






原文地址:http://ceur-ws.org/Vol-1179/CLEF2013wn-QALD3-CabrioEt2013.pdf
关联数据上的多语种问答(QALD-3):实验综述
Philipp Cimiano1,Vanessa Lopez2, Christina Unger1, Elena Cabrio3,
Axel-Cyrille Ngonga Ngomo4, and Sebastian Walter1
1 CITEC, Universit¨at Bielefeld, Germany
{cimiano,cunger}@cit-ec.uni-bielefeld.de;
swalter@techfak.uni-bielefeld.de
2 IBM Research, Dublin, Ireland
vanlopez@ie.ibm.com
3 INRIA Sophia-Antipolis, France
elena.cabrio@inria.fr
4 Universit¨at Leipzig, Germany
ngonga@informatik.uni-leipzig.de
摘要:第三期在关联数据(QALD-3)上问答的开放挑战在2013年的CLEF上已经被管理作为半日制实验。不同于以往版本的挑战,QALD-3把重点放在了多语种,提出了两个任务:第一个是多语种问答,另外一个是本体词汇化。目前,还没有收到关于后面问题的提交意见,前面的问题已经吸引了六个团队,他们提交了他们在提供数据集上实现的系统。这篇文章提供一个关于QALD的综述,讨论了上述提供的系统的实验和获得的结果。
1介绍
随着越来越多的语义数据在网上发布,典型的网络用户如何访问到知识本身变得尤为重要。在过去的几年中,与日俱增的在交互模块的研究让终端用户能够在标准的语义网表达中获取方便的查询方式,通过一种简单易用的用户接口,从而避免语义网的复杂性。就像论文[11]中提出的那样。尤其是自然语言接口,获得了极大的关注,因为它们允许用户通过直观的表达方式来表达复杂的信息,至少在遵循原则的基础上,用他们自己的语言。关键的技术依赖于将用户的语言转换成一种形式化的查询,从而可以利用标准语义查询处理和推理技术。最后,系统必须能够处理多形式的,分布式的和大型连通数据。这种可用的在开源和结构化数据上的方法,在计算机科学和方法上都没有先例可以处理特别的关联数据,因而这种技术是紧急需要的。另外,多语言已经成为语义网研究团体的主要兴趣所在,因为不是通过英语创建的角色和发布的数据,和不说英语的访问关联数据的用户变得越来越多。为了让来自世界各地的人们可以访问相同的信息,系统能够克服语言的障碍,可以通过多语种访问语义网数据变得尤为迫切。
在关联数据上的问答1(QALD)的开放挑战的主要目的是提供最新的要求基准,从而建立一个标准,使得在结构化数据上的问答系统可以被评估和比较。QALD-3是QALD开放挑战的第三个版本,在CLEF 2013上被组织成半日实验。这篇文章剩下的部分描述了先前版本的挑战(第2章),QALD-3的主要内容和实验设置(第3章)和提交的系统的性能(第4章)。(第5章)主要在现有的版本上得出了一些结论,并且为未来的版本提出了一些建设性的意见。
2 先前QALD版本的挑战
QALD挑战的目的是把不同团体的研究者和开发者聚集在一起,包括自然语言处理,语义网,社会计算和数据库。第一个版本,QALD-1,是在ESWC 2011 的关联数据上的问答讨论会上被提出的。第二个版本,QALD-2,是在ESWC 2012的关于关联数据交互的讨论会上被提出的,并且还被扩展到关联数据其他的领域,包括关联数据交互的其他范例和鼓励交互的范例。
在QALD-1的背景下,两个数据集变得可获得的-Dbpedia和一个以RDF形式导出的音乐数据库-每一个都包含50个训练问题和50个测试问题。这些问题是由一个毫无问答背景的学生助教提出的,为了避免对于某一种方法的偏爱。这些问题的提出是为了提出潜在的用户问题和包括大量的关于词汇二义性和复杂语法结构的挑战。所有的问题都被设置成SPARQL查询方式。对于QALD-2,两个问题的集合被合并成一个新的训练集,并且提供了一个新的测试集合,对于DBpedia有100个测试问题和100个测试问题,对于MusicBrainz,有100个训练问题和50个测试问题。另外,一些超出范围的问题也被添加盗了问题集中,数据集合不包含答案。目的是为了测试对于参加的系统,当回答失败时,是依赖于数据集还是系统本身。进一步的,我们提供了一些问题,只有综合两个数据集,Dbpeida合MusicBrainz才能得到结果,目的是测试系统为了得到结果,综合查询多个数据集的能力。所有的QALD-2的问题都加入了关键词注释,为了鼓励基于关键词的方法来参加这个挑战。
如果想得到这个挑战的细节和参加的系统得到的结果,请参考文献[10]。
3.QALD-3
有效利用QALD从语义网和自然语言处理团体得到的正反馈,第三版本的挑战被提出来问了介绍新的元素。最后,QALD-3提出了两个分开的任务,多语种问答,保持了原来版本的挑战不变,并且把多语种作为创新点;和本体词汇化,目的是为了让所有的方法自动词汇化本体中的概念。在接下来的文章中,我们介绍了更多关于我们提出的任务和为挑战者提供的资源的的细节。
3.1任务1:多语种问答系统
任务一的目的是为了在所有的查询问答系统中,连接用户通过自然语言表达的信息和语义数据。给定一个RDF数据集合一个自然语言问句或者是一系列用以下语言给出的关键词(英语,西班牙语,德语,意大利语,法语,荷兰语),参加的系统,或者能够给出正确的结果,或者能够给出检索到结果的SPARQL查询语言。为了能够评估和比较参加的系统,给出了三个RDF数据集:
-English DBpedia 3.82(包括超链接,链接到YAGO仓库或者MusicBrainz),一个团体提供的从维基百科中提取的并且能够有效的作为RDF数据。
-Spanish DBpeida5,包含从维基百科中提取的西班牙语的资源(包含大约100万RDF三元组)
-MusicBrainz,一个合作者提供的开放内容的音乐数据库,这个数据集为挑战提供的是包含所有的类(艺术家,相册和 )的RDF接口和最重要的关于MusicBrainz的属性。
这些数据可以被下载或者通过SPARQL被访问。
为了获得关于知识库的知识和可能的问题,针对每一个数据集(English Dbpedia,Spanish Dbpedia和MusicBrainz),提供了一个包含100个训练问题的集合。然后,系统通过100个测试问题被评估。测试问题和训练问题都是采用的QALD-2挑战的问题,只做了轻微的改变,为了能够适应Dbpedia数据集的改变和为了参与者能够使用相关性反馈。作为一个主要的创新,所有问题和关键词都被翻译成了英语,西班牙语,德语,意大利语,法语和荷兰语。下面是一些从训练集合中选取出来的英语问题:
-DBpedia:
5.欧洲有多少君主制国家?
58.谁导演了最多的电影?
74.哪一个欧洲国家的首都举办过夏季奥林匹克运动会?
85.那一部电影里包含朱莉.罗伯特和理查德.盖尔?
-Spanish DBpedia:
2.阿方索普雷马索图的儿子娶了谁?
4.贝隆夫人在哪座城市去世?
20.巴塞罗那的地区编码是多少?
40.佩德罗.阿莫西瓦导演了多少部电影?
-MusicBrainz:
2.大卫.鲍威属于哪一个团队的一员?
44.少年心气有多少个版本?
79.相册破坏的主唱是谁?
89.The Vertigos乐队创建的时间是什么时候?
所有的训练问题和测试问题都通过人为方式进行关键词标注,转换为SPARQL查询语言和通过SPARQL查询语言检索到答案,注释通过XML的方式提供。对于每一个查询有一个ID号和一系列这个问题的属性和这个问题的六种自然语言的表达形式,相同语言的关于这个问题的关键词描述,一个相关的查询和这个查询获得的答案。除了一个独一无二的ID,对于每一个问题,都有以下这些对无二的属性:
-answertype 提供答案的类型,可以使以下这些类型中的一种:资源(一个或多个资源,提供URI),字符串(字符类型值),数字(一个数值,例如47,1.8),日期(一个以以下形式提供的日期YYYY-MM-DD,1983-11-02),布尔类型(对或错)。
-aggregation 指出要回答这个问题,是否需要在三元组上进行额外的运算。
-onlydbo 只针对DBpedia上的问答,标识查询是否依赖于DBpedia本体中的概念。
下面是一个简单的关于DBpedia的训练集中的例子:

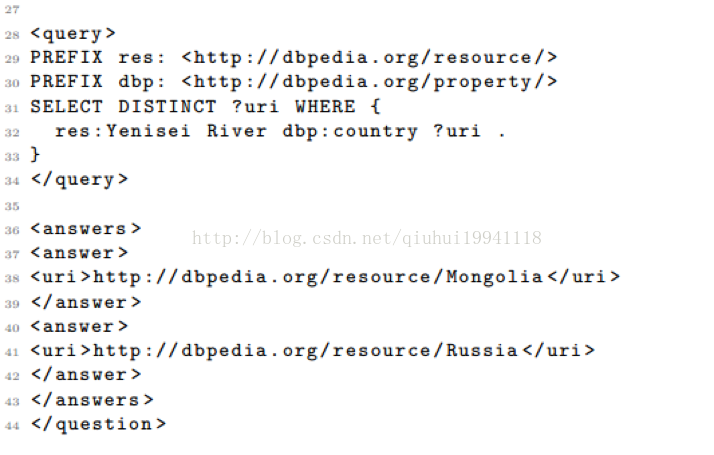
作为一个额外的挑战,一些训练问题和测试问题超出了范围,利用现有的这些数据集无法做出回答。
3.2任务2:本体词汇化
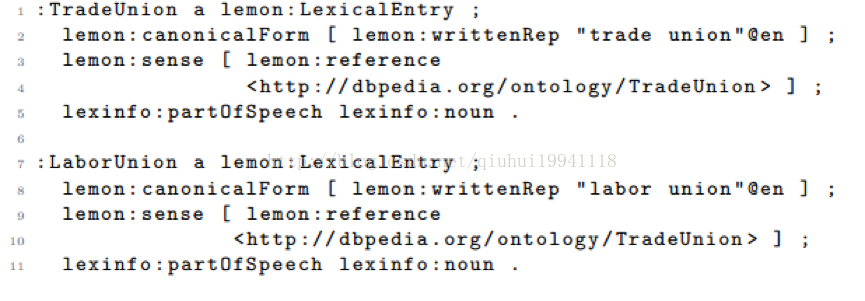
多语种信息访问可以被可用的多种语言的词典促进,例如允许利用西班牙语,德语或者法语的自然语言来访问英文的本体。这个任务主要是为了找出Dbpeida本体,例如维基百科语料库中的类和属性的英文词汇。训练数据为参赛者提供了DBpedia本体中的10个类和30个属性和通过这些类构建的莱蒙形式的词典。类和属性被随机的选择(属性包含少于20个实体对或者属性多与100000个实体对)。下面是一个期望的从Dbpeida中获取的词汇化转换:
3.3评估策略
参与系统提供的答案被自动的和标准答案进行比较。
任务1 对于每一个问题q,准确率,召回率和F-measure 按照以下方式计算:
召回率(q)= 系统回答出的问题q的正确答案/标准答案中问题q的正确答案
准确率(q)= 系统回答出的问题q的正确答案/系统回答出的问题q的正确答案
F-Measure(q)=2*准确率(q)*召回率(q)/(准确率(q)+召回率(q))
这些标准的基础上,对于每一个系统回答的所有问题,准确率和召回率和F-measure都计算一个平均值,在第四章中介绍的准确率和召回率和F-measure都是一个平均值。
任务2 对于每一个属性,没有被加载的文字实体都被自动的和人工创建的文字实体通过两个方式进行匹配:i)词汇的准确率,词汇的召回率和词汇的F-measure,2)词汇的精度。第一个方式评估对于参与者来说找到了多少个标准集合中的属性,和自动产生的实体中有多少个在标准实体集合中(准确率),两个实体对应同一个词汇,如果他们的文字标识,发音和语义一致。对于一个属性词汇化的准确率Plex和召回率Rlex的定义如下:
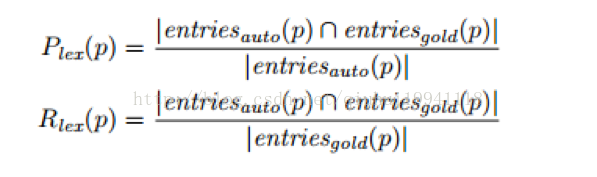
其中,entitiesauto(p)是属性p自动构建出来的词汇,entitiesgold(p)是人工构建的标准实体集中的词汇,F-measure Flex(p)是Plex(p)和Rlex(p)的调和平均。
第二种方式,词汇精度是非常必要的,因为它用来衡量转换的词汇的划分和参数是否正确,和这些语法参数是否能够正确的匹配上语义资源。属性p w.r.t自动转换的词汇的精度lauto和lgold的关系定义如下:
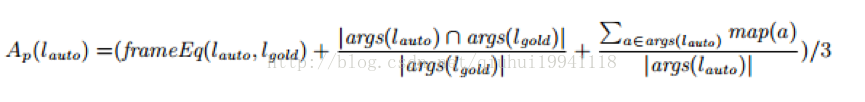
其中为1当且仅当l1的次类划分框架和l2的次类划分框架相同,其他情况下,为0.args(l)返回l的语法参数,其中:

当比较自动产生的实体的标准集合实体的参数匹配时,只有参数的类被考虑,例如主语或者宾语。这些从特殊类型主语(例如连接主语)和宾语(间接宾语,前置宾语)提取出来的摘要允许进行独立的框架匹配。对于属性p词汇化的精确度Alex(p)按照产生的词汇的平均精度计算。对于所有的属性都按照评估策略计算然后取平均值。
4.参加的系统,结果和讨论
有六支队伍参加了QALD-3,比去年的挑战多了两支队伍:其中五支队伍来自欧洲(三支来自法国,一支来自德国,一支来自意大利),一支队伍来自亚洲(中国)。参赛的队伍可以选择挑战一个或者两个任务。六支队伍都参加了多语种问答任务,其中五支队伍选择了DBpedia,一支队伍选择了Dbpedia和MusicBrainz。没有队伍选择了了本体词汇化的任务。
4.1参加的系统
参加的系统采用不同的方法来处理关联数据上的问答。在问题的解释方面,有的采用语言学的策略,例如,分析语法模式,或者是采用统计学的方法。和采用自然语言作为输入的系统相比,squall2sparql采用SQUALL作为输入,一种受控制的英文自然语言,Scalewelis采用的是切面搜索,而不是自然语言搜索。下面,我们给出一些参赛系统的细节介绍。
Intui[3]是一个关联数据上的问答原型系统,通过分析自然语言问句的句法成分,可以回答RDF数据集上的自然语言问句。依照句法,句法碎片嵌入问句的句法分析树的子树,语义上,文字的最小扩展可以被指代为概念URI,RDF三元组或者是复杂的RDF查询。这些句法碎片合理的排列从而来解释我们输入的问句。
SWIP[14]依赖于查询模式来标记自然语言查询解释任务。查询解释包含两个主要的步骤。第一步,自然语言查询被转换成一个中心点查询,依赖分析和提取自然语言子串中的关系。第二步,事先定义好的模板被用来匹配这些中心点查询,从而获得一系列潜在的用户可能需要的查询,然后根据相关性和用户对自然语言的反馈来进行排序。
CASIA[8]实现了一个由问题分析,资源匹配,和SPARQL产生组成的通道。具体的,系统首先将自然语言转换成一系列查询三元组,形式为<主语,谓语,宾语>,依赖于一种浅层的和深层的语言学分析。第二步,系统通过DBpedia链接资源,实例化查询三元组为本体三元组。第三步,依赖于本体三元组和查询类型构建查询语言SPARQL。最后,候选查询被排序列出,分数最高的查询被选择。
Squall2sparql[5]是一个将SQUALL,一种受控制的英文自然语言转换成SPARQL的翻译器。给出一个SQUALL语句,系统首先根据蒙塔古法则,将句子翻译成一种中间逻辑代表物。这种中间表示物通过逻辑结构和SPARQL结构的匹配被转化成形式化的SPARQL。
Scalewelis[7]是一个切面搜索引擎,通过引导用户查询正确的答案。从一个初始化的SPARQL查询开始,根据这个查询获取到的前100个结果构造切面,由结果所有的类和依赖于结果的数据集中的实体构成,用户在切面中的选择被用来精炼查询,直到结果被找到。
RTV系统[6]结合词汇的语义模型和概率论推断,以一种复杂的结构化模式来将自然语言问句转换成一个三个步骤的串联:i)从自然语言问句中选择突出的信息(例如,谓语,或者属性),ii)根据突出信息在本体中的位置,通过连接消歧得到候选集,iii)组合成最后的查询来检索RDF三元组。这个模型利用了一个潜在的马尔科夫模型(HMM)根据RDF图模型来选择一个适当的本体三元组。特别的,针对每一个查询,哪一种解决方案的维特比综合了连接消歧和句子的成分,相应的HMM模型将被给出。
4.2利用的额外的资源和工具
表1列举了参赛队伍用到的额外的资源了工具,在这些资源中,维基百科和WordNet被用来提取语义知识(例如,在Intui2中计算单词之间的相似性)。涉及到额外的工具,文本处理工具被用来分析问题成分(例如Stanford CoreNLP,MaltParser 和Chaos),信息检索工具例如Lucene在系统RTV中被用来建立维基百科索引,或者在SWIP中用来获得字符串相似性分数。
两个参加的系统没有采用任何的句法分析工具,squall2sparql通过利用一个受控制的英文自然语言作为输入,从而过滤掉了大量的依赖于语言词汇的问题;Scalewelis,依赖于切面搜索而不是问题解释。
4.3结果
表二和表三分别列出了参加系统在Dbpeida和MusicBrainz数据集上得到的结果。具体的,处理栏系统回答了多少问题,正确栏表示这些系统在F-measuere等于1的情况下回答正确的问题数。
表1.参赛系统用到的额外的资源和工具

部分的指定在严格控制F-measure在0到1之间的情况下,系统能够回答出多少问题。在DBpedia数据集中,最高的F-measure是0.9,最低的是0.17,平均的是0.4。这些得到的结果和早些版本得到的结果是可以进行比较的,显示问题的复杂性依旧显得十分苛刻。
表2DBpedia测试集上的结果
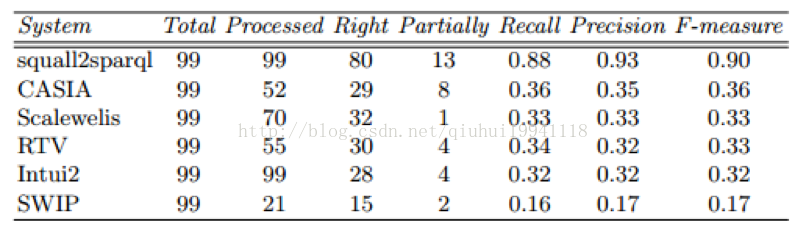
表3 MusicBrainz测试集上的结果

下面这些在Dbpeida上的问题被所有的系统所回答:
ID Question
21 加拿大的首都是哪里?
22 俄怀明州的州长是谁?
30 安格拉·默克尔的姓是什么?
68 谷歌有多少名员工?
下面这些DBpedia上问题的没有被任何系统回答:
ID Question
14 给出《奇迹》所有的成员。
16 新的《太空堡垒卡拉狄加》相对于老的版本是否有更多的插曲?
92 给出布鲁斯·斯普林斯汀在1980年到1990年创作的所有歌曲。
96 给出莱蒙斯的B面。
所有的测试集中的问题,45个问题需要利用除了DBpedia之外其它的命名空间,(属性onlydbo=flase),例如YAGO或者FOAF,19个问题需要用到联合查询(属性 aggegation=true),例如比较,就像上面的问题16一样,最高级,就像问题15(哪一条是世界上长的河?)或者是过滤,例如问题92,。在这些查询中,系统的性能表现的都比较差。
5结论和展望
QALD-3,第三版的QALD挑战,比以前的版本吸引和更多的挑战者前来挑战,显示着研究人员变得越来越有兴趣提供一种简单易用的接口给终端用户,让他们能够方便的访问大量的语义网上的数据-不仅仅是古老的问答系统,还有切面问答系统。尽管我们面向的是多语种问答系统,但是大部分的研究者还是只能在英文系统上进行工作。这表明多语种研究问题目前还没有被广泛关注,尽管它已经开始产生吸引力了(一个被用来翻译QALD问题作为评估的系统参见文献[1])。另外,本体词汇化的问题只有一个系统在转换阶段被提到了(没有一个参加了本体词汇化挑战,参见论文[15]),但是没有一个系统在测试阶段。这暗示着轻微将这个任务整合到挑战中的不同,例如提供额外的资源给参加比赛的问答系统和邀请参与者分享他们自己的词汇资源。
在未来的挑战中,我们想强调更加深远的关联数据上的问答,例如需要处理多样的联通数据集或者混合资源信息(结构化的RDF资源和非结构化的文本),同时保留着多语种这个核心任务。由于MusicBrainz数据集在以往三个QALD挑战中的使用率都没有Dbpedia使用频率那个高,我们打算将他改成另外的人们可能更感兴趣的领域本体。特别的,我们认为,生物领域具有巨大的潜力来吸引新的参加者,并且提供新的在关联数据问答上的挑战。
参考文献
1. N.Aggarwal, T. Polajnar, and P. Buitelaar. Cross-lingual natural languagequerying over the web of data. InNatural Language Processing andInformation Systems,pages 152–163. Springer, 2013.
2. R. Basiliand F. M. Zanzotto. Parsing engineering and empirical robustness. NaturalLanguage Engineering, 8:2002, 2002.
3. C. Dima.Intui2: A prototype system for question answering over linked data.InProceedingsof the Question Answering over Linked Data lab (QALD-3) at CLEF2013.Lecture Notes in Computer Science (to appear).Springer, 2013.
4. C.Fellbaum. WordNet: An Electronic Lexical Database. Bradford Books, 1998.
5. S.Ferr´e. squall2sparql: a translator from controlled english to full sparql 1.1.InProceedings of the Question Answering over Linked Data lab (QALD-3) at CLEF2013.Lecture Notes in Computer Science (to appear).Springer, 2013.
6. C. Giannone, V. Bellomaria, and R. Basili. Ahmm-based approach to question answering against linked data. InProceedingsof the Question Answering over Linked Data lab (QALD-3) at CLEF2013.Lecture Notes in Computer Science (to appear).Springer, 2013.
7. J.Guyonvarch and S. Ferr´e. Scalewelis: a query-based faceted search system on topof sparql endpoints. InProceedings of the Question Answering over LinkedData lab (QALD-3) at CLEF2013. Lecture Notes in Computer Science (toappear). Springer, 2013.
8. S. He, S. Liu, Y. Chen, G. Zhou, K. Liu, andJ. Zhao. Casia@qald-3: A question nswering system over linked data. InProceedingsof the Question Answering over Linked Data lab (QALD-3) at CLEF2013.Lecture Notes in Computer Science (to appear).Springer, 2013.
9. D. Kleinand C. D. Manning. Accurate unlexicalized parsing. In Proceedings of the41st Annual Meeting on Association for Computational Linguistics – Volume 1,ACL ’03, pages 423–430, Stroudsburg, PA, USA, 2003. Association forComputational Linguistics.
10. V. Lopez, C. Unger, P. Cimiano, and E. Motta. Evaluationquestion answering over linked data.Journal of Web Semantics, in press.
11. V. Lopez, V. S. Uren, M. Sabou, and E. Motta. Is questionanswering fit for the semantic web?: A survey.Semantic Web,2(2):125–155, 2011.
12. N. Nakashole, G. Weikum, and F. Suchanek. Patty: a taxonomy ofrelational patterns with semantic types. InProceedings of the 2012 JointConference on Empirical Methods in Natural Language Processing andComputational Natural Language Learning, EMNLP-CoNLL ’12, pages 1135–1145,Stroudsburg, PA, USA,2012. Association for Computational Linguistics.
13. J. Nivre, J. Hall, and J. Nilsson. Maltparser: A data-drivenparser-generator for dependency parsing. InIn Proc. of LREC-2006, pages2216–2219, 2006.
14. C. Pradel, G. Peyet, O. Haemmerl´e, and N. Hernandez. Swip atqald-3: results,
criticisms and lesson learned. In Proceedings of the Question Answering overLinked Data lab (QALD-3) at CLEF2013. Lecture Notes in Computer Science(to appear). Springer, 2013.
15. S. Walter, C. Unger, and P. Cimiano. A corpus-based approachfor the induction of ontology lexica. InNatural Language Processing andInformation Systems, pages 102–113. Springer, 2013.














 164
164











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









