









是不是感觉很突兀,前面的博文还有讲异步 IO 来着。从现在开始,我们将步入网络编程的轨道了。但是又怕初学者难以适应(我也是初学者^_^),所以不能大张旗鼓的喊着,网络编程开始啦……另一方面,apue 这本书讲的网络编程只是一个入门,真正想学习网络编程基础的话,还需要去看 《Unix 网络编程》这本书,简称 unp。当然这本书的学习笔记也是在计划内的啦。不过在此之前,我们先简单的学习下一些基本的网络知识吧。
1. 字节序
这个东西要讲清楚不容易,先来看图 1.

图1 内存中的数据
假设图 1 中在内存 0x1000 到 0x1003 这连续的 4 个字节保存了数据,这段数据对应的数据类型是 int 类型。我们知道 int 类型的数据在大多数编译器实现中都是 4 字节。
那么图 1 中这个 int 类型数据,到底是 0x10203040 还是 0x40302010?实际上这是依赖于处理器架构的。
对于 little-endian (小端)机器来说,这 4 字节数据被解释成 int 类型的话它就是 0x10203040,对于 big-endian (大端)机器来说,它被解释成 0x40302010.
小端的意思就是说,数据的低位(低字节)保存在内存的低地址部分,数据的高位(高字节)保存在内存的高地址部分。按照这个规则,对于小端机器来说,高地址 0x1003 这个位置保存的是数据最高位,0x1000 这个地址保存的是数据的最低位,所以最终的 int 类型数据就是 0x10203040.
大部分情况下,我们的使用都是小端机器,Intel 处理器和 AMD 处理器基本上都是小端的。但是也有一些处理器是大端的。
2. 网络字节序
为了能让不同处理器架构的机器进行通信,他们都需要将本机上的字节序转换成网络字节序,这样就解决了不同处理器之间的矛盾。
一般来说,网络字节序和大端机器上的字节序是一样的。
POSIX 提供了 4 个函数(也可能是用宏来实现的),可以让本机字节序和网络字节序之间进行互转。它们分别是:
#include <arpa/inet.h>
uint32_t htonl(uint32_t hostlong);
uint16_t htons(uint16_t hostshort);
uint32_t ntohl(uint32_t netlong);
uint16_t ntohs(uint16_t netshort);其中,函数名字中的 h 表示 host(本机),n 表示 network(网络),而 l 表示要转换的数据是 4 字节,s 表示要转换的数据是 2 字节。
我们可通过实验来验证自己的机器是大端和小端的,另外网络字节序又是什么样的。
3. 实验
程序 btod.c 打印整型数据 0x10203040 在内存中的样子,然后将其转换成网络字节序后,再打印其在内存中的样子。
- 代码
#include <stdio.h>
#include <arpa/inet.h>
union Int {
char data[4];
int x;
};
int main() {
int i;
union Int a;
union Int b;
a.x = 0x10203040;
b.x = htonl(a.x);
printf("a = 0x%08x\n", a.x);
for (i = 0; i < 4; ++i) {
printf("[%p]: %02x\n", a.data + i, a.data[i]);
}
puts("");
printf("b = 0x%08x\n", b.x);
for (i = 0; i < 4; ++i) {
printf("[%p]: %02x\n", b.data + i, b.data[i]);
}
return 0;
}- 编译和运行
$ gcc btod.c -o btod
$ ./btod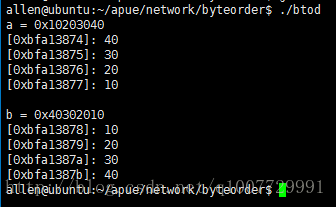
图1 运行结果
从图 1 中可以看到,0x10203040 在内存中的样子,低地址保存的是数据低字节,即 0x40,而高地址保存的是数据的高字节,即 0x10.
当我们将 0x10203040 转换成网络字节序后,在内存中的样子就完全相反了。
4. 总结
- 掌握小端和大端的区别
- 知道什么是字节序
- 为什么会出现网络字节序














 583
583











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









