









网上还有很多解析xlsx 格式的开源库,但有不少是Java库。在pc端使用的。例如使用了javax.xml.stream.XMLStreamConstants。用poi库解析,是比较方便。对于合并单元格的解析都没有问题。有个缺点就是:库的太大的,总共加起来超过10M 这里面示例使用的是在github上面下的。是经过人为封装最后打包,变成两个库就可以的。poi最原始想法不是给Android 调用的。里面包含很多解析xlsx用不上的 jxl 只能解析03以下版本xls格式。不能解析07版本的xlsx格式。更新比较慢。但是库的很小,因为是针对Android使用的 网上还有还有一种解析方式就是这种解析方式,就是把xlsx格式的数据,用压缩包解压。然后去到解压目录xl文件夹,解析sharedStrings.xm即可只能解析很规范数据,没有合并单元格那种。如果有合并单元格,且数据放在合并单元格的中间,解析是会出问题的所以如果普通规范数据,进行每行每列显示解析不会有问题。如果有上下左右合并单元格。解析会出现错乱
1、图片展示
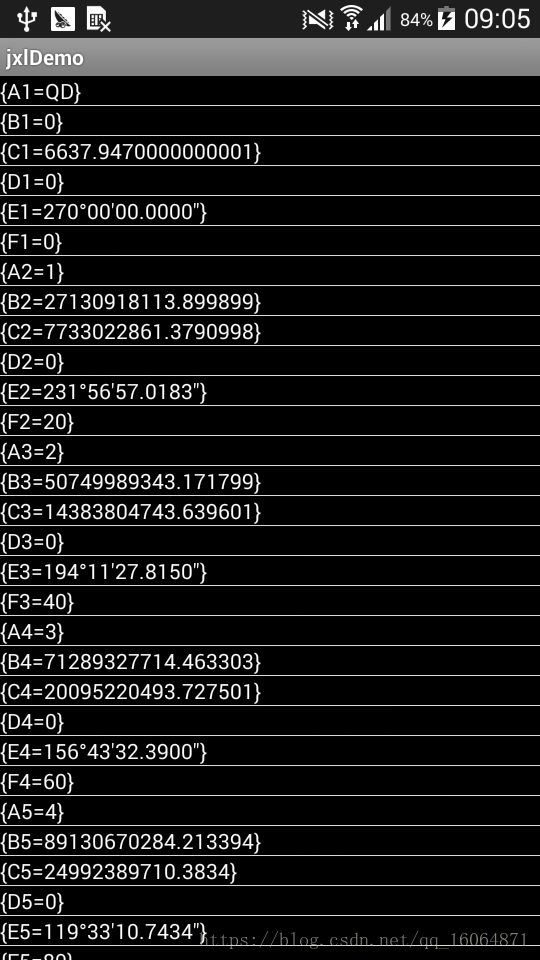
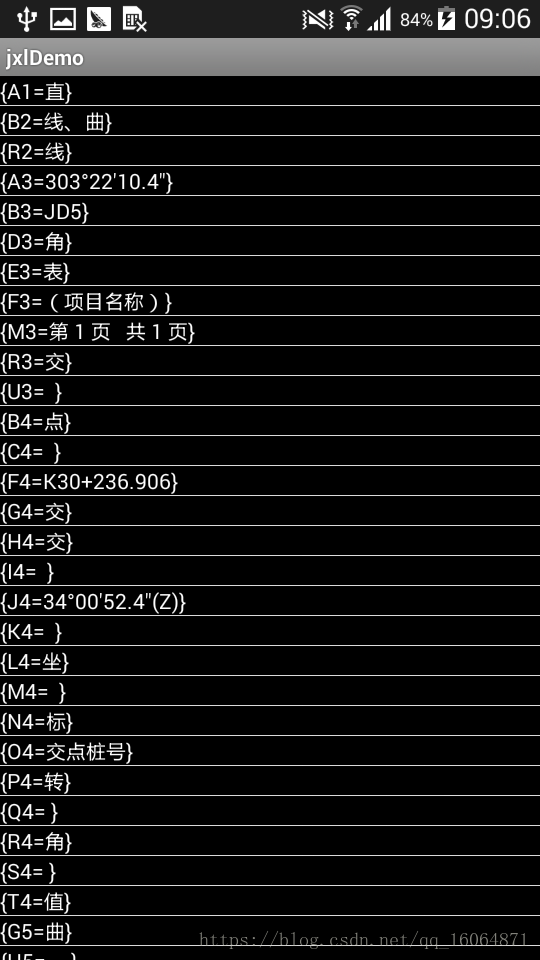
网上还有还有一种解析方式就是这种解析方式,就是把xlsx格式的数据,用压缩包解压。然后去到解压目录xl文件夹,解析sharedStrings.xm即可只能解析很规范数据,没有合并单元格那种。如果有合并单元格,且数据放在合并单元格的中间,解析是会出问题的所以如果普通规范数据,进行每行每列显示解析不会有问题。如果有上下左右合并单元格。解析会出现错乱

代码结构:
2、jxl解析
使用jxl解析,库很小,只能解析03的,不能解析07
package com.jxldemo.until;
import android.util.Log;
import android.util.Xml;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.NodeList;
import org.xmlpull.v1.XmlPullParser;
import java.io.File;
import java.io.InputStream;
import java.util.ArrayList;
import java.util.List;
import java.util.zip.ZipEntry;
import java.util.zip.ZipFile;
import javax.xml.parsers.DocumentBuilderFactory;
import jxl.Cell;
import jxl.CellType;
import jxl.DateCell;
import jxl.NumberCell;
import jxl.Sheet;
import jxl.Workbook;
public class ExcelUtils {
public static List<String[]> readExcel(String filePath) throws Exception {
return readExcel(filePath, 0);
}
public static List<String[]> readExcel(String filePath, int sheet) throws Exception {
if (filePath.trim().toLowerCase().endsWith(".xls")) {
return readXLS(new File(filePath), sheet);
} else {
return readXLSX(new File(filePath), sheet);
}
}
public static List<String[]> readXLS(File file, int sheetIndex) throws Exception {
List<String[]> list = new ArrayList<String[]>();
Workbook workbook = null;
try {
workbook = Workbook.getWorkbook(file);
Sheet sheet = workbook.getSheet(sheetIndex);
int columnCount = sheet.getColumns();
int rowCount = sheet.getRows();
for (int i = 0; i < rowCount; i++) {
String[] item = new String[columnCount];
for (int j = 0; j < columnCount; j++) {
Cell cell = sheet.getCell(j, i);
String str = "";
if (cell.getType() == CellType.NUMBER) {
str = ((NumberCell) cell).getValue() + "";
} else if (cell.getType() == CellType.DATE) {
str = "" + ((DateCell) cell).getDate();
} else {
str = "" + cell.getContents();
}
item[j] = str;
}
list.add(item);
}
} finally {
if (workbook != null)
workbook.close();
}
return list;
}
// 读取文件内容并且解析
//只能解析很规范数据,没有合并单元格那种。如果有合并单元格,且数据放在合并单元格的中间,解析是会出问题的
//这种解析方式,就是把xlsx格式的数据,用压缩包解压。然后去到解压目录xl文件夹,解析sharedStrings.xml即可
//所以如果普通规范数据,进行每行每列显示解析不会有问题。如果有上下左右合并单元格。解析会出现错乱
public static List<String[]> readXLSX(File file, int sheet) throws Exception {
List<String[]> list = new ArrayList<String[]>();
ArrayList<String> item = new ArrayList<String>();
String v = null;
boolean flat = false;
List<String> ls = new ArrayList<String>();
ZipFile xlsxFile = new ZipFile(file);
ZipEntry sharedStringXML = xlsxFile
.getEntry("xl/sharedStrings.xml");
InputStream inputStream = xlsxFile.getInputStream(sharedStringXML);
XmlPullParser xmlParser = Xml.newPullParser();
xmlParser.setInput(inputStream, "utf-8");
int evtType = xmlParser.getEventType();
while (evtType != XmlPullParser.END_DOCUMENT) {
switch (evtType) {
case XmlPullParser.START_TAG:
String tag = xmlParser.getName();
if (tag.equalsIgnoreCase("t")) {
ls.add(xmlParser.nextText());
}
break;
case XmlPullParser.END_TAG:
break;
default:
break;
}
evtType = xmlParser.next();
}
ZipEntry sheetXML = xlsxFile.getEntry("xl/worksheets/sheet" + (sheet + 1) + ".xml");
InputStream inputStreamsheet = xlsxFile.getInputStream(sheetXML);
XmlPullParser xmlParsersheet = Xml.newPullParser();
xmlParsersheet.setInput(inputStreamsheet, "utf-8");
int evtTypesheet = xmlParsersheet.getEventType();
while (evtTypesheet != XmlPullParser.END_DOCUMENT) {
switch (evtTypesheet) {
case XmlPullParser.START_TAG:
String tag = xmlParsersheet.getName();
if (tag.equalsIgnoreCase("row")) {
} else if (tag.equalsIgnoreCase("c")) {
String t = xmlParsersheet.getAttributeValue(null, "t");
if (t != null) {
flat = true;
System.out.println(flat + "有");
} else {
System.out.println(flat + "没有");
flat = false;
}
} else if (tag.equalsIgnoreCase("v")) {
v = xmlParsersheet.nextText();
if (v != null) {
if (flat) {
item.add(ls.get(Integer.parseInt(v)));
} else {
item.add(v);
}
}
}
break;
case XmlPullParser.END_TAG:
if (xmlParsersheet.getName().equalsIgnoreCase("row")
&& v != null) {
list.add(item.toArray(new String[item.size()]));
item = new ArrayList<String>();
}
break;
}
evtTypesheet = xmlParsersheet.next();
}
return list;
}
// 读取文件内容并且解析
//只能解析很规范数据,没有合并单元格那种。如果有合并单元格,且数据放在合并单元格的中间,解析是会出问题的
//这种解析方式,就是把xlsx格式的数据,用压缩包解压。然后去到解压目录xl文件夹,解析sharedStrings.xml即可
//所以如果普通规范数据,进行每行每列显示解析不会有问题。如果有上下左右合并单元格。解析会出现错乱
public static void readxlsx2(File file) {
ZipFile xlsxFile;
try {
xlsxFile = new ZipFile(file);
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
ZipEntry sharedStringXML = xlsxFile
.getEntry("xl/sharedStrings.xml");
InputStream sharedStringXMLIS = xlsxFile
.getInputStream(sharedStringXML);
Document sharedString;
sharedString = dbf.newDocumentBuilder().parse(sharedStringXMLIS);
NodeList str = sharedString.getElementsByTagName("t");
String sharedStrings[] = new String[str.getLength()];
for (int n = 0; n < str.getLength(); n++) {
Element element = (Element) str.item(n);
sharedStrings[n] = element.getTextContent();
Log.i("Show", element.getTextContent());
}
ZipEntry workbookXML = xlsxFile.getEntry("xl/workbook.xml");
InputStream workbookXMLIS = xlsxFile.getInputStream(workbookXML);
Document doc = dbf.newDocumentBuilder().parse(workbookXMLIS);
NodeList nl = doc.getElementsByTagName("sheet");
for (int i = 0; i < nl.getLength(); i++) {
Element element = (Element) nl.item(i);
String name = element.getAttribute("name");
ZipEntry sheetXML = xlsxFile.getEntry("xl/worksheets/sheet" + (1) + ".xml");
// ZipEntry sheetXML = xlsxFile.getEntry("xl/worksheets/" + name.toLowerCase() + ".xml");
InputStream sheetXMLIS = xlsxFile.getInputStream(sheetXML);
Document sheetdoc = dbf.newDocumentBuilder().parse(sheetXMLIS);
NodeList rowdata = sheetdoc.getElementsByTagName("row");
for (int j = 0; j < rowdata.getLength(); j++) {
Element row = (Element) rowdata.item(j);
NodeList columndata = row.getElementsByTagName("c");
for (int k = 0; k < columndata.getLength(); k++) {
Element column = (Element) columndata.item(k);
NodeList values = column.getElementsByTagName("v");
Element value = (Element) values.item(0);
if (column.getAttribute("t") != null
& column.getAttribute("t").equals("s")) {
String textContent = value.getTextContent();
String shared = columndata.item(k).getNodeName();
Log.i("Show", textContent + " , " + shared);
// System.out.print(sharedStrings[Integer
// .parseInt(value.getTextContent())] + " ");
} else {
if (value != null) {
System.out.print(value.getTextContent() + " ");
} else {
System.out.println("j : " + j + " k : " + k
+ " null");
}
}
}
System.out.println();
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
3、poi 解析
使用poi库解析,库比较大,03和07都能解析
package com.jxldemo;
import android.app.Activity;
import android.content.Context;
import android.content.Intent;
import android.net.Uri;
import android.os.Bundle;
import android.view.View;
import android.widget.EditText;
import com.jxldemo.R;
import java.io.File;
import java.io.FileOutputStream;
import java.io.InputStream;
import java.io.OutputStream;
import java.text.SimpleDateFormat;
import org.apache.poi.hssf.usermodel.HSSFDateUtil;
import org.apache.poi.ss.usermodel.Cell;
import org.apache.poi.ss.usermodel.CellValue;
import org.apache.poi.ss.usermodel.FormulaEvaluator;
import org.apache.poi.ss.usermodel.Row;
import org.apache.poi.ss.util.WorkbookUtil;
import org.apache.poi.xssf.usermodel.XSSFSheet;
import org.apache.poi.xssf.usermodel.XSSFWorkbook;
public class POIMainActivity extends Activity {
EditText output;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main_1);
output = (EditText) findViewById(R.id.textOut);
}
/**
* 用poi库解析,是比较方便。对于合并单元格的解析都没有问题。
* 有个缺点就是:库的太大的,总共加起来超过10M
* 这里面示例使用的是在github上面下的。是经过人为封装最后打包,变成两个库就可以的。
*
* poi最原始想法不是给Android 调用的。里面包含很多解析xlsx用不上的
*/
public void onReadClick(View view) {
printlnToUser("reading XLSX file from resources");
InputStream stream = getResources().openRawResource(R.raw.test1);
try {
XSSFWorkbook workbook = new XSSFWorkbook(stream);
XSSFSheet sheet = workbook.getSheetAt(0);
int rowsCount = sheet.getPhysicalNumberOfRows();
FormulaEvaluator formulaEvaluator = workbook.getCreationHelper().createFormulaEvaluator();
for (int r = 0; r<rowsCount; r++) {
Row row = sheet.getRow(r);
int cellsCount = row.getPhysicalNumberOfCells();
for (int c = 0; c<cellsCount; c++) {
String value = getCellAsString(row, c, formulaEvaluator);
String cellInfo = "r:"+r+"; c:"+c+"; v:"+value;
printlnToUser(cellInfo);
}
}
} catch (Exception e) {
/* proper exception handling to be here */
// printlnToUser(e.toString());
}
}
public void onWriteClick(View view) {
printlnToUser("writing xlsx file");
XSSFWorkbook workbook = new XSSFWorkbook();
XSSFSheet sheet = workbook.createSheet(WorkbookUtil.createSafeSheetName("mysheet"));
for (int i=0;i<10;i++) {
Row row = sheet.createRow(i);
Cell cell = row.createCell(0);
cell.setCellValue(i);
}
String outFileName = "filetoshare.xlsx";
try {
printlnToUser("writing file " + outFileName);
File cacheDir = getCacheDir();
File outFile = new File(cacheDir, outFileName);
OutputStream outputStream = new FileOutputStream(outFile.getAbsolutePath());
workbook.write(outputStream);
outputStream.flush();
outputStream.close();
printlnToUser("sharing file...");
share(outFileName, getApplicationContext());
} catch (Exception e) {
/* proper exception handling to be here */
printlnToUser(e.toString());
}
}
protected String getCellAsString(Row row, int c, FormulaEvaluator formulaEvaluator) {
String value = "";
try {
Cell cell = row.getCell(c);
CellValue cellValue = formulaEvaluator.evaluate(cell);
switch (cellValue.getCellType()) {
case Cell.CELL_TYPE_BOOLEAN:
value = ""+cellValue.getBooleanValue();
break;
case Cell.CELL_TYPE_NUMERIC:
double numericValue = cellValue.getNumberValue();
if(HSSFDateUtil.isCellDateFormatted(cell)) {
double date = cellValue.getNumberValue();
SimpleDateFormat formatter =
new SimpleDateFormat("dd/MM/yy");
value = formatter.format(HSSFDateUtil.getJavaDate(date));
} else {
value = ""+numericValue;
}
break;
case Cell.CELL_TYPE_STRING:
value = ""+cellValue.getStringValue();
break;
default:
}
} catch (NullPointerException e) {
/* proper error handling should be here */
printlnToUser(e.toString());
}
return value;
}
/**
* print line to the output TextView
* @param str
*/
private void printlnToUser(String str) {
final String string = str;
if (output.length()>8000) {
CharSequence fullOutput = output.getText();
fullOutput = fullOutput.subSequence(5000,fullOutput.length());
output.setText(fullOutput);
output.setSelection(fullOutput.length());
}
output.append(string+"\n");
}
public void share(String fileName, Context context) {
Uri fileUri = Uri.parse("content://"+getPackageName()+"/"+fileName);
printlnToUser("sending "+fileUri.toString()+" ...");
Intent shareIntent = new Intent();
shareIntent.setAction(Intent.ACTION_SEND);
shareIntent.putExtra(Intent.EXTRA_STREAM, fileUri);
shareIntent.setType("application/octet-stream");
startActivity(Intent.createChooser(shareIntent, getResources().getText(R.string.send_to)));
}
}
4、手动解析读取文件内容并且解析
只能解析很规范数据,没有合并单元格那种。如果有合并单元格,且数据放在合并单元格的中间,解析是会出问题的
这种解析方式,就是把xlsx格式的数据,用压缩包解压。然后去到解压目录xl文件夹,解析sharedStrings.xml即可
所以如果普通规范数据,进行每行每列显示解析不会有问题。如果有上下左右合并单元格。解析会出现错乱
package com.jxldemo.until;
/**
*/
import android.util.Xml;
import org.json.JSONArray;
import org.json.JSONException;
import org.json.JSONObject;
import org.xmlpull.v1.XmlPullParser;
import org.xmlpull.v1.XmlPullParserException;
import java.io.File;
import java.io.IOException;
import java.io.InputStream;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.zip.ZipEntry;
import java.util.zip.ZipException;
import java.util.zip.ZipFile;
import jxl.Cell;
import jxl.Sheet;
import jxl.Workbook;
public class XLSXParse {
private String _armStr;
private OutFileType _outFileType;
private String _spiltStr;
private ArmFileType _armFileType;
public XLSXParse() {
}
public XLSXParse(Builder builder) {
this._armStr = builder._armStr;
this._outFileType = builder._outFileType;
this._spiltStr = builder._spiltStr;
this._armFileType =builder._armFileType;
}
// 定义最后输出的数据类型
public enum OutFileType{
FILE_TYPE_JSON,//json格式输出
FILE_TYPE_SPILT,//分隔符字符串输出
FILE_TYPE_LIST,//直接输出List类型数据
FILE_TYPE_ARRAY//输出字符串型二位数组
}
public enum ArmFileType{
XLS,
XLSX
}
//构建这模式,生成器设计模式
public static class Builder {
private String _armStr = null;
private OutFileType _outFileType;
private String _spiltStr;
private ArmFileType _armFileType;
public Builder() {
this._spiltStr="|";
this._outFileType=OutFileType.FILE_TYPE_LIST;
}
public Builder(String armFilePath,String split,OutFileType fileType) {
this._armStr=armFilePath;
this._spiltStr=split;
this._outFileType=fileType;
}
//设置以什么格式输出
public Builder setOutFileType(OutFileType outFileType){
this._outFileType=outFileType;
return this;
}
// 设置要解析的XLSX文件路径,其中带文件名
public Builder setArmFilePath(String armFilePath) {
this._armStr = armFilePath;
return this;
}
public Builder setSplitString(String splitString){
this._spiltStr=splitString;
return this;
}
public Builder setArmFileType(ArmFileType armFileType){
this._armFileType = armFileType;
return this;
}
public XLSXParse build() {
return new XLSXParse(this);
}
}
//
private void judgeArmFileType(){
String type=this._armStr.substring(this._armStr.lastIndexOf(".")+1);
if(type!=null){
if(type.equals("xlsx")){
this._armFileType = ArmFileType.XLSX;
}else if(type.equals("xls")){
this._armFileType = ArmFileType.XLS;
}
}
}
public Object parseFile(){
judgeArmFileType();
Object arm=null;
switch (this._armFileType){
case XLSX:
arm = parseXLSX();
break;
case XLS:
arm = parseXLS();
break;
}
return arm;
}
/**
* 开始处理xlsx,根据设置返回相应的数据
* 1?? JSON格式的字符串
* 2?? List数据
* 3?? 用指定字符隔开的字符串
* @return
*/
private Object parseXLSX(){
List<Map<String,String>> list = readXLSX();
Object armObj=null;
if(list.size()>0){
switch (this._outFileType){
case FILE_TYPE_JSON:
armObj = new JSONArray(list);
break;
case FILE_TYPE_LIST:
armObj = list;
break;
case FILE_TYPE_SPILT:
StringBuilder sb=new StringBuilder();
for (int i = 0; i <list.size() ; i++) {
Map<String,String> map =list.get(i);
for (Map.Entry entry : map.entrySet()) {
Object key = entry.getKey();
sb.append(key+":"+map.get(key)+this._spiltStr);
}
}
sb.deleteCharAt(sb.toString().trim().length() - 1);
armObj=sb.toString();
break;
case FILE_TYPE_ARRAY:
break;
}
}
return armObj;
}
// 读取文件内容并且解析
//只能解析很规范数据,没有合并单元格那种。如果有合并单元格,且数据放在合并单元格的中间,解析是会出问题的
//这种解析方式,就是把xlsx格式的数据,用压缩包解压。然后去到解压目录xl文件夹,解析sharedStrings.xml即可
//所以如果普通规范数据,进行每行每列显示解析不会有问题。如果有上下左右合并单元格。解析会出现错乱
private List<Map<String,String>> readXLSX() {
List<Map<String,String>> armList=new ArrayList<>();
String str = "";
String v = null;
boolean flat = false;
List<String> ls = new ArrayList<String>();
try {
File file =new File(this._armStr);
ZipFile xlsxFile = new ZipFile(file);
ZipEntry sharedStringXML = xlsxFile
.getEntry("xl/sharedStrings.xml");
InputStream inputStream = xlsxFile.getInputStream(sharedStringXML);
XmlPullParser xmlParser = Xml.newPullParser();
xmlParser.setInput(inputStream, "utf-8");
int evtType = xmlParser.getEventType();
while (evtType != XmlPullParser.END_DOCUMENT) {
switch (evtType) {
case XmlPullParser.START_TAG:
String tag = xmlParser.getName();
if (tag.equalsIgnoreCase("t")) {
ls.add(xmlParser.nextText());
}
break;
case XmlPullParser.END_TAG:
break;
default:
break;
}
evtType = xmlParser.next();
}
ZipEntry sheetXML = xlsxFile.getEntry("xl/worksheets/sheet1.xml");
InputStream inputStreamsheet = xlsxFile.getInputStream(sheetXML);
XmlPullParser xmlParsersheet = Xml.newPullParser();
xmlParsersheet.setInput(inputStreamsheet, "utf-8");
int evtTypesheet = xmlParsersheet.getEventType();
String r="";
while (evtTypesheet != XmlPullParser.END_DOCUMENT) {
switch (evtTypesheet) {
case XmlPullParser.START_TAG:
// 获取文件中的各个节点
String tag = xmlParsersheet.getName();
/**
* 判断各个节点的值属于哪一类
*/
if (tag.equalsIgnoreCase("row")) {// 如果xlsx读取到的节点值为row
} else if (tag.equalsIgnoreCase("c")) {// 如果xlsx读取到的节点值为c
String t = xmlParsersheet.getAttributeValue(null, "t");
r= null;
r = xmlParsersheet.getAttributeValue(null, "r");
if (t != null) {
flat = true;
} else {
flat = false;
}
} else if (tag.equalsIgnoreCase("v")) {
v = xmlParsersheet.nextText();
if (v != null) {
Map<String, String> map = new HashMap<>();
if (flat) {
str = ls.get(Integer.parseInt(v)) + "";
}else{
str = v+"";
}
map.put(r, str);
armList.add(map);
}
}
break;
case XmlPullParser.END_TAG:
break;
}
evtTypesheet = xmlParsersheet.next();
}
} catch (ZipException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} catch (XmlPullParserException e) {
e.printStackTrace();
}
return armList;
}
/**
* 开始处理xls,根据设置返回相应的数据
* 1?? JSON格式的字符串
* 2?? List数据
* 3?? 用指定字符隔开的字符串
* 4?? 二维数组
* @return
*/
private Object parseXLS(){
String[][] data = readXLS();
Object armObj=null;
if(data.length>0){
switch (this._outFileType){
case FILE_TYPE_JSON:
JSONArray arm =new JSONArray();
for (int i = 0; i <data.length ; i++) {
JSONObject jsonArr=new JSONObject();
for(int j=0;j<data[i].length;j++){
try {
jsonArr.put(i+"_"+j,data[i][j]);
} catch (JSONException e) {
e.printStackTrace();
}
}
arm.put(jsonArr);
}
armObj = arm;
break;
case FILE_TYPE_LIST:
ArrayList<Map<String,String>> list =new ArrayList<>();
for (int i = 0; i <data.length ; i++) {
Map<String,String> map=new HashMap<>();
for (int j=0;j<data[i].length;j++){
map.put(i+"_"+j,data[i][j]);
list.add(map);
}
}
armObj = list;
break;
case FILE_TYPE_SPILT:
StringBuilder sb=new StringBuilder();
for (int i = 0; i <data.length ; i++) {
for (int j=0;j<data[i].length;j++){
sb.append(i+"_"+j+":"+data[i][j]+this._spiltStr);
}
}
sb.deleteCharAt(sb.toString().trim().length() - 1);
armObj=sb.toString();
break;
case FILE_TYPE_ARRAY:
armObj =data;
break;
}
}
return armObj;
}
//读取xls文件内容
public String[][] readXLS() {
String[][]data=null;
try {
Workbook workbook = null;
try {
File file=new File(this._armStr);
workbook = Workbook.getWorkbook(file);
} catch (Exception e) {
throw new Exception("File not found");
}
//得到第一张表
Sheet sheet = workbook.getSheet(0);
//列数
int columnCount = sheet.getColumns();
//行数
int rowCount = sheet.getRows();
if(columnCount>0&&rowCount>0){
data=new String[rowCount][columnCount];
//单元格
Cell cell = null;
for (int everyRow = 0; everyRow < rowCount; everyRow++) {
for (int everyColumn = 0; everyColumn < columnCount; everyColumn++) {
cell = sheet.getCell(everyColumn, everyRow);
data[everyRow][everyColumn]=cell.getContents().trim();
}
}
}
//关闭workbook,防止内存泄露
workbook.close();
} catch (Exception e) {
}
return data;
}
}
5、权限
<uses-permission android:name="android.permission.READ_EXTERNAL_STORAGE" />
<uses-permission android:name="android.permission.WRITE_EXTERNAL_STORAGE" />














 1198
1198











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









