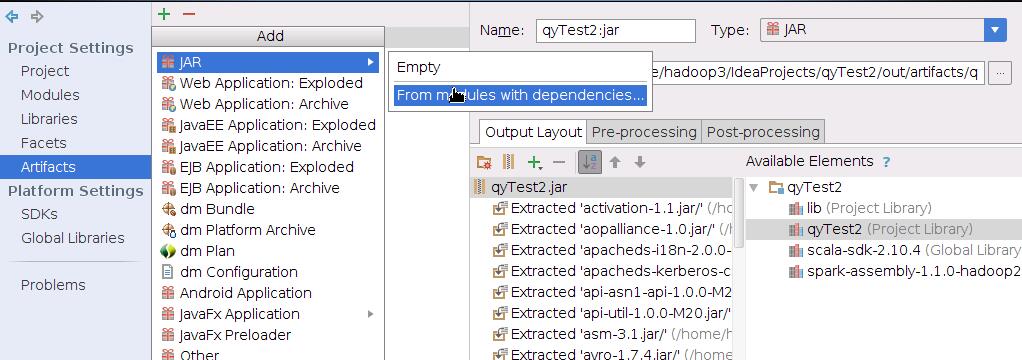
在File-》Project Structure-》Artifacts下添加jar包
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









