







Scrapy 爬虫框架爬取网页数据
由于知识储备有限,见解或编码有错误,希望大家能指明~共同进步~~
在没有正式接触python之前,也用python 写过小的爬虫demo,记得当时用的urllib发送网络请求获取源码后用beautifulsoup解析的html,(当时还以为很厉害的样子,线程之类的都没用,慢的基本让人受不了~~),前几天看到scrapy框架后感觉之前都是弱爆了(屠龙宝刀跟霸业面甲就是没法比啊),所以准备写一文章,熟悉一下框架的使用和一些新技术的应用吧.
首先介绍下本系列文章会用的技术吧
- Scrapy爬虫框架
- XPath(解析html)
- MongoDB
- Linux基本操作
- Python基础知识~
首先安装下虚拟沙盒 virtualenv
Mac 和 Ubutun 都可以直接pip安装
pip install virtualenv
然后创建虚拟环境安装scrapy
➜ ~ virtualenv car-ENV && cd car-ENV
Running virtualenv with interpreter /usr/bin/python2
New python executable in car-ENV/bin/python2
Not overwriting existing python script car-ENV/bin/python (you must use car-ENV/bin/python2)
Installing setuptools, pip…done.
➜ car-ENV source ./bin/activate
(car-ENV)➜ car-ENV pip install scrapy
Downloading/unpacking scrapy
….
等一会就安装完成了
然后安装MongoDB
ubutun :apt-get install mongodb
mac : brew install mongodb (brew 需自行安装)
接下来了解下 Scrapy 框架
中文文档:http://scrapy-chs.readthedocs.org/zh_CN/latest/intro/tutorial.html
官方网址:http://scrapy.org/
An open source and collaborative framework for extracting the data you need from websites. In a fast, simple, yet extensible way.
正如官网上说的一样,快速,简单,扩展性好.用过之后你就会知道他的强大~
下面开始我们的爬虫之旅
新建项目还是非常简单的
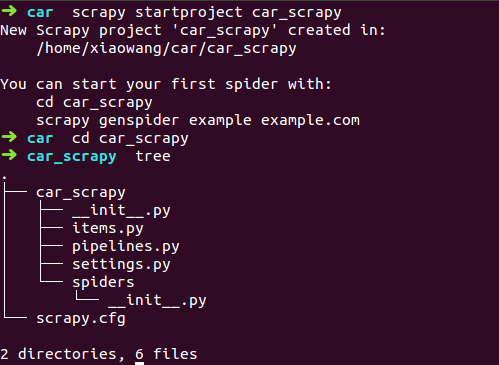
可以看到scrapy项目主要是两个目录六个文件
- Item :定义实体数据结构
- Spiders:定义爬取规则,实现爬取网页具体编码
- Item Pipeline:存取爬出的数据,实现存取具体实现方法
- Settings:配置文件
首先看一个爬出的网页太平洋汽车网
http://newcar.xcar.com.cn/car/
http://newcar.xcar.com.cn/m25720/
爬取汽车的详细信息:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 4153
4153











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









