







作者:刘旭晖 Raymond 转载请注明出处
Email:colorant at 163.com
BLOG:http://blog.csdn.net/colorant/
Memcached和Redis作为两种Inmemory的key-value数据库,在设计和思想方面有着很多共通的地方,功能和应用方面在很多场合下(作为分布式缓存服务器使用等) 也很相似,在这里把两者放在一起做一下对比的介绍
基本架构和思想
首先简单介绍一下两者的架构和设计思路
Memcached
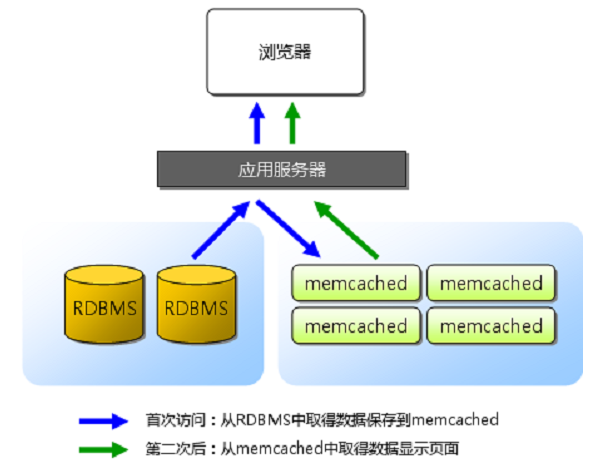
Memcached采用客户端-服务器的架构,客户端和服务器端的通讯使用自定义的协议标准,只要满足协议格式要求,客户端Library可以用任何语言实现。
从用户的角度来说,服务器维护了一个键-值关系的数据表,服务器之间相互独立,互相之间不共享数据也不做任何通讯操作。客户端需要知道所有的服务器,并自行负责管理数据在各个服务器间的分配。
在服务器端,内部的数据存储,使用基于Slab的内存管理方式,有利于减少内存碎片和频繁分配销毁内存所带来的开销。各个Slab按需动态分配一个page的内存(和4Kpage的概念不同,这里默认page为1M),page内部按照不同slab class的尺寸再划分为内存chunk供服务器存储KV键值对使用

Memcached的基本应用模型如下图所示
Redis
Redis的基本应用模式和上图memcached的基本相似,不难发现网上到处都是关于redis是否可以完全替代memcached使用的问题
Redis内部的数据结构最终也会落实到key-Value对应的形式,不过从暴露给用户的数据结构来看,要比memcached丰富,除了标准的通常意义的键值对,Redis还支持List,Set, Hashes,Sorted Set等数据结构
基本命令
Memcached的命令或者说通讯协议非常简单,Server所支持的命令基本就是对特定key的添加,删除,替换,原子更新,读取等,具体包括 Set, Get, Add, Replace, Append, Inc/Dec 等等
Memcached的通讯协议包括文本格式和二进制格式,用于满足简单网络客户端工具(如telnet)和对性能要求更高的客户端的不同需求
Redis的命令在KV(String类型)上提供与Memcached类似的基本操作,在其它数据结构上也支持基本类似的操作(当然还有这些数据结构所特有的操作,如Set的union,List的pop等)而支持更多的数据结构,在一定程度上也就意味着更加广泛的应用场合
除了多种数据结构的支持,Redis相比Memcached还提供了许多额外的特性,比如Subscribe/publish命令,以支持发布/订阅模式这样的通知机制等等,这些额外的特性同样有助于拓展它的应用场景
Redis的客户端-服务器通讯协议完全采用文本格式(在将来可能的服务器间通讯会采用二进制格式)
事务
redis通过Multi / Watch /Exec等命令可以支持事务的概念,原子性的执行一批命令。在2.6以后的版本中由于添加了对Script脚本的支持,而脚本固有的是以transaction事务的方式执行的,并且更加易于使用,所以不排除将来取消Multi等命令接口的可能性
Memcached的应用模式中,除了increment/decrement这样的原子操作命令,不存在对事务的支持
数据备份,有效性,持久化等
memcached不保证存储的数据的有效性,Slab内部基于LRU也会自动淘汰旧数据,客户端不能假设数据在服务器端的当前状态,这应该说是Memcached的Feature设定,用户不必太多关心或者自己管理数据的淘汰更新工作,当然是否适合你的应用,取决于具体的需求,它也可能成为你需要精确自行控制Cache生命周期的一个障碍
Memcached也不做数据的持久化工作,但是有许多基于memcached协议的项目实现了数据的持久化,例如memcacheDB使用BerkeleyDB进行数据存储,但本质上它已经不是一个Cache Server,而只是一个兼容Memcached的协议key-valueData Store了
Redis可以以master-slave的方式配置服务器,Slave节点对数据进行replica备份,Slave节点也可以充当Read only的节点分担数据读取的工作
Redis内建支持两种持久化方案,snapshot快照和AOF 增量Log方式。快照顾名思义就是隔一段时间将完整的数据Dump下来存储在文件中。AOF增量Log则是记录对数据的修改操作(实际上记录的就是每个对数据产生修改的命令本身),两种方案可以并存,也各有优缺点,具体参见http://redis.io/topics/persistence
以上Redis的数据备份持久化方案等,如果不需要,为了提高性能,也完全可以Disable
性能
性能方面,两者都有一些自己考虑和实现
Memcached
memcached自身并不主动定期检查和标记哪些数据需要被淘汰,只有当再次读取相关数据时才检查时间戳,或者当内存不够使用需要主动淘汰数据时进一步检查LRU数据
Redis
Redis为了减少大量小数据CMD操作的网络通讯时间开销 RTT (Round Trip Time),支持pipeline和script技术
- 所谓的pipeline就是支持在一次通讯中,发送多个命令给服务器批量执行,带来的代价是服务器端需要更多的内存来缓存查询结果。
- Redis内嵌了LUA解析器,可以执行lua 脚本,脚本可以通过eval等命令直接执行,也可以使用script load等方式上传到服务器端的script cache中重复使用
这两种方式都可以有效地减少网络通讯开销,增加数据吞吐率
对于KV的操作,Memcached和Redis都支持Multiple的Get和Set命令(Memcached的Multiple Set命令貌似只在二进制的协议中支持),这同样有利于性能的提升
实际性能方面,网上有很多测试比较,给出的结果各不相同,这无疑和各种测试的测试用例,测试环境,和测试时具体使用的客户端Library实现有关。但是总体看下来,比较靠谱的结论是在kv类操作上,两者的性能接近,Memcached的结构更加简单,理论上应该会略微快一些。
集群
memcached的服务器端互相完全独立,客户端通常通过对键值应用Hash算法决定数据的分区,为了减少服务器的增减对Hash结果的影响,导致大面积的缓存失效,多数客户端实现了一致性hash算法
Redis计划在服务器端内建对集群的支持,但是目前代码还处于alpha阶段(貌似已经Design了两三年了?)在此之前,同样可以认为每个Redis服务器实例相互之间是完全独立的,需要依靠客户端处理分区算法和可用服务器列表管理的工作。
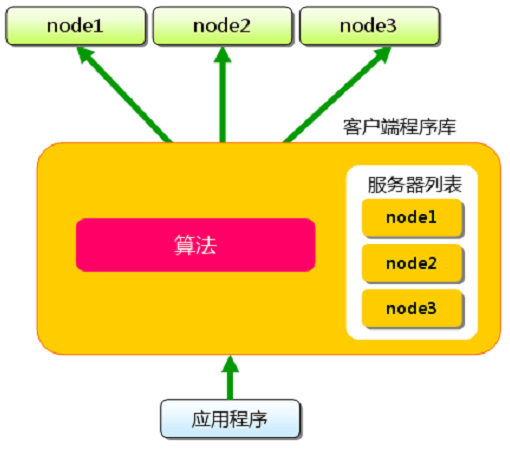
Redis官方推荐的用于Sharding的客户端程序库是Twitter的开源项目 Twemproxy, Twemproxy同时支持Memcached和Redis的文本通讯协议。
需要注意的是,Redis的许多命令在集群环境下是不能正确运行的,例如set的交集,以及跨节点的事务操作等等,因为目前的Redis集群设计,根本目标也就是服务器之间互相汇报一下存活状态,以及对数据做荣誉备份平衡负载等而已,本质上对数据的跨节点操作并不提供任何额外支持,所以在数据服务的层面上来说,各个服务器依旧是完全独立的。
这些操作如果一定要实现,当然可以通过客户端代码来实现(效率有多高且不说),类似的问题memcached集群当然也会遇上,但是原本memcached就不支持复杂的操作和数据类型,许多运算逻辑原本就是由客户端代码或应用程序自己处理的。
MR类批处理应用
提供指定范围的遍历操作,是支持类似MapReduce这样的批处理应用逻辑的关键之一,但是要在基于hash方式存储的数据结构的基础上提供这样的支持并不容易(或者说要实现高效的范围或遍历操作并不容易)
Redis支持Scan操作用于遍历数据集,这一操作基于其内部数据结构及实现的限制,可以保证在Scan开始时的所有数据都能被获取到,但是不能保证不返回重复的数据,这需要由客户端来检查,或者客户端对此无所谓。Scan操作还支持Match条件用来过滤键值,虽然存在一定的局限性,例如match条件的比较是在获取数据之后再执行的,效率是一个问题,更明显的问题是不能保证每次scan的iterate过程都能返回同样数量的有效数据。
对于范围操作,Redis的Ordered Set支持在插入时指定数据的分数(Score)用于排序,而后支持在指定Score范围内的各种操作,虽然由于不支持基于字符串的或自定义的基准的Range操作,这样的范围操作应用起来有很大的局限性(或者说需要满足特定的应用模式),但是还是比没有好了
Memcached核心协议本身不支持任何范围类的操作,也没有对遍历操作的支持,甚至不存在官方合法的列举所有Key的操作,这当然很大程度上源于其设计思想和精简的架构
不过还是有一些兼容memcached协议的服务器实现了范围类操作,具体格式可以参考 https://code.google.com/p/memcached/wiki/RangeOps 所建议的标准
此外Redis的Hashes数据结构,在一定程度上可以满足获取特定子集数据的应用逻辑需求。
综上来说,如果要实现类似Hbase支持的scan操作,不论是Redis还是memcached都无法做到,但是对于Redis来说,能否用于批处理类应用,不能一概而论,取决于具体的数据的格式逻辑和使用方式。通过适当的调整应用程序使用数据的方式,还是有可能在一定程度上实现对MR类批处理,或范围查询类应用逻辑的支持的。而对于键值分布在一个较大的连续空间,数量不确定,同时又无法很好的映射为数值进而使用ordered set来处理的这样一些数据结构,应该还是很难高效的分区遍历的
-
顶
- 0
-
踩
- 0
我的同类文章
- •FTP 服务器(vsftpd)搭建鸟哥详细教材2016-02-11
- •利用AbstractRoutingDataSource实现动态数据源切换2015-11-08
- •How Twitter Uses Redis to Scale - 105TB RAM, 39MM QPS, 10,000+ Instances2015-08-29
- •征服 Redis + Jedis2015-08-19
- •druid简单教程2015-08-19
- •巧用Squid的ACL和访问列表实现高效访问控制2015-08-18
- •安装和使用memcached2016-01-06
- •国内外三个不同领域巨头分享的Redis实战经验及使用场景2015-08-29
- •ZooKeeper实现分布式队列Queue2015-08-29
- •在CentOS下搭建自己的Git服务器2015-08-19
- •高性能缓存服务器Squid架构配置2015-08-18














 3298
3298











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









