









一)服务注册中心思想
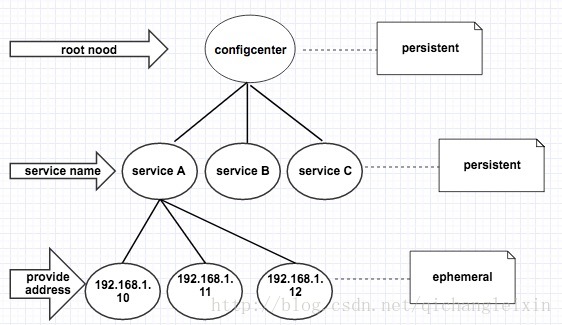
如上图所示,Zookeeper上的服务配置中心分成三层结构,最上面一层为根节点,用来聚集服务节点,通过他可以查询到所有的服务,而服务名称下挂载的是服务提供者的服务器地址。根节点和服务名称采用的是Zookeeper的持久节点(persistent),服务提供者的地址节点,采用的是非持久节点(ephemeral)。
服务提供者在启动时,将其提供的服务名称、服务器地址,以节点(Znode)的形式注册到服务配置中心。服务消费者通过服务配置中心来获得需要调用的服务名称节点下的机器列表节点。通过负载均衡算法,选取其中一台服务器调用。当服务器宕机或者下线时,由于Znode非持久节点(EPHEMERAL)的特性,相应的机器可以动态地从服务配置中心里移除,并触发服务消费者的watcher。在这个过程中,服务消费者只需要第一次调用服务时查询服务配置中心,然后将查询的服务信息缓存到本地,当服务地址列表变更时,变更行为会触发服务消费者注册的watcher,在watcher的回调事件中进行服务地址的修改。这种无中心化的结构,使得服务消费者在服务信息没有变更时,几乎不依赖配置中心,大大降低了服务配置中心的压力。
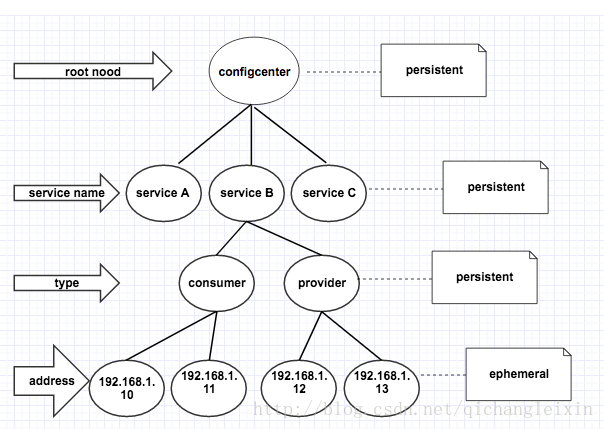
当服务规模变大,服务之间的依赖变得越来越复杂时,服务之间的调用关系已非人力所能理清,很多时候我们不仅需要了解有哪些服务提供方,还需要知道有哪些服务消费者,以了解服务的调用情况。对比图1,图2增加了一层用来表示节点类型,每个服务包含两种节点类型,即consumer和provider。当服务消费者启动时,即在服务配置中心里,在其调用的所有服务的consumer节点下增加自己的机器地址,如图2所示。这样,只需要后台监控程序解析出对应服务的consumer节点的子节点,便能清楚地知道某一服务被哪些机器消费了。
二、实现代码
基于Zookeeper所实现的服务消费者获取服务提供者地址列表的部分代码如下
String zkServerList="127.0.0.1:2181";
String serviceName="serviceB";
String servicePath="/configcenter/"+serviceName;//服务节点路径
ZkClient zkClient=new ZkClient(zkServerList);
List<String> serviceList=null;
boolean serviceExists=zkClient.exists(servicePath);
if(serviceExists){//服务存在,取服务地址
serviceList=zkClient.getChildren(servicePath);
}else{
throw new RuntimeException("service not exist!");
}
//注册监听事件,服务列表节点变更时,重新获取
zkClient.subscribeChildChanges(servicePath, new IZkChildListener() {
public void handleChildChange(String parentPaths, List<String> currentChilds) throws Exception {
serviceList=currentChilds;
}
});
服务提供者向Zookeeper集群注册服务的部分代码如下
String zkServerList="127.0.0.1:2181";
String rootPath="/configcenter/";//根节点路径
String serviceName="serviceB";//服务名称
ZkClient zkClient=new ZkClient(zkServerList);
boolean rootExists=zkClient.exists(rootPath);
if(!rootExists){
zkClient.createPersistent(rootPath);
}
boolean serviceExists=zkClient.exists(rootPath+"/"+serviceName);
if(!serviceExists){
//创建服务节点
zkClient.createPersistent(rootPath+"/"+serviceName);
}
//注册当前服务器,可以在节点的数据里面存放节点的权重
InetAddress addr= InetAddress.getLocalHost();
String ip=addr.getHostAddress().toString();//获得本机IP
//创建当前服务器节点
zkClient.createEphemeral(rootPath+"/"+serviceName+"/"+ip);













 193
193











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









