







这一节主要讲解如何求取SVM的参数α,一种比较高效的算法是SMO算法,首先看下要求的问题:
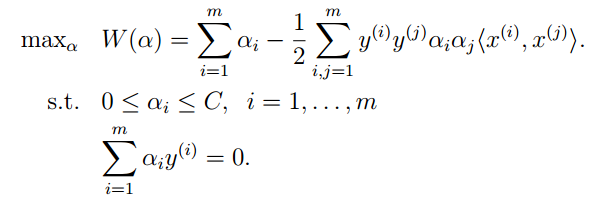
X,Y和C都是已知的量,只有W是要求的。
要求解这个问题,我们先看下
- 坐标上升法
例如要求接一个max_f(x1,x2,…,xn)的问题,其中各个xi是自变量,如果应用坐标上升法求解,其执行步骤就是:
1.首先给定一个初始点,如 X_0=(x1,x2,…,xn);
2.for dim=1:n,固定xi;(其中i是除dim以外的其他维度)
以x_dim为自变量求取使得f取得最大值的x_dim
3.循环执行步骤2,直到f的值不再变化或变化很小。
其关键点就是每次只变换一个维度xi,而其他维度都用当前值进行固定,如此循环迭代,最后得到最优解。
但是在SMO算法中,由于约束条件存在:
我们一次要选取两个α作为变量进行迭代。算法如下:

翻译过来就是,第一步选取一对αi和αj,选取方法使用启发式方法。第二步,固定除αi和αj之外的其他参数,确定 W 极值条件下的αi和αj。选择参数对时,使用一些启发式规则选择使全局函数增长最大的参数。
具体过程可以参考论文:
《Sequential Minimal Optimization A Fast Algorithm for Training Support Vector Machines》
整个过程非常长,但是确实可以提高不少效率。
这里有一篇大神的博客写的很好:
http://www.cnblogs.com/jerrylead/archive/2011/03/18/1988419.html
- 使用LibSVM实现SVM算法
我们使用SVM算法,可以使用别人已经实现好的库,其中最著名的就是LibSVM,这个包也已经被集成到Weka中。
LIBSVM是台湾大学林智仁(Lin Chih-Jen)教授等开发设计的一个简单、易于使用和快速有效的SVM模式识别与回归的软件包,他不但提供了编译好的可在Windows系列系统的执行文件,还提供了源代码,方便改进、修改以及在其它操作系统上应用;该软件对SVM所涉及的参数调节相对比较少,提供了很多的默认参数,利用这些默认参数可以解决很多问题;并提供了交互检验(Cross Validation)的功能。
这个包使用的数据格式是libsvm格式,这个格式在我之前的博客中也有介绍,也提供了多种转换方式。
- 主要参数
下面是Weka暴露给我们的可用参数基本和LibSVM的原始参数一致。具体讲解这些参数含义:
-s
向量机的种类,包括分类(C-SVC,nu-SVC),回归(epsilon-SVR,nu-SVR)以及分布估计(one-class SVM),c-svc中c的范围是1到正无穷
nu-svc中nu的范围是0到1,还有nu是错分样本所占比例的上界,支持向量所占比列的下界。
-k
核函数类型,多项式、线性、高斯、tanh函数。
-d
degree:核函数中的degree设置(针对多项式核函数)(默认3)
-g
核函数中的gamma函数设置(针对多项式/rbf/sigmoid核函数)(默认1/ k)
-r
coef0:核函数中的coef0设置(针对多项式/sigmoid核函数)((默认0)
-c
cost:设置C-SVC,e -SVR和v-SVR的参数(损失函数)(默认1)
-n
nu:设置v-SVC,一类SVM和v- SVR的参数(默认0.5)
-Z
对输入的数据进行normalization,默认是非开启
-J
数据全部都是numric的时候,进行二进制编码
-V
缺失值是否处理,默认是开启
-p
p:设置e -SVR 中损失函数p的值(默认0.1)
-m
cachesize:设置cache内存大小,以MB为单位(默认40)
-e
eps:设置允许的终止判据(默认0.001)
-h
shrinking:是否使用启发式,0或1(默认1)
-wi
weight:设置第几类的参数C为weight*C(C-SVC中的C)(默认1)
- 实现SVM算法
Weka3.7将LibSVM独立出来了,你只需要再额外添加上这个包就可以了。
下面是Maven依赖:
<dependency>
<groupId>nz.ac.waikato.cms.weka</groupId>
<artifactId>LibSVM</artifactId>
<version>1.0.6</version>
</dependency>接下来就是实现SVM,代码如下:
class SVMModel {
private String[] options = {"-S", 0, -K", "0", "-C", 3};
public SVMModel(Instances data) {
LibSVM = new LibSVM();
try {
model.setOptions(options);
model.buildClassifier(data);
} catch (Exception e) {
e.printStackTrace();
}
}
}其实Weka中还有自己的SMO算法实现,位于weka.classifiers.functions.SMO目录下:
与之前的libSVM不同的是,SMO算法和核函数的指定是分开的。核函数在weka.classifiers.functions.supportVector目录下,你需要为核函数再指定一次参数:
class SMOModel {
String[] options =
{ "-C",2,"-K",
"weka.classifiers.functions.supportVector.RBFKernel",
"-C",8000,"-G",1}
public SMOModel(Instances data) {
SMO model = new SMO();
try {
model.setOptions(options);
model.buildClassifier(data);
} catch (Exception e) {
e.printStackTrace();
}
}
}此外,需要明确的是,SVM并不支持多类别分类问题,也就是说,原生的SVM只支持二分类。那么如何使用SVM进行多分类呢?有很多种方法,而且是通用的,用的最多的就是一对一和对对多方法。
- 一对多
一类对余类法(One versus rest,OVR)是最早出现也是目前应用最为广泛的方法之一,其步骤是构造k个两类分类机(设共有志个类别),其中第i个分类机把第i类同余下的各类划分开,训练时第i个分类机取训练集中第i类为正类,其余类别点为负类进行训练。判别时,输入信号分别经过k个分类机共得到k个输出值fi(x)=sgn(gi(x)),若只有一个+1出现,则其对应类别为输入信号类别;实际情况下构造的决策函数总是有误差的,若输出不只一个+1(不只一类声称它属于自己),或者没有一个输出为+1(即没有一个类声称它属于自己),则比较g(x)输出值,最大者对应类别为输入的类别。
一对一
该方法在每两类之间训练一个分类器,因此对于一个k类问题,将有k(k-1)/2个分类函数。当对一个未知样本进行分类时,每个分类器都对其类别进行判断,并为相应的类别“投上一票”,最后得票最多的类别即作为该未知样本的类别。决策阶段采用投票法,可能存在多个类的票数相同的情况,从而使未知样本同时属于多个类别,影响分类精度。Weka中实现了多分类方法,在weka.classifiers.meta.MultiClassClassifier目录下
class MuiltiClassSVMModel {
private String[] options = {"-M", 3,
"-S", 1, "-W","weka.classifiers.functions.LibSVM"};
public MuiltiClassSVMModel(Instances data) {
MultiClassClassifier model = new MultiClassClassifier();
try {
model.setOptions(fullOptions);
model.buildClassifier(data);
} catch (Exception e) {
e.printStackTrace();
}
}
}
- 调参技巧
SVM的参数对结果影响非常大,那么在使用SVM有哪些技巧和需要注意的呢?
①推荐一开始先试线性核函数。在没特殊要求前提下,考虑使用RBF核函数K(x,y)=exp{-gamma|x-y|^2}
②特征数很多时候,线性核效果往往更好。
③数据一定要进行归一化处理。数据都为正数则一般归一到[0,1],否则一般归一到[-1,1]
④使用cross-validation和grid-search 得到最优的c和g,使用GridSearch时,一般使用对数格点。
比如gv=5
C=2^(−5),2^(−3),…, 2^15
gamma = 2^(−15),2^(−13),…,2^13
⑤如果样本分类严重不平衡,推荐给少数类样本加权重,也就是W参数。
需要注意的是,SVM求解一般非常慢,速度和参数、数据集大小、核函数类型等都有关,如果训练太慢,可以采用以下方法加快速度:
练时间过长,你可能需要:
①指定更大的cache size。(-m)
②使用更宽松的stopping tolerance。(-e)
③试试-h 0 (no shrinking) or -h 1 (shrinking)哪个更快。
④数据采样缩小数据集。














 1176
1176











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









