







ElasticSearch是自带分词器的,但是自带的分词器一般就只能对英文分词,对英文的分词只要识别空格就好了,还是很好做的(ES的这个分词器和Lucene的分词器很想,是不是直接使用Lucene的就不知道),自带的分词器对于中文就只能分成一个字一个字,这个显然是不能满足在开发中的要求的。
先看看自带的分词器的分词效果(还是使用Sense工具):
POST /_analyze
{
"analyzer":"standard",
"text":"中华人民共和国国歌"
}得到的结果是下面这个:
{
"tokens": [
{
"token": "中",
"start_offset": 0,
"end_offset": 1,
"type": "<IDEOGRAPHIC>",
"position": 0
},
{
"token": "华",
"start_offset": 1,
"end_offset": 2,
"type": "<IDEOGRAPHIC>",
"position": 1
},
{
"token": "人",
"start_offset": 2,
"end_offset": 3,
"type": "<IDEOGRAPHIC>",
"position": 2
},
{
"token": "民",
"start_offset": 3,
"end_offset": 4,
"type": "<IDEOGRAPHIC>",
"position": 3
},
{
"token": "共",
"start_offset": 4,
"end_offset": 5,
"type": "<IDEOGRAPHIC>",
"position": 4
},
{
"token": "和",
"start_offset": 5,
"end_offset": 6,
"type": "<IDEOGRAPHIC>",
"position": 5
},
{
"token": "国",
"start_offset": 6,
"end_offset": 7,
"type": "<IDEOGRAPHIC>",
"position": 6
},
{
"token": "国",
"start_offset": 7,
"end_offset": 8,
"type": "<IDEOGRAPHIC>",
"position": 7
},
{
"token": "歌",
"start_offset": 8,
"end_offset": 9,
"type": "<IDEOGRAPHIC>",
"position": 8
}
]
}IK分词器的安装
在ES中,从资料来看好像都是使用IK分词器的,所以这篇博客配的也是IK分词器,有兴趣的同学可以自己去试试其他的分词器(我是用过的有MMSeg4j ,NPL,jieba)。
如果是在window下:
从这个地址上把项目clone下来或者直接下载zip下来
https://github.com/medcl/elasticsearch-analysis-ik拉下来的项目是maven项目的,需要电脑上已经安装了maven。主意下载下来的elasticsearch的版本要和你正在用的同一个版本,或者在pom.xml修改成对应的版本号:
<properties>
<!--Elasticsearch的版本号-->
<elasticsearch.version>5.5.0</elasticsearch.version>
<!--JDK的版本-->
<maven.compiler.target>1.8</maven.compiler.target>
<elasticsearch.assembly.descriptor>${project.basedir}/src/main/assemblies/plugin.xml</elasticsearch.assembly.descriptor>
<elasticsearch.plugin.name>analysis-ik</elasticsearch.plugin.name>
<elasticsearch.plugin.classname>org.elasticsearch.plugin.analysis.ik.AnalysisIkPlugin</elasticsearch.plugin.classname>
<elasticsearch.plugin.jvm>true</elasticsearch.plugin.jvm>
<tests.rest.load_packaged>false</tests.rest.load_packaged>
<skip.unit.tests>true</skip.unit.tests>
<gpg.keyname>4E899B30</gpg.keyname>
<gpg.useagent>true</gpg.useagent>
</properties>然后使用下面的命令打包一下项目:
mvn package如果成功的话会在target/releases下有一个zip压缩包elasticsearch-analysis-ik-5.5.0.zip
这个压缩包就是我们待会要用的。
注意到上面的pom.xml文件中使用的JDK1.8,如果电脑是之前安装的maven,而且恰好使用的JDK1.7的maven,mvn package是会报错的,这个使用需要找到maven下的setting文件,然后将JDK版本改成1.8之后,重新mvn package应该就可以了。
<profile>
<id>jdk-1.8</id>
<activation>
<activeByDefault>true</activeByDefault>
<jdk>1.8</jdk>
</activation>
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<maven.compiler.compilerVersion>1.8</maven.compiler.compilerVersion>
</properties>
</profile> 再注意,这个不能像之前修改像之前修改elasticsearch版本号一样,直接在pom.xml文件中将jdk改成1.7,因为项目中使用到了jdk1.8的新特性,这样修改之后项目本身会报错的。
如果还是无法使用mvn package打包项目的话,可以把项目拉进eclipse中,然后右键run–>maven install,可以达到同样的效果。
然后把刚刚得到的elasticsearch-analysis-ik-5.5.0.zip上传到服务器。需要把这个文件elasticsearch-5.5.0/plugins/ik这个路径下;
解压压缩包:
unzip elasticsearch-analysis-ik-5.5.0.zip到这一步基本上elasticsearch的ik分词器就安装好了。示例待会说,下面将一个可能遇到的问题:
如果服务器上没有安装unzip功能的话,可以使用下面的命令行安装
yum install -y unzip zip如果服务没有安装上传下载功能的,可以使用下面的方法安装
yum install -y lrzsz然后输入下面命令行就会弹出一个窗口,选择文件上传到服务器上就可以。
rz顺便说一下,使用下面的命令可以将服务器上的文件下载到本地。
sz XXX(下载的文件名)如果是在linux下:
之前的那些操作之所以在windows下完成是因为在linux环境下很多简单的操作都要输入很多命令行,如果有报错不容易调试,但是如果可以保证linux下的功能比较完整的话,服务器上起码安装了Git和maven的,可以直接在linux下完成这些功能的:
把项目从github克隆下来
git clone https://github.com/medcl/elasticsearch-analysis-ik.git如果需要修改elasticsearch版本的,修改一下版本号,然后打包项目
maven package而后把target/release下的压缩包移动到elasticsearch下plugins下解压就OK了。
接下来重启一下elasticsearch服务,如果出现下面的图片就基本上算是安装成功了。说明了elasticsearch就加载成功了。
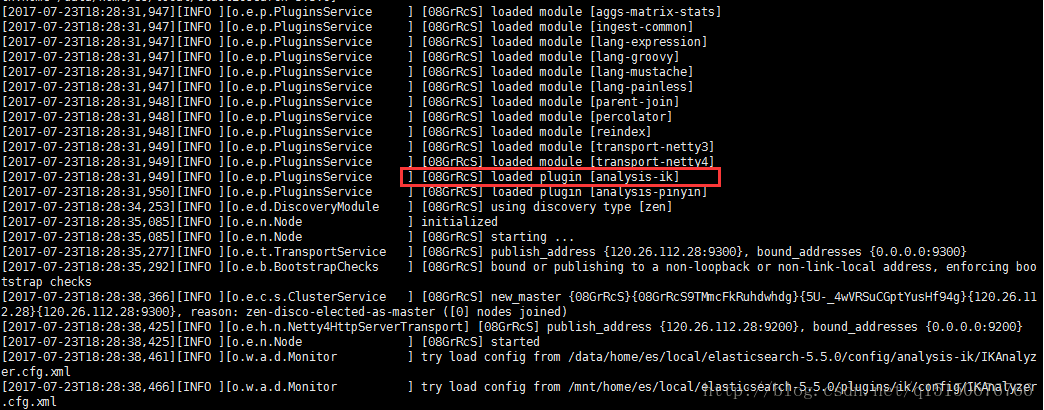
在sense中测试一下,IK中有两种分词器,一种是ik_max_word另一种是ik_smart,分别会最大粒度的分词和最小粒度的分词:
POST /_analyze
{
"analyzer":"ik_max_word",
"text":"中华人民共和国国歌"
}会得到
{
"tokens": [
{
"token": "中华人民共和国",
"start_offset": 0,
"end_offset": 7,
"type": "CN_WORD",
"position": 0
},
{
"token": "中华人民",
"start_offset": 0,
"end_offset": 4,
"type": "CN_WORD",
"position": 1
},
{
"token": "中华",
"start_offset": 0,
"end_offset": 2,
"type": "CN_WORD",
"position": 2
},
{
"token": "华人",
"start_offset": 1,
"end_offset": 3,
"type": "CN_WORD",
"position": 3
},
{
"token": "人民共和国",
"start_offset": 2,
"end_offset": 7,
"type": "CN_WORD",
"position": 4
},
{
"token": "人民",
"start_offset": 2,
"end_offset": 4,
"type": "CN_WORD",
"position": 5
},
{
"token": "共和国",
"start_offset": 4,
"end_offset": 7,
"type": "CN_WORD",
"position": 6
},
{
"token": "共和",
"start_offset": 4,
"end_offset": 6,
"type": "CN_WORD",
"position": 7
},
{
"token": "国",
"start_offset": 6,
"end_offset": 7,
"type": "CN_CHAR",
"position": 8
},
{
"token": "国歌",
"start_offset": 7,
"end_offset": 9,
"type": "CN_WORD",
"position": 9
}
]
}如果是
POST /_analyze
{
"analyzer":"ik_smart",
"text":"中华人民共和国国歌"
}会得到
{
"tokens": [
{
"token": "中华人民共和国",
"start_offset": 0,
"end_offset": 7,
"type": "CN_WORD",
"position": 0
},
{
"token": "国歌",
"start_offset": 7,
"end_offset": 9,
"type": "CN_WORD",
"position": 1
}
]
}基本上这样就把IK分词器安装成功了。
拼音分词器的安装
拼音分词器的安装和Ik的安装基本上是相同的
https://github.com/medcl/elasticsearch-analysis-pinyin讲项目拉下来,打包项目,将target/release下的压缩包移动到elasticsearch-5.5.0下的plugins下,重启一下elasticsearch就可以了。
测试一下:
POST /_analyze
{
"analyzer":"pinyin",
"text":"中华人民共和国国歌"
}得到
{
"tokens": [
{
"token": "zhong",
"start_offset": 0,
"end_offset": 1,
"type": "word",
"position": 0
},
{
"token": "zhrmghggg",
"start_offset": 0,
"end_offset": 9,
"type": "word",
"position": 0
},
{
"token": "hua",
"start_offset": 1,
"end_offset": 2,
"type": "word",
"position": 1
},
{
"token": "ren",
"start_offset": 2,
"end_offset": 3,
"type": "word",
"position": 2
},
{
"token": "min",
"start_offset": 3,
"end_offset": 4,
"type": "word",
"position": 3
},
{
"token": "gong",
"start_offset": 4,
"end_offset": 5,
"type": "word",
"position": 4
},
{
"token": "he",
"start_offset": 5,
"end_offset": 6,
"type": "word",
"position": 5
},
{
"token": "guo",
"start_offset": 6,
"end_offset": 7,
"type": "word",
"position": 6
},
{
"token": "guo",
"start_offset": 7,
"end_offset": 8,
"type": "word",
"position": 7
},
{
"token": "ge",
"start_offset": 8,
"end_offset": 9,
"type": "word",
"position": 8
}
]
}顺便说一下,在这些分词结果在处理的时候,就会被存进索引,搜索的时候,如果输入“国歌”,“guoge”,“zhrmghggg”,“中国人民共和国国歌”,那么中华人民共和国国歌就会被索引到。














 346
346











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









