







该方法源自论文,Single-Image CrowdCounting via Multi-Column Convolutional Neural Network,是上海科技大学张营营的作品。论文在各个数据集上都取得了state-of-the-art的效果。
网络结构如下图所示,使用的是全卷积的网络,并且进行了融合。
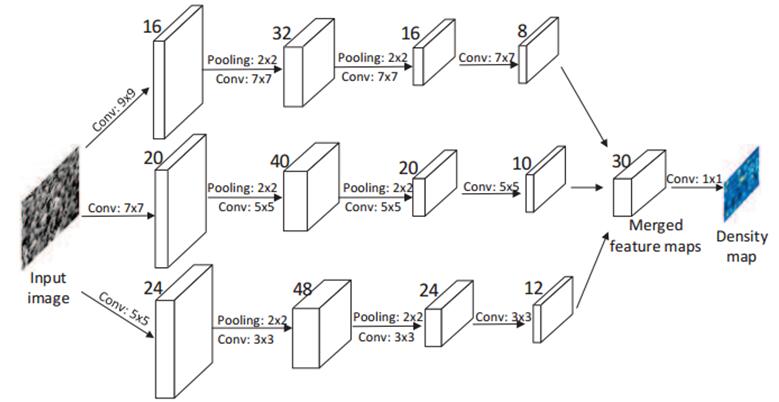
使用融合可以获得比单一网络更好的性能,同时由于网络结构比较宽,作者借鉴了RBM的思想,分别预训练单一网络,最后用3个训练好的单一网络对融合网络进行权值初始化,再进行finetune,得到了更好的效果。
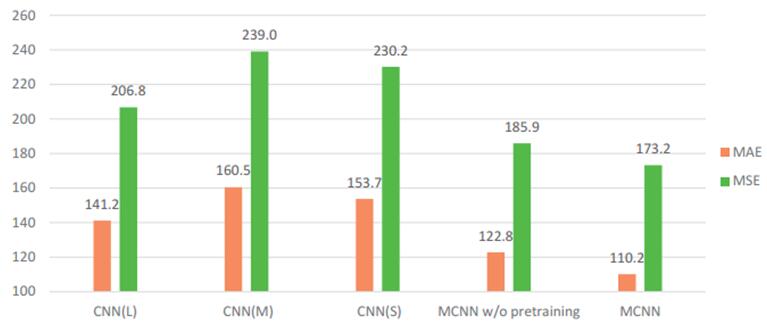
作者在论文中还对各种损失进行了对比分析,一般来说,训练这样的网络的损失,很自然是可以想到2种,一种是基于density map的L2 loss,另一种就是王小刚的一个论文Cross-scene Crowd Counting via Deep Convolutional NeuralNetworks中的global count loss。单纯使用一种Loss的话,L2也许是更好的选择,但是如果使用2种Loss进行互补训练的话,也许会更好。
作者自己收集整理的Shanghaitechdataset,包含1198个图共330165个人,分为A,B两个部分,A的人群密集,B的稀疏,A中trainset为300,testset为182,B中trainset为400,testset为316。
分享一下我自己的训练经验,我这里是使用的malldataset进行训练的。首先需要准备数据,data很简单,直接调用caffe的convert_imageset转化为LMDB就可以。label部分则需要自己提取density_map。这个可以做成jpg形式的map,同样转化为LMDB。也可以制作为HDF5,程序如下:
clear;
load('perspective_roi.mat');
load('mall_gt.mat');
m=480;n=640;
m=m/4;
n=n/4;
mask = imresize(roi.mask,0.25);
for i=1:2000
i
gt = frame{i}.loc;
gt = gt/4;
d_map = zeros(m,n);
for j=1:size(gt,1)
ksize = ceil(25/sqrt(pMapN(floor(gt(j,2)),1)));
ksize = max(ksize,7);
ksize = min(ksize,25);
radius = ceil(ksize/2);
sigma = ksize/2.5;
h = fspecial('gaussian',ksize,sigma);
x_ = max(1,floor(gt(j,1)));
y_ = max(1,floor(gt(j,2)));
if (x_-radius+1<1)
for ra = 0:radius-x_-1
h(:,end-ra) = h(:,end-ra)+h(:,1);
h(:,1)=[];
end
end
if (y_-radius+1<1)
for ra = 0:radius-y_-1
h(end-ra,:) = h(end-ra,:)+h(1,:);
h(1,:)=[];
end
end
if (y_-radius+1<1)
for ra = 0:radius-y_-1
h(end-ra,:) = h(end-ra,:)+h(1,:);
h(1,:)=[];
end
end
if (x_+ksize-radius>n)
for ra = 0:x_+ksize-radius-n-1
h (:,1+ra) = h(:,1+ra)+h(:,end);
h(:,end) = [];
end
end
if(y_+ksize-radius>m)
for ra = 0:y_+ksize-radius-m-1
h (1+ra,:) = h(1+ra,:)+h(end,:);
h(end,:) = [];
end
end
d_map(max(y_-radius+1,1):min(y_+ksize-radius,m),max(x_-radius+1,1):min(x_+ksize-radius,n))...
= d_map(max(y_-radius+1,1):min(y_+ksize-radius,m),max(x_-radius+1,1):min(x_+ksize-radius,n))...
+ h;
end
%方法1,保存为图片,再转为LMDB
% str=num2str(i,'./density/seq_%06d.jpg');
% imwrite(d_map,str);
%方法2,直接转为HDF5
trainLabels=permute(d_map,[2 1]);
str=num2str(i,'./density_map/seq_%06d.h5');
h5create(str,'/label',size(trainLabels),'Datatype','double');
h5write(str,'/label',trainLabels);
end
这里为了加速模型的收敛,我进行了减均值和归一化操作。由于数据集只有2000,并不像imagenet那样的大数据,为了提高泛化能力,适应不同的数据集,我这里的均值没有取2000个图片的均值,而是直接设置为127.5,归一化则除以128。
测试程序如下:
clear;clc;
addpath('/home/caffe/matlab');
caffe.reset_all();
caffe.set_device(0);
caffe.set_mode_gpu();
model = 'deploy.prototxt';
weights = 'network.caffemodel';
net = caffe.Net(model, weights, 'test');
cropImg=imread('IMG_12.jpg');
cropImg = cropImg(:, :, [3, 2, 1]);
cropImg = permute(cropImg, [2, 1, 3]);
cropImg = single(cropImg);
cropImg=imresize(cropImg,[480 640]);
cropImg=(cropImg-127.5)/128;
res = net.forward({cropImg});
figure,imshow(cropImg,[]);
figure,imagesc(res{1,1});
count = sum(sum(res{1,1}))
caffe.reset_all();
贴几个效果图:















 182
182











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









