







通过程序自动的读取其它网站网页显示的信息,类似于爬虫程序。比方说我们有一个系统,要提取BaiDu网站上歌曲搜索排名。分析系统在根据得到的数据进行数据分析。为业务提供参考数据。
为了完成以上的需求,我们就需要模拟浏览器浏览网页,得到页面的数据在进行分析,最后把分析的结构,即整理好的数据写入数据库。那么我们的思路就是:
1、发送HttpRequest请求。
2、接收HttpResponse返回的结果。得到特定页面的html源文件。
3、取出包含数据的那一部分源码。
4、根据html源码生成HtmlDocument,循环取出数据。
5、写入数据库。
程序如下:
//根据Url地址得到网页的html源码
private string GetWebContent(string Url)
{
string strResult="";
try
{
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(Url);
//声明一个HttpWebRequest请求
request.Timeout = 30000;
//设置连接超时时间
request.Headers.Set("Pragma", "no-cache");
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
Stream streamReceive = response.GetResponseStream();
Encoding encoding = Encoding.GetEncoding("GB2312");
StreamReader streamReader = new StreamReader(streamReceive, encoding);
strResult = streamReader.ReadToEnd();
}
catch
{
MessageBox.Show("出错");
}
return strResult;
}
为了使用HttpWebRequest和HttpWebResponse,需填名字空间引用
using System.Net;
以下是程序具体实现过程:
private void button1_Click(object sender, EventArgs e)
{
//要抓取的URL地址
string Url = "http://list.mp3.baidu.com/topso/mp3topsong.html?id=1#top2";
//得到指定Url的源码
string strWebContent = GetWebContent(Url);
richTextBox1.Text = strWebContent;
//取出和数据有关的那段源码
int iBodyStart = strWebContent.IndexOf("<body", 0);
int iStart = strWebContent.IndexOf("歌曲TOP500", iBodyStart);
int iTableStart = strWebContent.IndexOf("<table", iStart);
int iTableEnd = strWebContent.IndexOf("</table>", iTableStart);
string strWeb = strWebContent.Substring(iTableStart, iTableEnd - iTableStart + 8);
//生成HtmlDocument
WebBrowser webb = new WebBrowser();
webb.Navigate("about:blank");
HtmlDocument htmldoc = webb.Document.OpenNew(true);
htmldoc.Write(strWeb);
HtmlElementCollection htmlTR = htmldoc.GetElementsByTagName("TR");
foreach (HtmlElement tr in htmlTR)
{
string strID = tr.GetElementsByTagName("TD")[0].InnerText;
string strName = SplitName(tr.GetElementsByTagName("TD")[1].InnerText, "MusicName");
string strSinger = SplitName(tr.GetElementsByTagName("TD")[1].InnerText, "Singer");
strID = strID.Replace(".", "");
//插入DataTable
AddLine(strID, strName, strSinger,"0");
string strID1 = tr.GetElementsByTagName("TD")[2].InnerText;
string strName1 = SplitName(tr.GetElementsByTagName("TD")[3].InnerText, "MusicName");
string strSinger1 = SplitName(tr.GetElementsByTagName("TD")[3].InnerText, "Singer");
//插入DataTable
strID1 = strID1.Replace(".", "");
AddLine(strID1, strName1, strSinger1,"0");
string strID2 = tr.GetElementsByTagName("TD")[4].InnerText;
string strName2 = SplitName(tr.GetElementsByTagName("TD")[5].InnerText, "MusicName");
string strSinger2 = SplitName(tr.GetElementsByTagName("TD")[5].InnerText, "Singer");
//插入DataTable
strID2 = strID2.Replace(".", "");
AddLine(strID2, strName2, strSinger2,"0");
}
//插入数据库
InsertData(dt);
dataGridView1.DataSource = dt.DefaultView;
}
程序运行结果界面图:
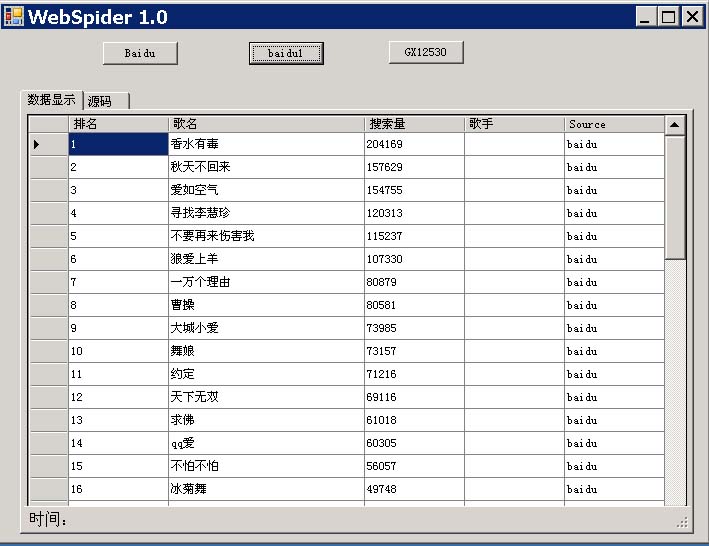
以上程序在VS.Net2005(C#),Windows 2003(sp1)平台上测试通过。














 654
654











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









