







目录
1. 背景介绍
2. 框架介绍
3. 参考文献
背景介绍
早在1966年,MIT开发的基于关键词匹配和人工编写规则的ELIZA[1]取的了让人欣喜的结果,之后很多年基于检索式的聊天机器人一些尝试取得了很大的进展,尤其1998年的ALICE通过AIML的模板匹配取得了很好的成果。
不过近几年来,随着神经网络尤其是深度神经网络的不断发展,人们在语音识别、机器翻译等方面取得了突飞猛进的成果。很多人开始把神经网络技术应用在生成聊天机器人中,chatbot也吸引了很多人的关注。
框架介绍
以往的聊天机器人多是基于特定领域型的对话系统或者问答系统,文献[2]中提出了在开放域以数据驱动为主的两种方式,基于检索系统和基于生成系统的方式,并提出了一种可行的结合方式,通过实验验证证实了这种结合方法的优势。
1、文献[2]中的框架介绍
基于检索的对话系统
首先,建立一个相对数量很大的问答数据库,然后,检索系统通过对用户问题的检索获取相应的答案。基于生成的对话系统
生成对话系统是通过对大量语料的训练,得出语言模型,在用户输入问题之后根据之前训练好的语言模型生成相应的答案。
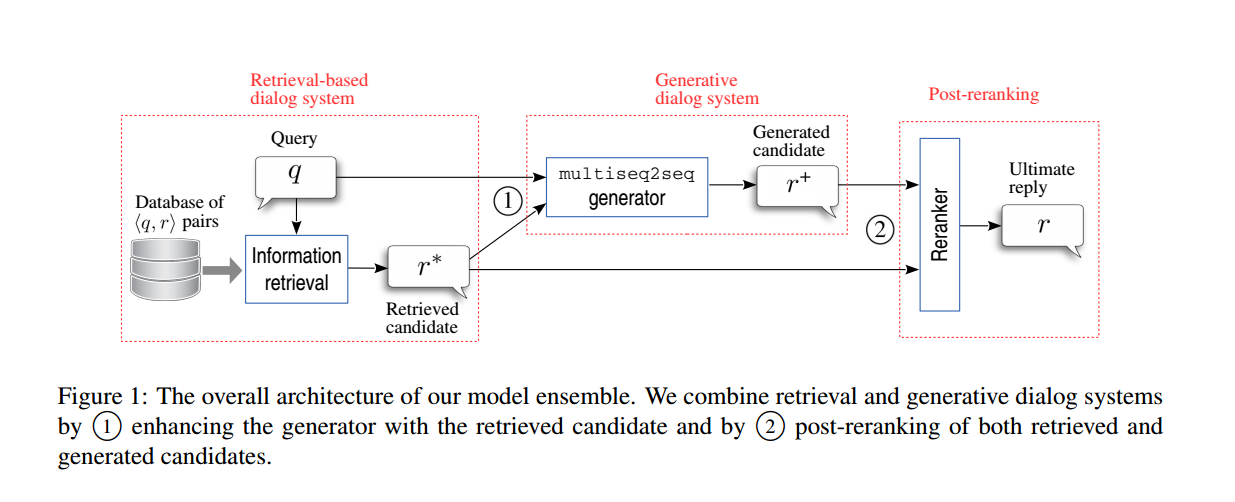
(基于检索和生成的对话系统框架)
该框架过程简要描述如下:
1)当用户输入会话q之后,优先查找问答数据库,得到候选答案r*;
2)将用户的会话q和1)中得到的答案r*一起输入biseq2seq模型,得到候选答案r+;
3)通过对r*和r+的重排序得到q的最终输出结果。
2、 基于以上框架的小补充
如果以上框架在对r* 和r+的比较之后,如果最终输出结果是r* ,那么系统不做调整,如果最终输出结果是r+,那么可以将r+的结果添加到问答数据库中,更新q*对应的答案,这样以后或许会使检索的效果更好(生成模型有一些尚未很好解决的问题,比如RNN的一些缺点)。
3、 该框架存在的问题
上述框架,从实验的角度来看,二者的结合确实比单一的检索或者生成的效果要好,但是目前在实际的应用中并没有得到很好的实现。
其中,主要原因有两个方面:
第一,创建基于检索情况下高质量的问答数据库难度很大,如果在开放域,那将是更加的困难。只有创建基础的日常对话数据库或者针对某一些领域的数据库,其可行性较高。
第二,现有的生成模型并不是万能的,由于模型自身的弱点和自然语言自身的一些特性,使得尚未能够得到一种比较好的生成模型,能够有效的实现对话交流。
4、 如何让框架在中文chatbot中切实有效
未来chatbot定会像语音识别和机器翻译一样取得耀眼的进步,同时会在身边得到很好的应用,而这主要将依托基于生成技术的发展。
在英语中基于生成模型的chatbot已经取得了很好的成果,但是中文由于语言本身的应用难度,并不能够通过现有技术的结合取得实效性进展。中文聊天机器人应该从基本的NLP技术入手,解决比如像中文分词、对象抽取和句子量化表示等基本问题,实现效果可能将会更好。如果一味的借鉴英语的现有技术而不考虑汉语语言本身的情况,可能中文chatbot在应用中还为之尚早。
首先,应该完善基础对话数据库的建设,这一步赋予20%的权重;
其次,从中文自身的特点出发,研究一套适用用于生成模型表示的词、句方式,让中文chatbot生成模型真正适合中文,这一步赋予50%权重;
最后,让对话数据库和生成模型变为一种实时的动态结合的方式,通过实际的测试不断更新数据库优化生成模型,这一步赋予30%权重。
参考文献
[1] 聊天机器人最新研究进展 链接
[2] Two are Better than One: An Ensemble of Retrieval- and Generation-Based Dialog Systems,pdf














 756
756











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









