









在各种计算机体系结构中,对于字节、字等的存储机制有所不同,因而引发了计算机通信领域中一个很重要的问题,即通信双方交流的信息单元(比特、字节、字、双字等)应该以什么样的顺序传送。如果不达成一致的规则,通信双方将无法进行正确的编译码从而导致通信失败。目前在各种体系的计算机中通常采用的字节存储机制主要有两种:大端(Big-Endian)、小端(Little-Endian)。
字节顺序(Endian)
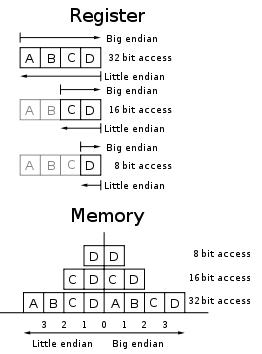
现代计算机系统一般采用字节(Octet,8 bit Byte)作为逻辑寻址单位。当物理单位的长度大于1字节时,就要区分字节顺序(Byte Order, or Endianness)。常见的字节顺序有两种:Big Endian(High-byte first)和Little Endian(Low-byte first),如BE和LE。Intel X86平台采用Little-Endian,而powerPC处理器采用Big-endian。
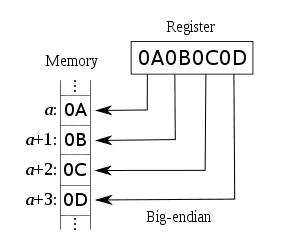
Mapping registers to memory locations
最高有效位MSB:Most Significant Bit
最高有效位,有时候叫最左边的位,是在一个n位二进制数字中的n-1位,此位最高的权重(2^(n-1)).
最低有效位LSB:Least significant Bit
最低有效位是给这些单元值的一个二进制整数位位置,决定这个数字是偶数或奇数。
大端Big-Endian
低地址存放最高有效位,既高位字节排放在内存的低地址端,低位字节排放在内存的高地址端。
在计算机体系结构中一种描述多字节存储顺序的术语,在这种机制中最高有效位存放在最低端的地址上。采用这种机制的处理器有IBM3700系列、PDP-10、Motorola微处理器和绝大多数的RISC处理器。
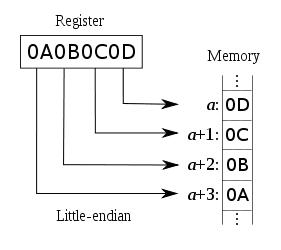
小端Little-Endian
低地址存放最低有效位,既低位字节排放在内存的低地址端,在这种机制中最不重要的字节存放在最低端的地址上。采用这种机制的处理器有PDP-11、VAX、Intel系列处理器和一些网络通信设备,该术语除了描述多字节存储顺序外还常常用来描述一个字节中各个比特的排放次序。
中端Middle-Endian
如3-4-1-2或2-1-43
网络字节序Network Order
Tcp/IP各层协议将字节定义为Big-Endian,因此TCP/IP协议进行通信的时候就需要调用相应的函数进行主机序(Little-Endian)和网络序(Big-Endian)的转换。
如何判断当前系统的字节序列:
方法一:
const int endian = 1;
#define IS_BIG_ENDIAN() ((*(char*)&endian) == 0)
#define IS_LITTLE_ENDIAN() ((*(char*)&endian) == 1)
方法二:
bool islittleEndian()
{
union
{
long val;
char char[sizeof(long)];
} u;
u.val = 1;//1-小端(Inter);0-大端(Motor)
if(u.char[0] == 1)
{
return true;//小端
}
else if(u.char[sizeof(long)-1] == 1)
{
return false;//大端
}
throw("Unknown!");
}














 2033
2033











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









