







1.准备条件:
机器:centOS6.5(x64) ,安装方式百度吧!!!如果你已经安装过CentOS了,也可以参考本文章。
镜像名:centOS-6.5-X86_64-minimal.iso(下载地址:http://download.chinaunix.net/download.php?id=41334&ResourceID=13440)
JDK1.7下载地址:http://www.oracle.com/technetwork/java/javase/downloads/jdk7-downloads-1880260.html(rpm和tar.gz都可以,安装方式百度吧)
Hadoop版本:Hadoop-2.5.1_X64.tar.gz,这里提供2.7.x的版本(链接: http://pan.baidu.com/s/1dFdwyzv 密码: 9iwc)均是64为版本的,已经编译过的。官方下载的都是32bit的,需要下载对应的源码,在64位机器上进行编译。
网络配置参考:http://blog.csdn.net/q361239731/article/details/53180084
5台服务器全部装好jdk1.7+ssh+sshd+时间同步,node1-node5是对应机器的hostname
192.168.160.131 ( node1):作为Primary NameNode(制作了一个免密码ssh)
192.168.160.132 ( node2):作为Secondary NameNode
192.168.160.133 ( ndoe3):作为DataNode
192.168.160.134 ( ndoe4):作为DataNode
192.168.160.135 ( ndoe5):作为DataNode
JDK1.7(64bit,配置好环境变量)+SSH安装好+SSHD安装好
JDK:javac 或 java -version
SSH和SSHD在镜像中已经安装好了。
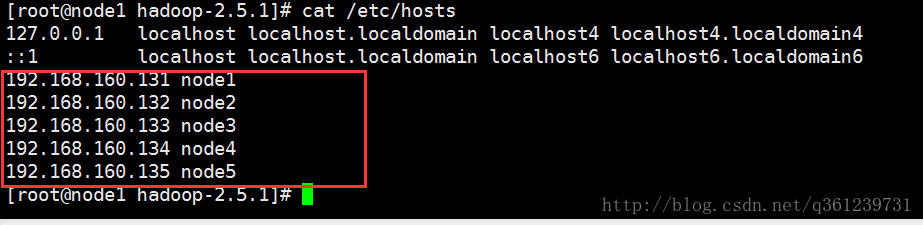
这里之所以使用node1 node2 …… node5是因为配置了hosts文件,同时将这个hosts文件通过spc命令拷贝到其他4台机器中去
scp /etc/hots root@node2:/etc/ && scp /etc/hots root@node3:/etc/ && scp /etc/hots root@node4:/etc/ && scp /etc/hots root@node5:/etc/


2、上传Hadoop-2.5.1_X64.tar.gz(利用源码在64位机器上编译过的tar包) 并解压,配置好环境变量。
- 如下图所示
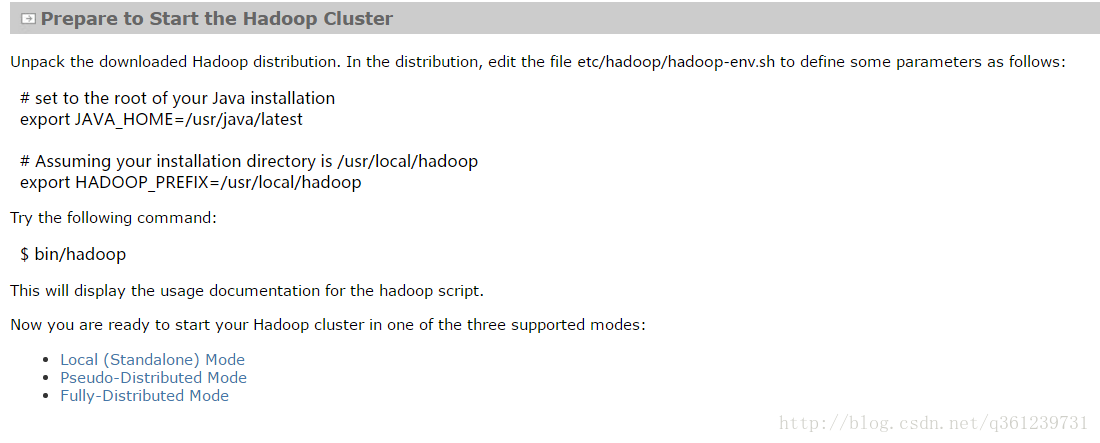
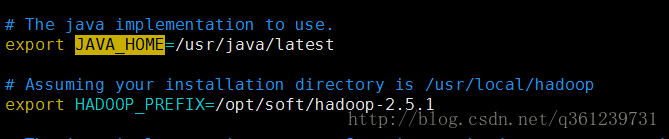
2.1、配置环境变量:etc/hadoop/hadoop-env.sh文件(hadoop文件夹下的etc目录) 之后修改JAVA_HOME并添加下列代码
# Assuming your installation directory is /usr/local/hadoop
export HADOOP_PREFIX=/usr/local/hadoop如下图:
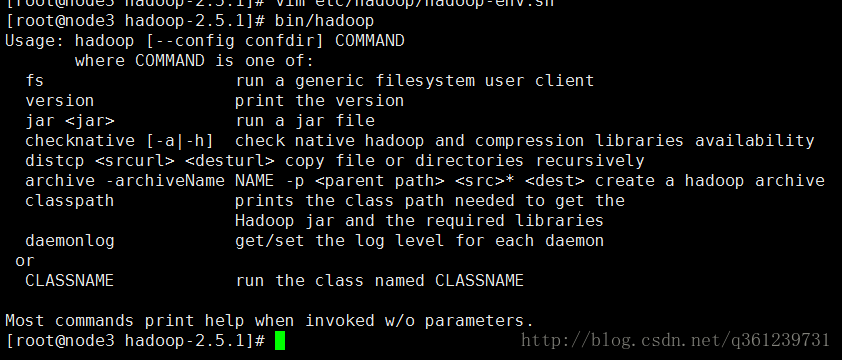
运行 bin/hadoop,出现下面信息表示已经安装好。
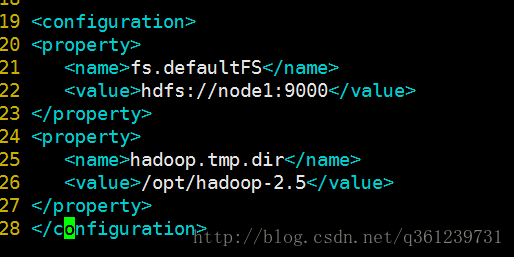
2.2、配置Primary NameNode地址:etc/hadoop/core-size.xml:设置文件上传下载的IP,即namenode的地址,这里选择node1
-
- 添加2个属性:
<property> <name>fs.defaultFS</name> <value>hdfs://node1:9000</value> </property> <!-- 设置hadoop临时文件的存放目录,这里设置为/opt/hadoop-2.5目录,不需要自己创建 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/hadoop-2.5</value> </property>
因为下面的2个配置,存放fsimage文件的目录与hadoop.tmp.dir相关联。所有需要设置hadoop.tmp.dir的存放目录在非tmp(系统重启就会丢失)目录。
官方给的说明如下表:
属性名 属性值 说明 hadoop.tmp.dir /tmp/hadoop-${user.name} A base for other temporary directories. dfs.namenode.name.dir file://${hadoop.tmp.dir}/dfs/name Determines where on the local filesystem the DFS name node should store the name table(fsimage). If this is a comma-delimited list of directories then the name table is replicated in all of the directories, for redundancy. - 添加2个属性:
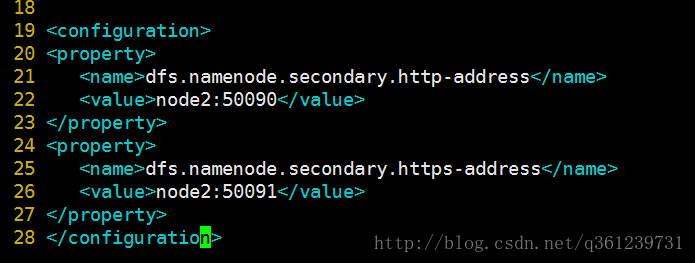
2.3、配置Secondary NameNode地址和端口:etc/hadoop/hdfs-site.xml:(配置这个是为了在web页面进行监控用的)
属性名 属性值 说明 dfs.namenode.secondary.http-address 0.0.0.0:50090 The secondary namenode http server address and port. dfs.namenode.secondary.https-address 0.0.0.0:50091 The secondary namenode HTTPS server address and port. 2.4、配置DataNode 地址: etc/hadoop/slaves
2.5、配置Secondary DataNode 地址: etc/hadoop/masters (自己手动创建)
[root@node1 hadoop]# vim masters
3、将node1下面的 hadoop-2.5.1目录 拷贝到其他4台机器中:
scp -r /opt/hadoop-2.5.1 root@node2:/opt &&
scp -r /opt/hadoop-2.5.1 root@node3:/opt &&
scp -r /opt/hadoop-2.5.1 root@node4:/opt &&
scp -r /opt/hadoop-2.5.1 root@node5:/opt
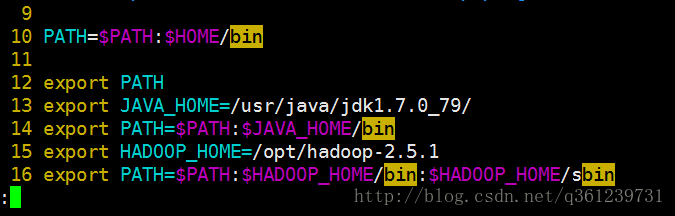
4、配置Hadoop环境变量:(环境变量还有好几个文件都可以设置如:/etc/profile)
vim ~/.bash_profile
配置好后,复制(同样适用scp命令)到其他4台机器中并应用配置。
source ~/.bash_profile5、启动之前,格式化hdfs文件系统: (只能在namenode机器上敲这条命令)
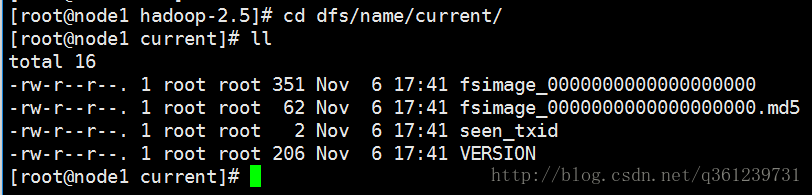
hdfs namenode -format这条命令做的事情是:前提是(保证5台机器的时间差在 ±30s)
创建了 /opt/hadoop-2.5目录,并在里面创建了 dfs/name/current目录和初始化fsimage文件
到此就配置完毕了
你都做了什么?
现在已经配置好了HDFS的基本骨架:
node1:namenode(Master)
node2:Secondary namenode
node3、node4、node5:datanode
下面进行一些异常处理
如果在执行 bin/hdfs namenode -format时出现下面错误
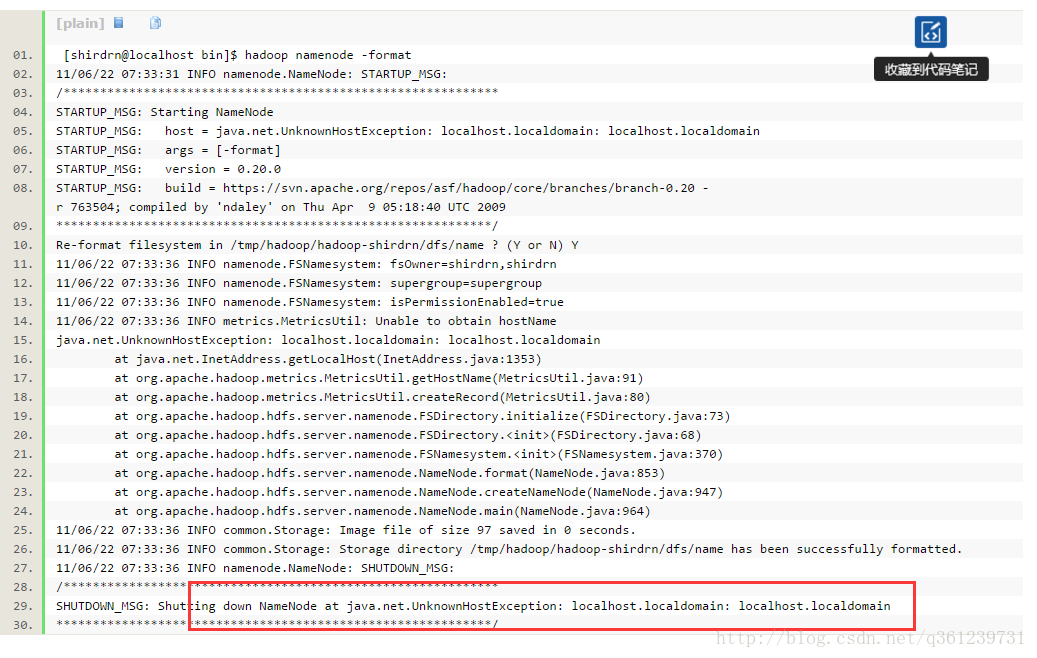
表示没有端口没有映射。可以修改/etc/hosts文件 加入下面的信息就可以了
下面开始启动了
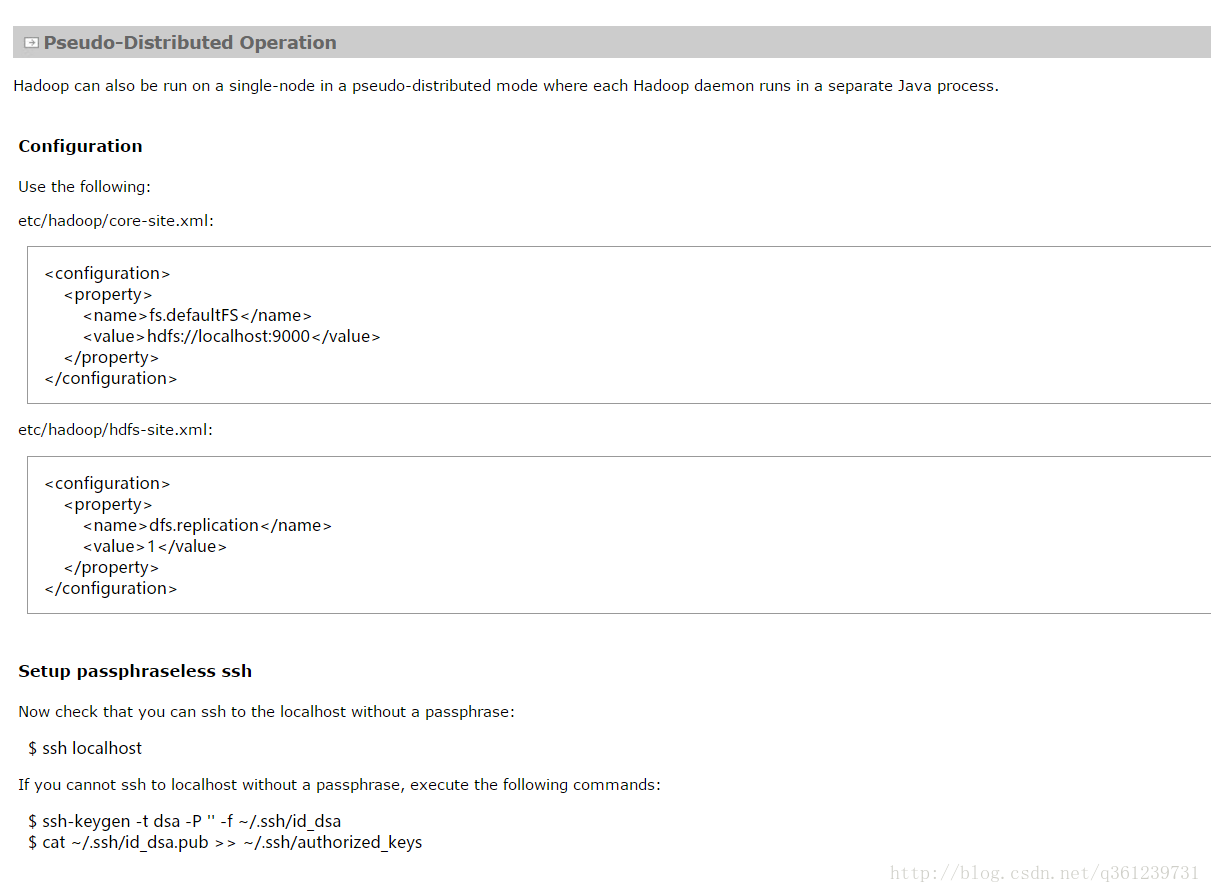
ssh登录不是必选项,但是如果不设置免密码登录的话,启动集群时,每台节点都要等待手动输入密码。但是为了方便还是做了吧。(注意时间同步,因为秘钥的生成用到了时间)
在node1中输入下面的命令
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys然后将node1中的公钥(在~/.ssh/id_dsa.pub)考到其他4台机器中(/opt目录下):
scp ~/.ssh/id_dsa.pub root@node2:/opt &&
scp ~/.ssh/id_dsa.pub root@node3:/opt &&
scp ~/.ssh/id_dsa.pub root@node4:/opt &&
scp ~/.ssh/id_dsa.pub root@node5:/opt然后在每台机器中将node1的公钥加入到认证文件中:
cat /opt/id_dsa.pub >> ~/.ssh/authorized_keys
测试的方法是:
在node1中,输入 ssh node2,如果不需要输入密码就表示成功了,否则在node1重新生成公钥和密钥(检查时间是否一致),重复上面的步骤。 如果能登录到node2中,就可以了,执行exit命令退出,然后ssh node3依次下去。
6、启动hdfs集群:
- 在保证node1能够免密码登录node2 node3 node4 node5(如果不能,就在ndoe1重新生成公钥,同时scp到其他机器中,同时执行cat /opt/id_dsa.pub >>~/.ssh/authorized_keys) 之后在node1中进行启动
start-dfs.sh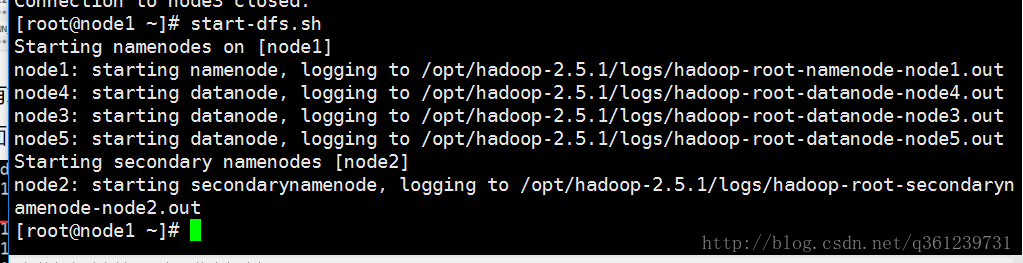
启动成功后:浏览器中输入node1:50070(50070为默认监控端口)进入监控页面:显示是active
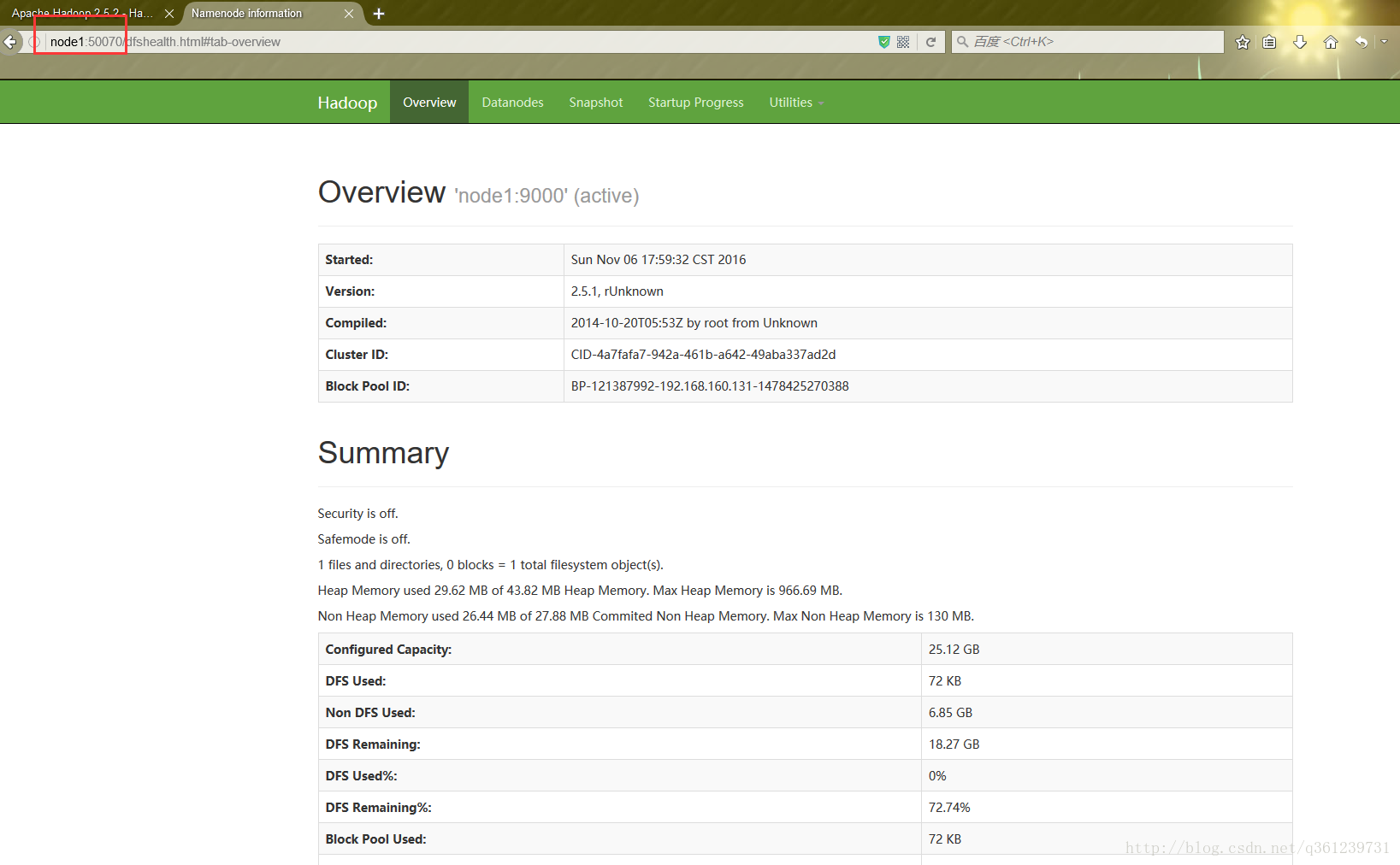
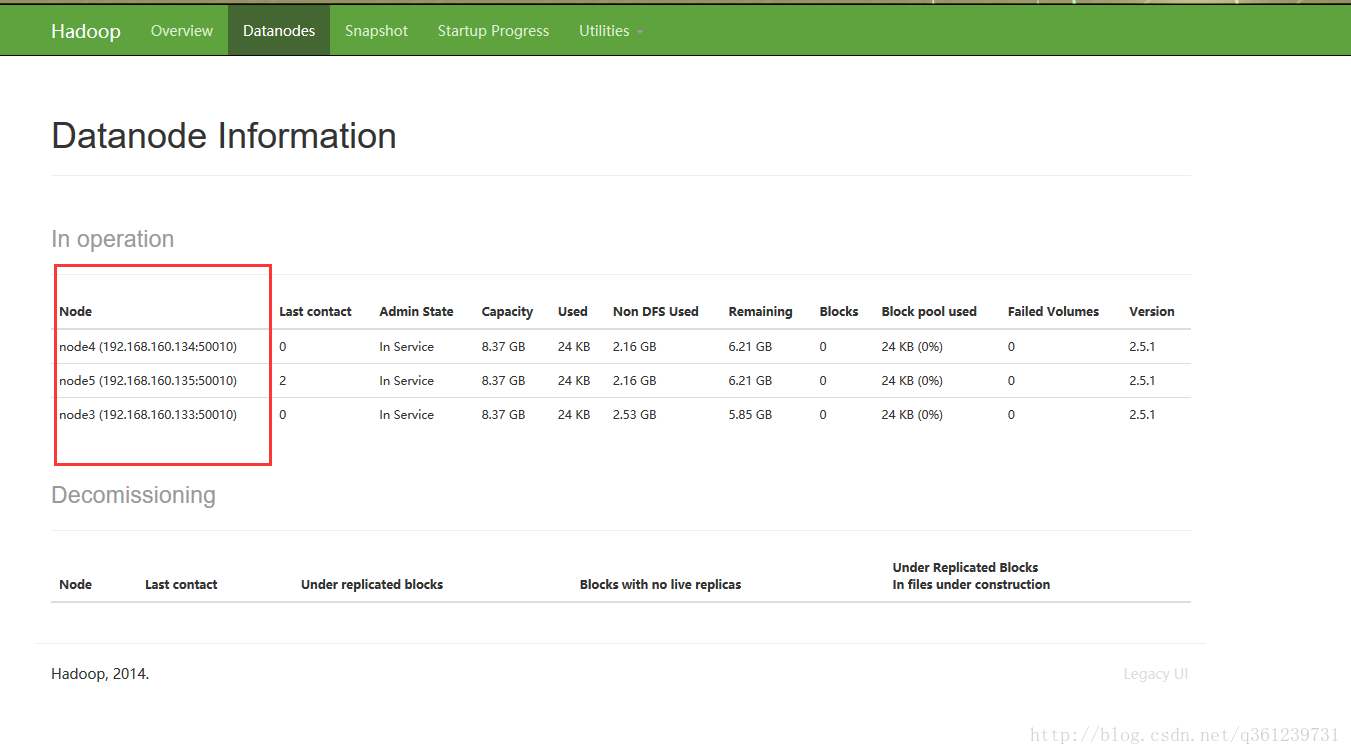
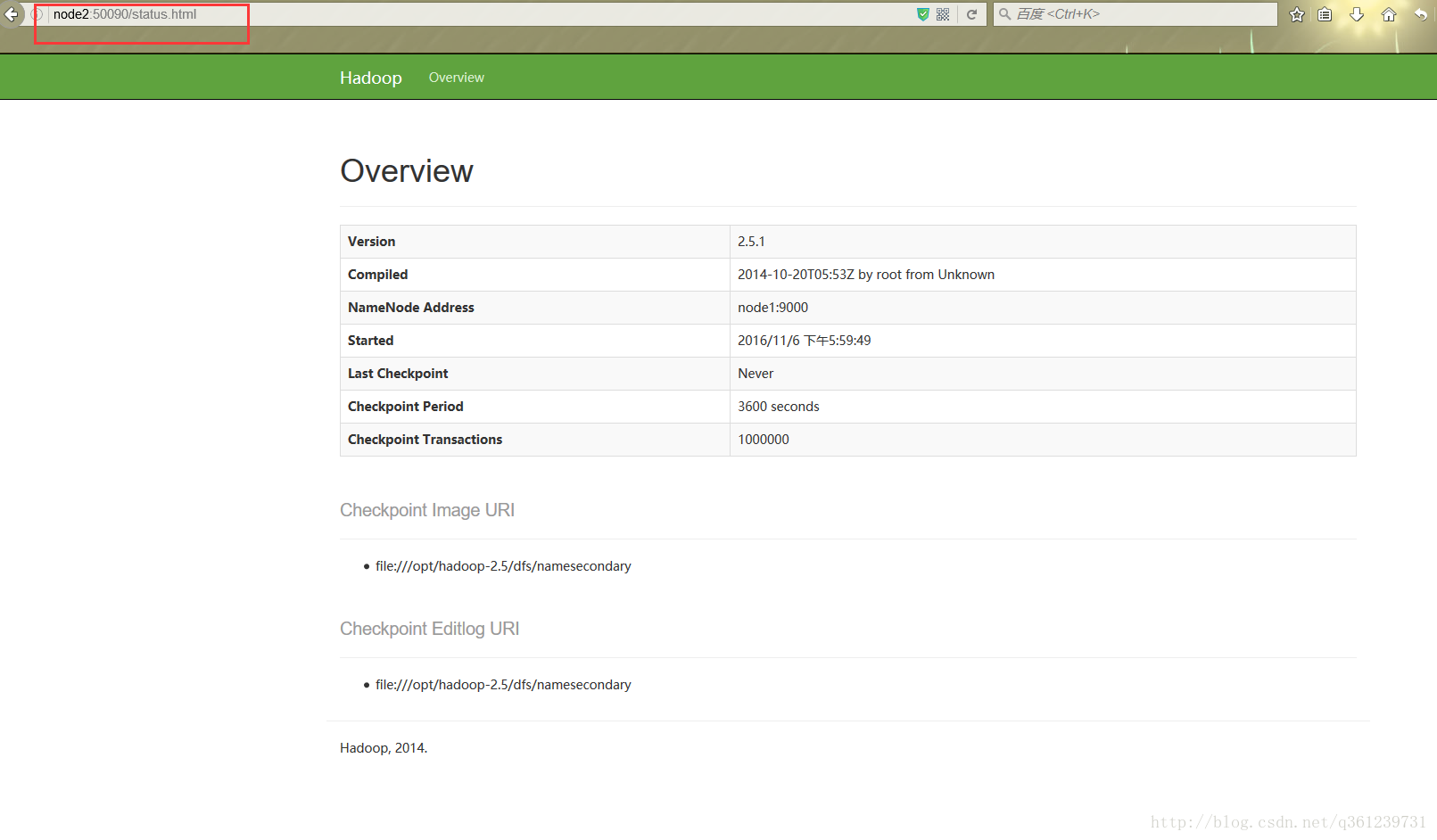
输入node2:50090(hdfs-site.xml中配置的端口)显示下面的页面,即表示配置成功。
结束语
到此为止,HDFS集群的伪分布式的非HA架构已经搭建完毕,不过非HA的环境有点不靠谱,这里做HA的话,是对Namenode做HA,具体过程请参考下一篇:
Hadoop集群之HDFS伪分布式安装 HA(二)














 3728
3728











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









