








字符集与中文编码
ASCII: 最简单的字符集,一共收集了几十个字符。( 该字符集的编号:ISO/IEC 646 )
ISO/IEC 646: 即ISO发布的第646号标准其他字符集:
ISO 8859-1 :ISO发布的第8859号标准的第1部分,涵盖了西欧的常用字符(德文、法文)
给定一串字节数据,如果不说明它的字符集及编码方式,我们就无法知道它代表了哪些字符。
比如,
byte[] data = {
(byte)0x61, (byte)0x62, (byte)0xD6,
(byte)0xD0, (byte)0xB9, (byte)0xFA
};
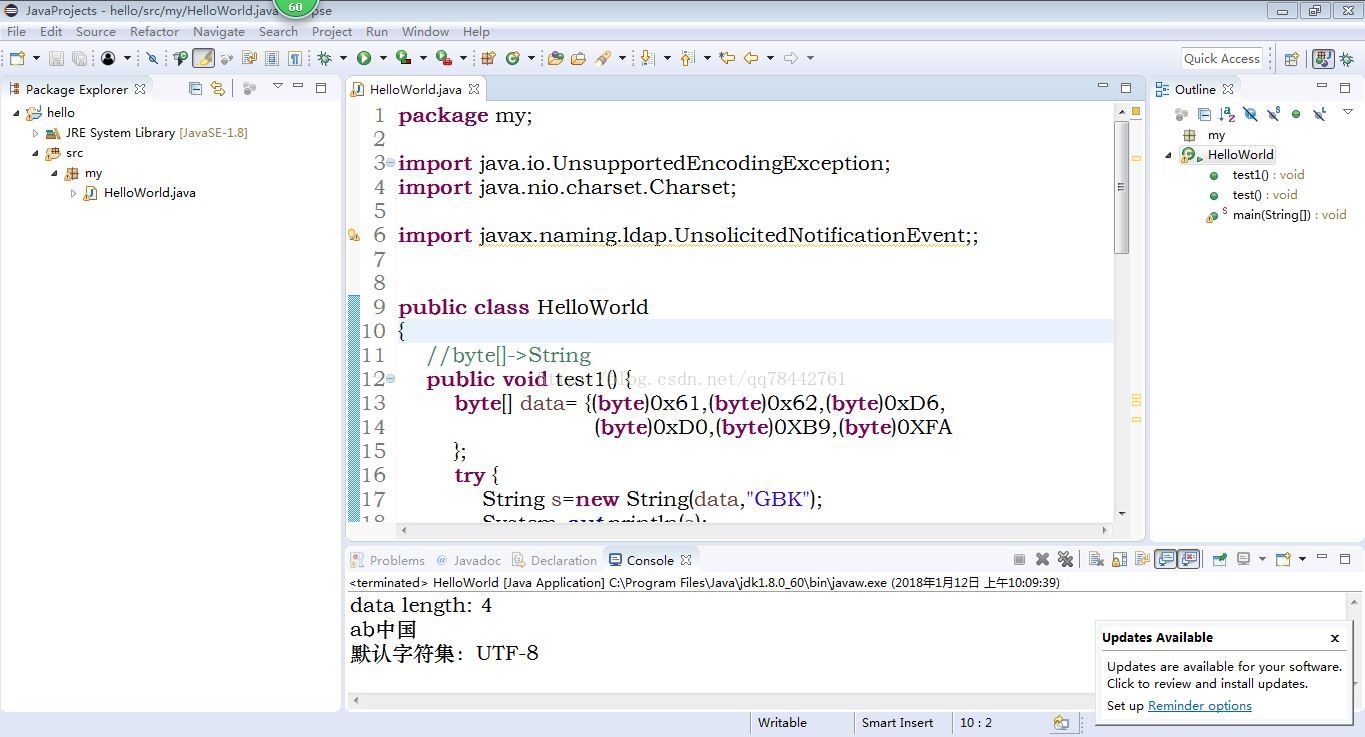
如果知道它是GBK编码,则我们知道它是"ab中国"
如果不知道它的编码,则无法确定它到底代表什么。
注意
源文件*.java本身也有一个编码问题但*.java在编译之后,会统一转成Unicod
代码如下:
HelloWorld.java
package my;
import java.io.UnsupportedEncodingException;
import java.nio.charset.Charset;
import javax.naming.ldap.UnsolicitedNotificationEvent;;
public class HelloWorld
{
//byte[]->String
public void test1() {
byte[] data= {(byte)0x61,(byte)0x62,(byte)0xD6,
(byte)0xD0,(byte)0XB9,(byte)0XFA
};
try {
String s=new String(data,"GBK");
System.out.println(s);
}catch(UnsupportedEncodingException e) {
e.printStackTrace();
}
}
//String->byte[]
public void test() {
String str="中国";
try {
byte[]data=str.getBytes("GBK");
System.out.println("data length: "+data.length);
}catch(UnsupportedEncodingException e) {
e.printStackTrace();
}
}
public static void main(String[] args)
{
char ch1='a';
char ch2='中';
String str="ab中国";
int length=str.length();
HelloWorld t=new HelloWorld();
t.test();
t.test1();
//检测默认字符集
Charset cs=Charset.defaultCharset();
System.out.println("默认字符集:"+cs.toString());
}
}
运行截图如下:















 2460
2460











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











