






hadoop1.2.1单机试玩-安装部署
一、Linux环境搭建
虚拟机安装Linux mint系统(基于Ubuntu16)
二、配置Linux jdk环境变量
1、首先安装jdk,命令:apt-get install <jdk -version>
2、到之前找到jdk安装路径->for example:/usr/lib/jvm/java-8-openjdk-amd64
3、配置jdk环境变量
命令:vim /etc/profile
添加:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
然后使文件生效:source /etc/profile
检查jdk是否安装成功:java -version 出现代如下表安装成功!

4、下载安装Hadoop
这里是以1.2.1版本为示例(注:如需下载其他版本直接改连接的版本号即可)
这里是以1.2.1版本为示例(注:如需下载其他版本直接改连接的版本号即可)
命令:wget http://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-1.2.1/hadoop-1.2.1.tar.gz
安装到指定的目录下:
$ mv hadoop-1.2.1.tar.gz /opt/hadoop-->移动到/opt/hadoop路径下面
$ cd /opt/hadoop-->切换到/opt/hadoop工作路径
$ tar zxvf hadoop-1.2.1.tar.gz-->解压到当前路径下面
--配置Hadoop的环境变量
命令:vim /etc/profile
添加:
export HADOOP_HOME=/opt/hadoop/hadoop-1.2.1
在PATH后面添加$HADOOP_HOME/bin以:隔开,如下
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin
:$HADOOP_HOME/bin
:$PATH
然后使文件生效:source /etc/profile
--添加Hadoop配置,修改如下文件:
切换到Hadoop安装路径
$ cd /opt/hadoop/hadoop-1.2.1/conf
$ ls -l
需要修改的配置文件如下标注
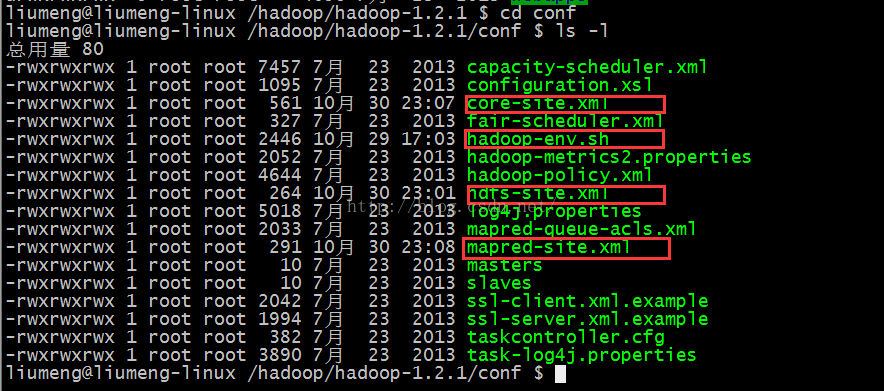
清单:1,hadoop-env.sh
2,core-site.xml
3, hdfs-site.xml
4,mapred-site.xml
添加配置如下:
(1)hadoop-env.sh
$ vim hadoop-env.sh
将export JAVA_HOME设置为系统jdk安装路径

(2)core-site.xml
$ vim core-site.xml
添加如下:
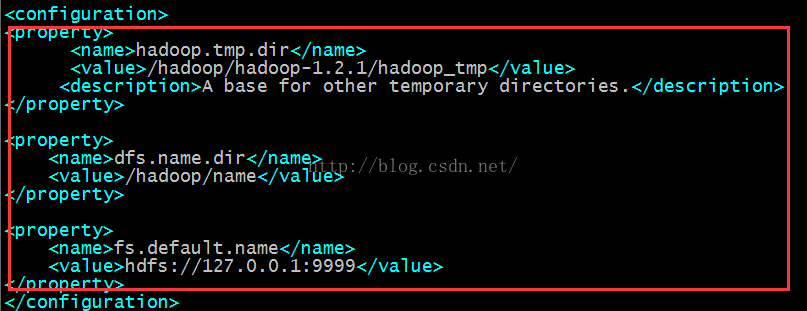
<property>
<name>hadoop.tmp.dir</name>
<value>/hadoop/hadoop-1.2.1/hadoop_tmp</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<name>dfs.name.dir</name>
<value>/hadoop/name</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://127.0.0.1:9999</value>
</property>
(3) hdfs-site.xml
$ vim hdfs-site.xml
添加如下配置:
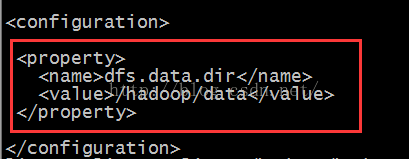
<property>
<name>dfs.data.dir</name>
<value>/hadoop/data</value>
</property>
(4)mapred-site.xml
$ vim mapred-site.xml
添加如下配置:
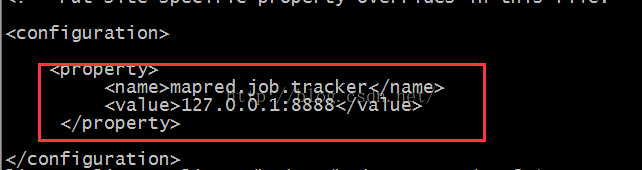
<property>
<name>mapred.job.tracker</name>
<value>127.0.0.1:8888</value>
</property>
(5)配置说明
core-site.xml与mapred-site.xml配置的端口不能一样,不然会出现host banding exception!
5、启动Hadoop
进入到Hadoop安装目录bin目录
$ cd /hadoop/hadoop-1.2.1/bin
$ ls -l
$ ./start-all.sh
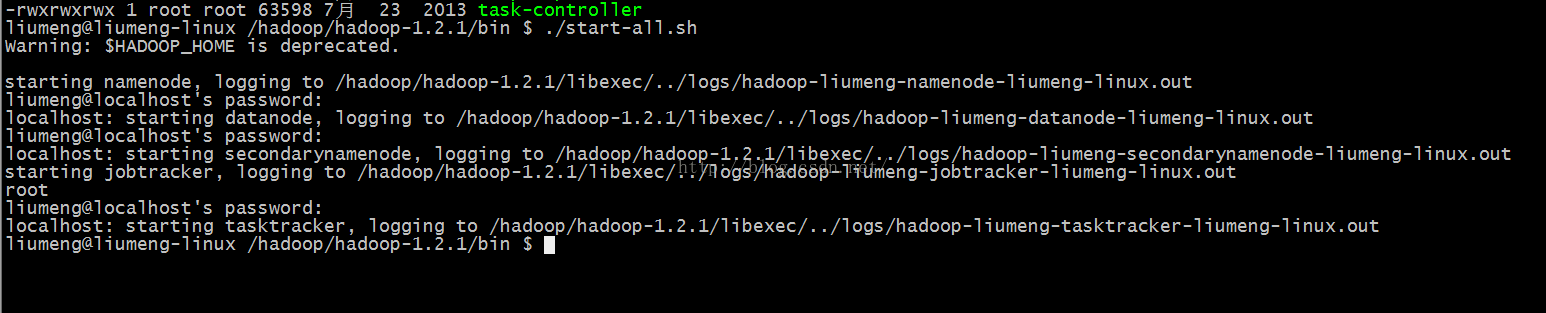
然后检查是否启动成功
$ jps
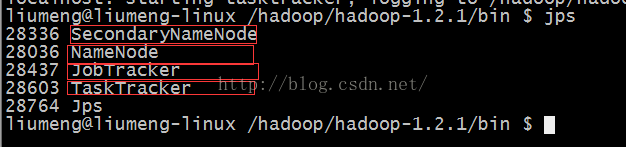
如果出现四个服务如下则代表Hadoop启动成功!
SecondaryNameNode
JobTracker
TaskTracker
注:启动过程中可能会有部分服务启动失败;在启动的时候会告诉我们服务启动的日志路径:如

查看日志文件:
$ cat /hadoop/hadoop-1.2.1/libexec/../logs/hadoop-liumeng-tasktracker-liumeng-linux.log
找到启动失败的原因吧。
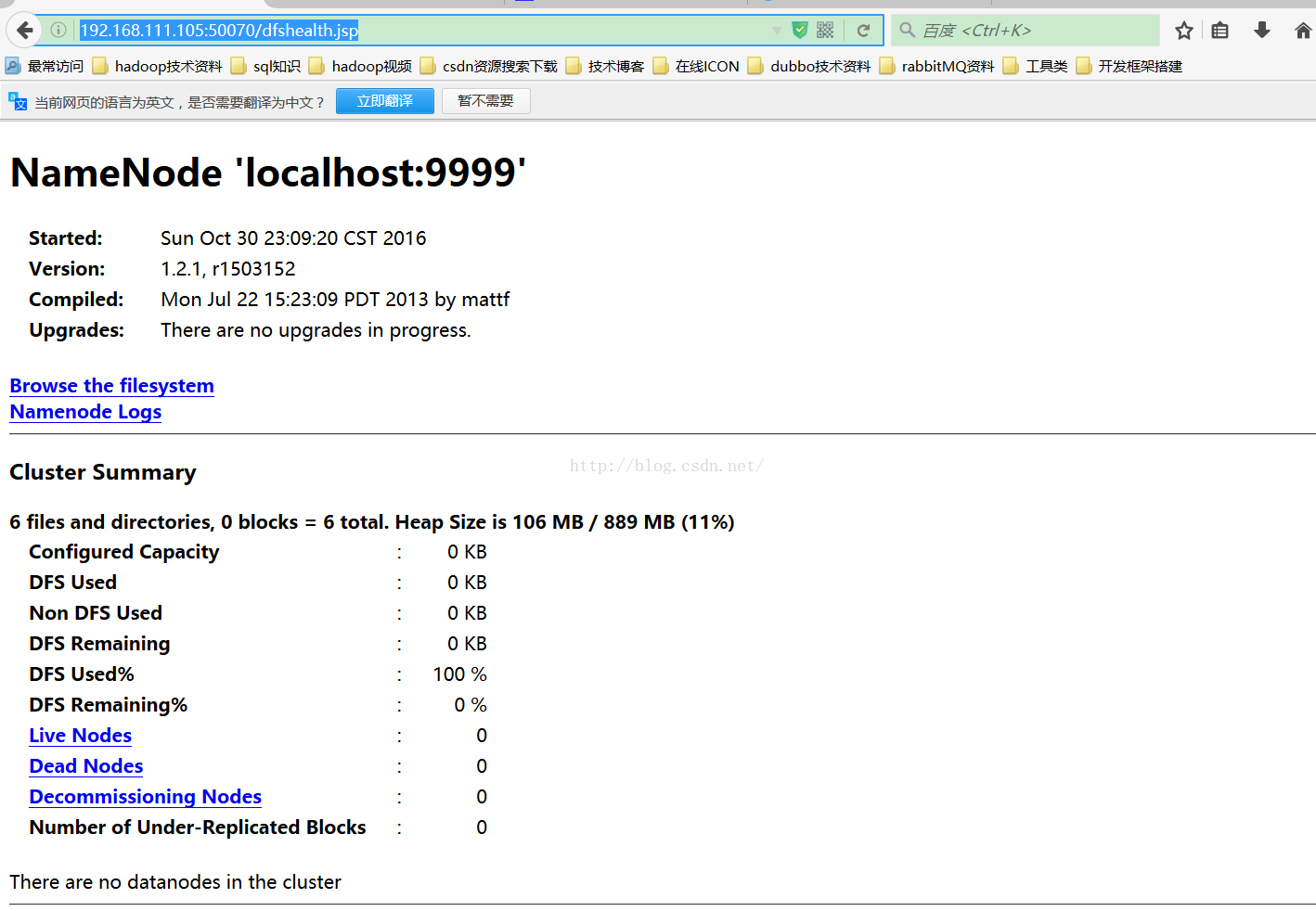
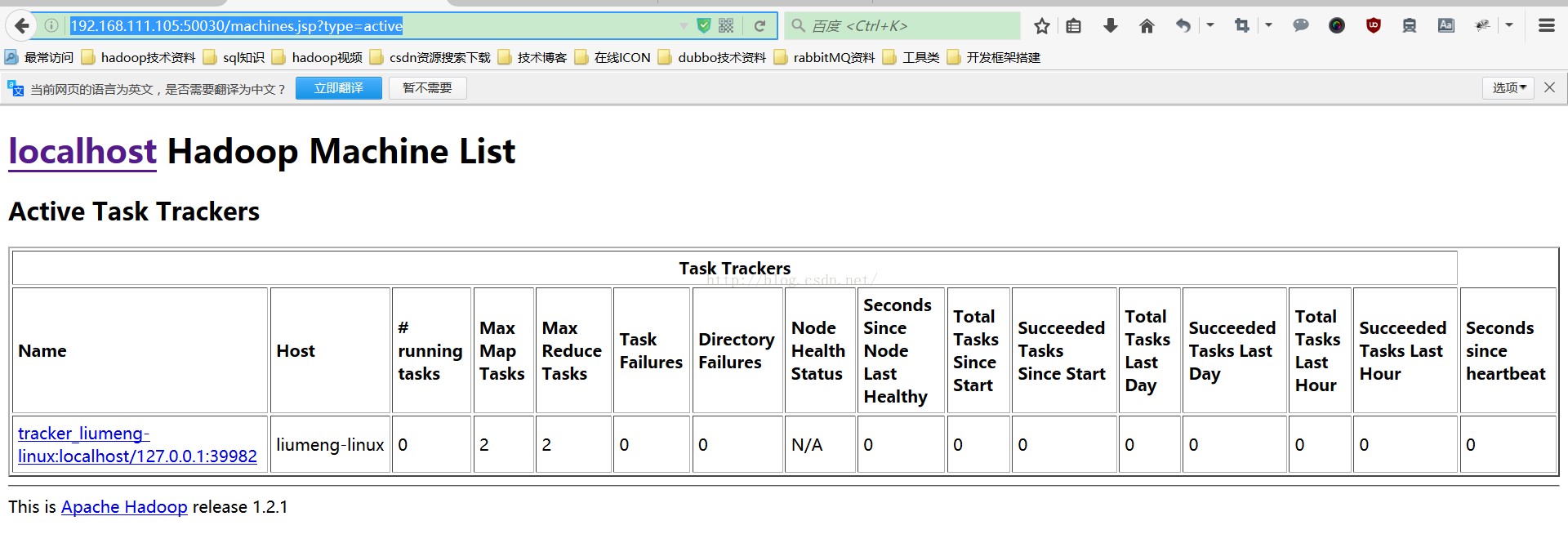
6、浏览器访问:
远程访问:














 467
467











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









