




 本文详细解析了MapReduce模型的核心概念,并介绍了常用的输入输出格式。通过实例展示了如何自定义输入输出方式,例如将Mongo数据作为输入源。同时,文章探讨了输入分片的控制与全文件处理的方法,提供了丰富的MapReduce编程实践指导。
本文详细解析了MapReduce模型的核心概念,并介绍了常用的输入输出格式。通过实例展示了如何自定义输入输出方式,例如将Mongo数据作为输入源。同时,文章探讨了输入分片的控制与全文件处理的方法,提供了丰富的MapReduce编程实践指导。
本篇通过对MapReduce模型的分析,加深对MapReduce模型的了解;并介绍MapReduc编程模型的常用输入格式和输出格式,在这些常用格式之外,我们可以扩展自己的输入格式,比如:如果我们需要把Mongo数据作为输入,可以通过扩展InputFormat、InputSplit的方式实现。
MapReduce模型深入了解
我们已经知道:map和reduce函数的输入和输出是键值对,下面,我们开始先对这个模型进行深入了解。首先,分析一个默认的MapReduce作业程序。
(1)一个最简单的MapReduce程序
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class MinimalMapReduce extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
JobConf conf = new JobConf(getConf(), getClass());
FileInputFormat.addInputPath(conf, new Path("/test/input/t"));
FileOutputFormat.setOutputPath(conf, new Path("/test/output/t"));
JobClient.runJob(conf);
return 0;
}
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(new MinimalMapReduce(), args);
System.exit(exitCode);
}
}(2)功能同上,默认值显示设置
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.MapRunner;
import org.apache.hadoop.mapred.TextInputFormat;
import org.apache.hadoop.mapred.TextOutputFormat;
import org.apache.hadoop.mapred.lib.HashPartitioner;
import org.apache.hadoop.mapred.lib.IdentityMapper;
import org.apache.hadoop.mapred.lib.IdentityReducer;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class MinimalMapReduceWithDefaults extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
JobConf conf = new JobConf(getConf(), getClass());
FileInputFormat.addInputPath(conf, new Path("/test/input/t"));
FileOutputFormat.setOutputPath(conf, new Path("/test/output/t"));
conf.setInputFormat(TextInputFormat.class);
conf.setNumMapTasks(1);
conf.setMapperClass(IdentityMapper.class);
conf.setMapRunnerClass(MapRunner.class);
conf.setMapOutputKeyClass(LongWritable.class);
conf.setMapOutputValueClass(Text.class);
conf.setPartitionerClass(HashPartitioner.class);
conf.setNumReduceTasks(1);
conf.setReducerClass(IdentityReducer.class);
conf.setOutputKeyClass(LongWritable.class);
conf.setOutputValueClass(Text.class);
conf.setOutputFormat(TextOutputFormat.class);
JobClient.runJob(conf);
return 0;
}
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(new MinimalMapReduceWithDefaults(), args);
System.exit(exitCode);
}
}
输入分片
一个输入分片(split)就是由单个map处理的输入块。
MapReduce应用开发人员不需要直接处理InputSplit,因为它是由InputFormat创建的。InputFormat 负责产生输入分片并将它们分割成记录。
如何控制分片的大小
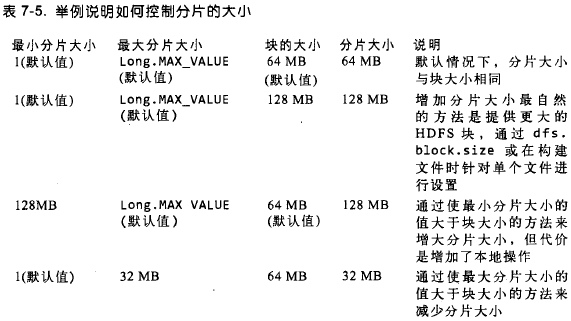
避免切分
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.mapred.TextInputFormat;
public class NoSplittableTextInputFormat extends TextInputFormat {
@Override
protected boolean isSplitable(FileSystem fs,Path file)
{
return false;
}
}
把整个文件作为一条记录处理
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileSplit;
import org.apache.hadoop.mapred.InputSplit;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.RecordReader;
import org.apache.hadoop.mapred.Reporter;
public class WholeFileInputFormat extends
FileInputFormat<NullWritable, BytesWritable> {
@Override
protected boolean isSplitable(FileSystem fs, Path file) {
return false;
}
@Override
public RecordReader<NullWritable, BytesWritable> getRecordReader(
InputSplit split, JobConf job, Reporter reporter)
throws IOException {
return new WholeFileRecordReader((FileSplit) split, job);
}
}
class WholeFileRecordReader implements
RecordReader<NullWritable, BytesWritable> {
private FileSplit fileSplit;
private Configuration conf;
private boolean processed = false;
public WholeFileRecordReader(FileSplit fileSplit, Configuration conf) {
this.fileSplit = fileSplit;
this.conf = conf;
}
@Override
public void close() throws IOException {
}
@Override
public NullWritable createKey() {
return NullWritable.get();
}
@Override
public BytesWritable createValue() {
return new BytesWritable();
}
@Override
public long getPos() throws IOException {
return processed ? fileSplit.getLength() : 0;
}
@Override
public float getProgress() throws IOException {
return processed ? 1.0f : 0.0f;
}
@Override
public boolean next(NullWritable key, BytesWritable value)
throws IOException {
if (!processed) {
byte[] contents = new byte[(int) fileSplit.getLength()];
Path file = fileSplit.getPath();
FileSystem fs = file.getFileSystem(conf);
FSDataInputStream in = null;
try {
in = fs.open(file);
IOUtils.readFully(in, contents, 0, contents.length);
value.set(contents, 0, contents.length);
} finally {
IOUtils.closeStream(in);
}
processed = true;
return true;
}
return false;
}
}输入格式
InputFormat类的层次结构
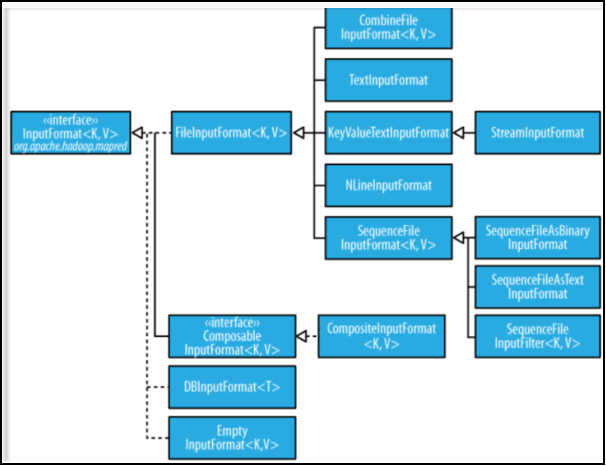
FileInputFormat类
FileInputFormat是所有使用文件作为数据源的InputFormat实现的基类,它提供了两个功能:一个定义哪些文件包含在一个作业的输入中;一个为输入文件生成分片的实现。把分片切割成记录的作业由其子类来完成。
TextInputFormat
TextInputFormat是默认的InputFormat。每条记录是一行输入。键是LongWritable类型,存储该行在整个文件中的字节偏移量。值是这行的内容,不包括终止符(换行符和回车符),它是Text类型的。
KeyValueTextInputFormat
通常情况下,文件张的每一行是一个键值对,使用某个分隔符进行分隔,比如制表符。可以通过key.value.separator.in.input.line属性来指定分隔符,它的默认值是一个制表符。
NLineInputFormat
如果希望Map收到固定行数的输入,需要使用NLineInputFormat。与 TextInputFormat一样,键是文件中 行的字节偏移量,值是行本身。mapred.line.input.format.linespermap属性控制N的值,默认是1。
二进制输入
SequenceFileInputFormat、SequenceFileAsTextInputFormat、SequenceFileAsBinaryInputFormat。
多种输入
多个输入,对于每个输入指定一个Mapper,当然,也可以多种输入格式而只有一个Mapper。
输出格式
OutputFormat类的层次结构
和输入对应,输出大约有如下几种类型:
文本输出、二进制输出、多个输出、延迟输出,数据库输出。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









