







a、类型参数化
Scala 的类型参数化是指在定义类、函数时,参数的数据类型并不明确,需要在创建具体的实例或调用函数时才可以确定,这时,可以用一个占位符(通常为A ~ Z中的单个字符)来替代,这类似于java的泛型。如下:
def position[A](xs: List[A], value: A): Int = {
xs.indexOf(value)
}scala> val xs = List("one", "two", "three")
xs: List[java.lang.String] = List(one, two, three)
scala> position(xs, "two")
res2: Int = 1
scala> val ys = List(20, 30, 40)
ys: List[Int] = List(20, 30, 40)
scala> position(ys, 40)
res6: Int = 2
scala> position[Int](ys, 300)
res11: Int = -1
b、类型的协变、逆变
类型的协变和逆变是用来解决类型参数化的泛化问题(继承关系)。
对于一个带类型参数化的类型,比如List[T],如果类型A及其子类型B,满足List[B]也符合List[A]的子类型,那么就称为协变(covariance),如果List[A]是List[B]的子类型,那么就称为逆变(contravariance)。
例如,B是A的子类:
协变: B -> A,List[B] -> List[A]
逆变:B -> A,List[A] -> List[B]
如果一个类型支持协变或逆变,那么这个类型称为可变的(variance),否则是不可变的(invariant)。
在java中,泛型都是不可变的,例如List<String>不是List<Object>的子类,Java并不支持声明点变型(declaration-site variance,即在定义一个类型时声明它为可变型,也称definition-site),而scala支持,可以在定义类型时声明(用加号表示为协变,减号表示逆变),如:
trait List[+T] // 在类型定义时(declaration-site)声明为协变 List<? extends Object> list = new ArrayList<String>();scala> val a : List[_ <: Any] = List[String]("A")
a: List[_] = List(A)scala> trait A[+T]
scala> class C[T] extends A[T] // C是invariant的
scala> class X; class Y extends X;
scala> val t:C[X] = new C[Y]
<console>:11: error: type mismatch;
found : C[Y]
required: C[X]
Note: Y <: X, but class C is invariant in type T.
You may wish to define T as +T instead. (SLS 4.5)scala> class C[+T] extends A[T]
scala> val t:C[X] = new C[Y]
t: C[X] = C@6a079142上边界:java泛型中,表示某个类型是Test类型的方式为:
<T extends Test>
或使用通配符的方式:
<? extends Test>[T <: Test]
或用通配符的方式为:
[_ <: Test]<T super Test>
或使用通配符:
<? supper Test>[T >: Test]
或者使用通配符:
[_ >: Test]Java中T是A和B的子类型,称为多重边界,如:<T extends A & B>
Scala里对上界和下界不能有多个,不过变通的做法是使用复合类型(compund type):[T <: A with B]
而对于lower bounds,在java里则不支持multiple bounds的形式:
<T super A & B> //java不支持[T >: A with B]A with B相当于 (A with B),仍看成一个类型,详见复合类型。
d、高阶函数
高阶函数是在调用时,把一个函数作为参数或返回一个函数,就认为这样的函数为高阶函数。常用高阶函数为map、filter、reduce等。如下:
def addOne(num: Int) = {
def ++ = (x:Int) => x + 1
++(num)
}
scala> List(1, 2, 3) map addOne
res15: List[Int] = List(2, 3, 4)
f、创建函数对象
函数对象是一个对象,可以把它当做一个函数使用,和普通函数不同的是,函数对象必须要定义一个具体的apply()方法,在使用该函数对象时,实际是调用的apply方法。如下例:
object foldl {
def apply[A, B](xs: Traversable[A], defaultValue: B)(op: (B, A) => B) = (defaultValue /: xs)(op)
}scala> foldl(List("1", "2", "3"), "0") { _ + _ }
res0: java.lang.String = 0123
scala> foldl(IndexedSeq("1", "2", "3"), "0") { _ + _ }
res24: java.lang.String = 0123
scala> foldl(Set("1", "2", "3"), "0") { _ + _ }
res25: java.lang.String = 0123g、Scala的集合结构
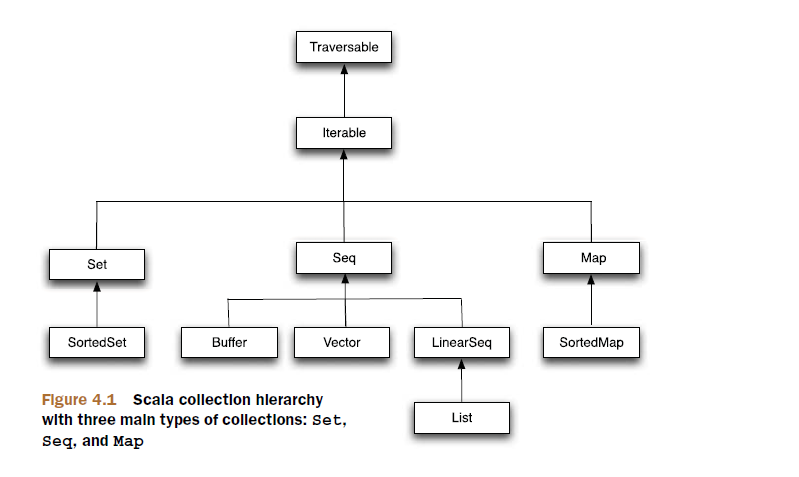
Scala中的集合都分布在scala.collection包及其子包中,其中scala.collection.mutable包中定义的是可变集合,对可变集合的操作可能会有副作用,即在集合上做的新增、修改、删除操作,都将改变原集合的状态。而scala.collection.immuable包中定义的为不可变集合,集合的状态不会改变,在集合上的操作(增、删、改),都将返回一个新的集合。
另外,定义在scala.collection包下的集合,既是可变的,也是不可变的。例如scala.collection.Map[A, +B]是collection.mutable.Map[A, B]和collection.immutable.Map[A, +B]的超类。通常scala.collection包下的根集合,定义了同不可变集合一样的接口,并且可变集合可以在不可变集合上添加额外的方法,改变不可变集合的状态。如:
scala> val mapping: collection.Map[String, String] = Map("Ron" -> "admin","Sam" -> "Analyst")
mapping: scala.collection.Map[String,String] =Map(Ron -> admin, Sam -> Analyst)
scala> val mapping: collection.Map[String, String] = collection.mutable.Map("Ron" -> "admin", "Sam" -> "Analyst")
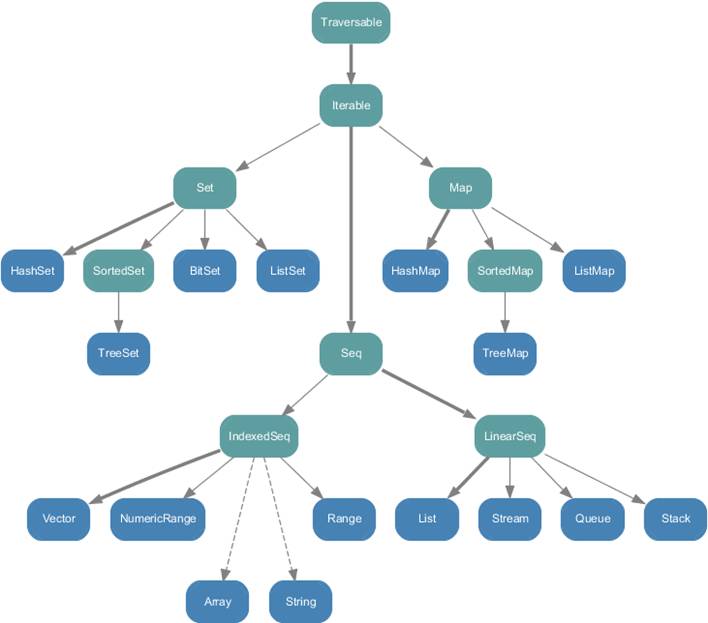
mapping: scala.collection.Map[String,String] = Map(Sam -> Analyst, Ron ->admin)scala.collection.immutable包下的所有类,如下图:
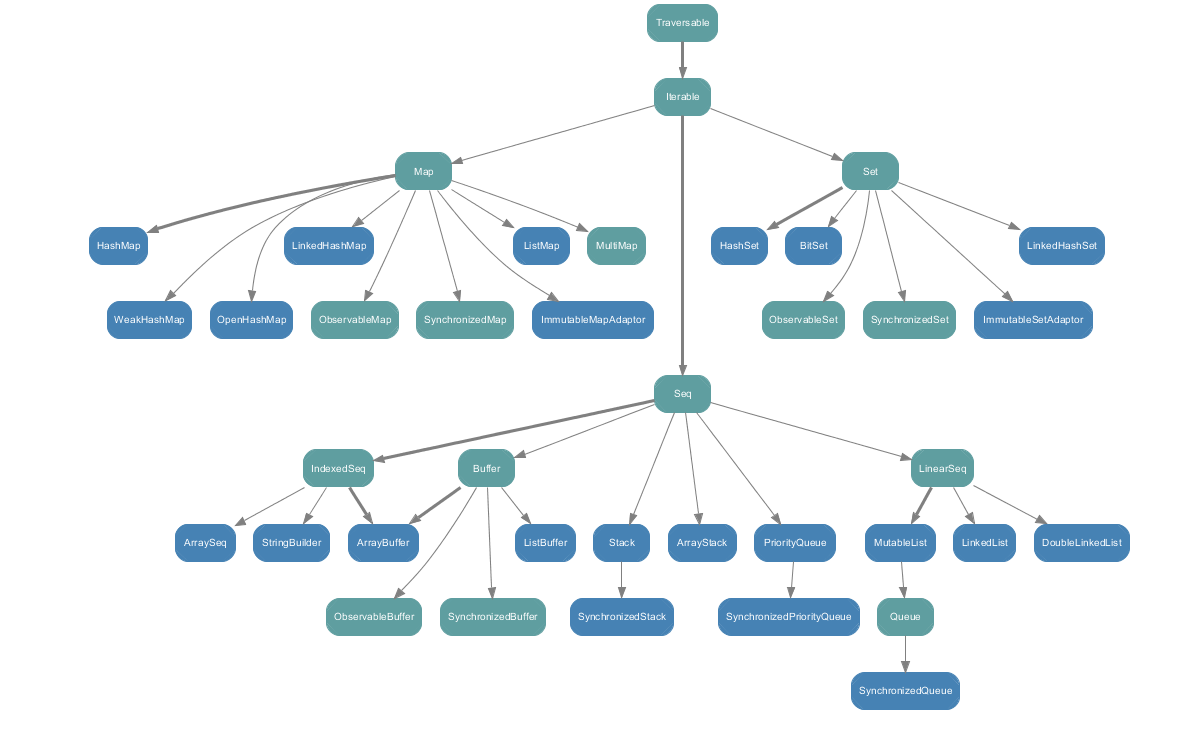
scala.collection.mutable包下的所有类,如下图:
h、常用集合的使用方法
详见:http://blog.csdn.net/qiruiduni/article/details/46788797
i、使用Option ,而不是 Null
相信,java程序员对null的处理是挺痛苦的,如果引用变量是null,将会抛出NullPointerException异常,为避免这种情况,通常要做非空检查,这将是代码变得难以阅读。
Scala采用Option来解决这种问题。Option表示可选值,可以把它看做一个容器(就像List集合),它是一个抽象类,并且定义了两个子类scala.Some(表示一种存在的值) 和scala.None(表示一种不存在的值),它的实例为要么为scala.Some,要么为scala.None。
详细见:http://blog.csdn.net/qiruiduni/article/details/46792387
j、使用懒惰的集合(lazy collection):View和Stream
为了理解lazy collection,先来看下与之相对的strict collections(严格的集合),通常,strict collection会急切的计算它元素。如下例:
scala> List(1, 2, 3, 4, 5).map( _ + 1).head
res43: Int = 2scala> val newList = List(1, 2, 3, 4, 5).map( _ + 1)
newList: List[Int] = List(2, 3, 4, 5, 6)
scala> newList.head
res44: Int = 2对于这种情况,数据量小时,还没什么问题,如果数据量大时,就会占用大量的资源。
Scala提供了view和stream两种方式,可以创建“按需”集合,即延迟计算,在需要的时候才真正计算,这将大大提升性能,特别是在比较耗时的操作。
如上例改为使用view的方式:
scala> List(1, 2, 3, 4, 5).view.map( _ + 1).head
res46: Int = 2使用Stream
Scala的Stream像一个惰性的List,它的元素分为两部分:头部(head)和尾部(tail),尾部中的元素不会被计算直到需要时。因为Stream混入了LinearSeq,所以可以使用List集合中的所有方法。下例为使用Stream实现的一个Fibonacci函数:
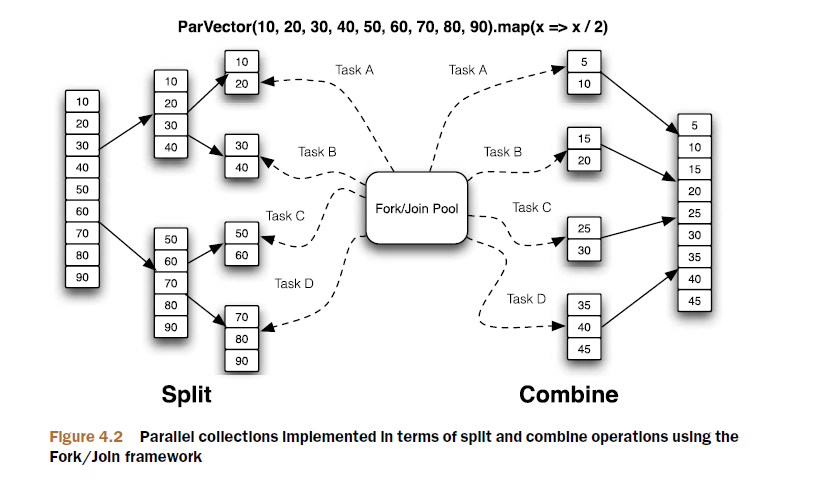
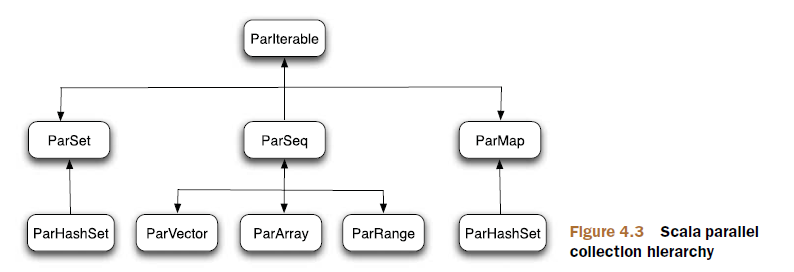
val fib: Stream[Int] = Stream.cons(0, Stream.cons(1, fib.zip(fib.tail).map(t => t._1 + t._2)))Scala的并行集合,采用先拆分后组合的方式,拆分将并行集合拆分为小的Iterable集合,直到达到定义的阈值停止拆分,然后创建一组任务(task),用于并行执行已拆分好的Iterable集合。创建任务是通过Fork/Join框架实现的,Fork/Join框架计算出可用于执行操作的CPU数量,然后使用线程去执行这些任务。最后,将这些任务的输出组合成最终的结果。见下例:
scala> import scala.collection.parallel.immutable._
import scala.collection.parallel.immutable._
<pre name="code" class="html">scala> ParVector(10, 20, 30, 40, 50, 60, 70, 80, 90).map {x =>
println(Thread.currentThread.getName); x / 2 }ForkJoinPool-1-worker-2
ForkJoinPool-1-worker-3
ForkJoinPool-1-worker-3
ForkJoinPool-1-worker-3
ForkJoinPool-1-worker-3
ForkJoinPool-1-worker-1
ForkJoinPool-1-worker-0
ForkJoinPool-1-worker-0
res2: scala.collection.parallel.immutable.ParVector[Int] = ParVector(5, 10,
15, 20, 25, 30, 35, 40, 45)
配置并行集合
在Scala中,TaskSupport负责调度并行集合的操作,主要负责追踪线程池、负载均衡及任务的调度。Scala提供了几种TaskSupport的实现:
- ForkJoinTaskSupport:这将使用fork-join线程池,适用于JVM1.6。
- ThreadPoolTaskSupport:比ForkJoinTaskSupport低效,它使用普通的线程池执行任务。
- ExecutionContextTaskSupport:这是并行集合默认的TaskSupport,它的底层也是使用fork-join线程池。
import scala.collection.parallel._
val pv = immutable.ParVector(1, 2, 3)
pv.tasksupport = new ForkJoinTaskSupport(new scala.concurrent.forkjoin.ForkJoinPool(4))scala> ParVector(10, 20, 30, 40, 50, 60, 70, 80, 90).foldLeft(0) {(a,x) =>
println(Thread.currentThread.getName); a + x }
Thread-14
Thread-14
Thread-14
Thread-14
Thread-14
Thread-14
Thread-14
Thread-14
Thread-14
res3: Int = 450














 9761
9761











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









