







Shuffle解密
0. 准备阶段
0.1 简介
- Map的输出会经过一个名为shuffle的过程,交给Reduce处理。
- 在MapReduce流程中,为了让Reduce可以并行处理Map结果,必须对Map的输出进行一定的排序和分割,然后再交给对应的Reduce,而这个将Map输出进行进一步整理并交给Reduce的过程就是shuffle。
- shuffle是MapReduce的核心所在,shuffle过程的性能与整个MapReduce的性能直接相关。
- Shuffle过程是MapReduce的核心。
- 总体来说,shuffle过程包含在Map和Reduce两端中。
- 在Map端的shuffle过程是对Map的结果进行分区(partition)、排序(sort)和分割(spill),然后将属于同一个划分的输出合并(merge)在一起并写在磁盘上,同时按照不同的划分将结果发送给对应的Reduce。Map输出的划分与Reduce的对应关系由JobTracker确定。
- Reduce端又会将各个Map送来的属于同一个划分的输出进行合并(merge),然后对merge的结果进行排序,最后交给Reduce处理。
0.2 什么是Shuffle?
- Shuffle的本义是洗牌、混洗,把一组有一定规则的数据尽量转换成一组无规则的数据,越随机越好。
- MR中的Shuffle更像是洗牌的逆过程,把一组无规则的数据尽量转换成一组具有一定规则的数据。
0.3 Shuffle的大致范围到底是什么?
- 怎样把map task的输出结果有效地传送到reduce端。
- 也可以这样理解,Shuffle描述的是: 数据从map task输出到reduce task输入的这段过程。
1 Shuffle解密
1.1 见怪不怪的Shuffle流程图
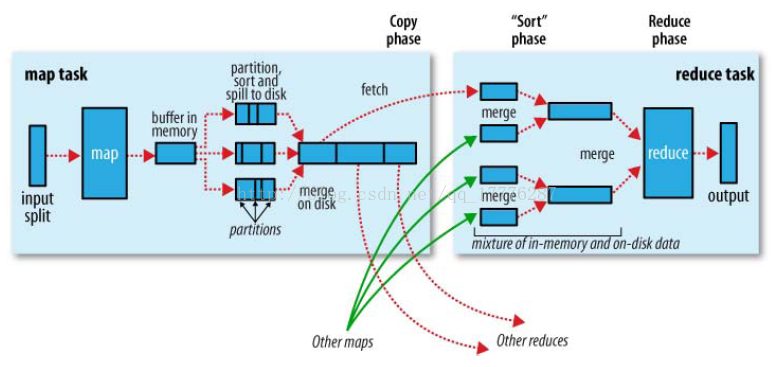
相信接触大数据的时候,都已经看到过这张图。
这个只是简单描述了MR作业的执行步骤,但是,我更青睐于下图:
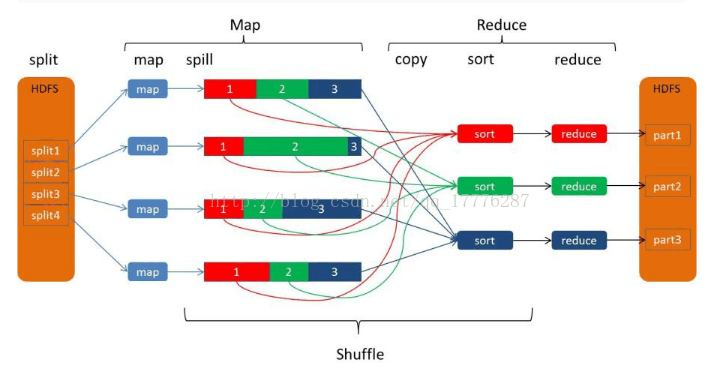
如图所示,Shuffle横跨Map端和Reduce端。
宏观上,Hadoop每个作业要经历两个阶段:Map phase和Reduce phase。
对于Map phase,由主要包括四个子阶段:从磁盘上读数据 ——> 执行map函数 ——> combine结果 ——> 将结果写到本地磁盘上;
对于Reduce phase,同样包括四个子阶段:从各个map task上读相应的数据(shuffle) ——> sort ——> 执行reduce函数 ——> 将结果写到HDFS中。
1.2 Map端
(1)在map端首先接触的是InputSplit,在InputSplit中含有DataNode中的数据(即HDFS的block),每一个InputSplit都会分配一个map task(map task只读取split,Split与block的对应关系可能是多对一,默认是一对一)
(2)map task结束后产生<K2, V2>的输出,这些输出先存放在缓存中,每个map有一个环形内存缓冲区,用于存储任务的输出。默认大小100MB(io.sort.mb属性)
(3)当map task的输出结果很多时,就可能会撑爆内存,所以需要在一定条件下将缓存区中的数据临时写入磁盘,然后重新利用这块缓存区,这个从内存往磁盘写数据的过程被称为Spill(溢写)。
- 溢写是由单独的线程来完成,不影响往缓冲区写map结果的线程。
- 溢写线程启动时不应该阻止map的结果输出,所以整个缓冲区有个溢写比例 spill.percent(io.sort.spill.percent),这个比例默认是0.8(buffer size * spill percent = 100MB * 0.8 = 80MB)。
- 一旦达到阀值0.8(io.sort.spill.percent),一个后台线程就把内容写到(spill) Linux本地磁盘中的指定目录(mapred.local.dir)下的新建的一个溢写文件。
- 溢写线程启动,锁定80MB内存,执行溢写过程。map task的输出结果还可以往剩下的20MB内存中写,互不影响。
写磁盘前,需要进行partition、sort和combine等操作。
- map task的输出是需要发送到不同的reduce端去,而内存缓冲区没有对将发送到相同reduce端的数据做合并,那么合并操作应该是体现在磁盘文件中的。
- 磁盘中的溢写文件是对不同的reduce端的数据进行合并操作。所以,溢写过程一个很重要的细节在于:如果有很多个key/value对需要发送到某个reduce端去,那么需要把他们的值拼接到一块,减少与partition相关的索引记录。
Note:
通过分区,将不同类型的数据分开处理,之后对不同分区的数据进行排序,如果有Combiner,还要对排序后的数据进行combine。等最后记录写完,将全部溢出文件合并为一个分区且排序的文件。
补充:
- Combiner的输出是Reducer的输入,Combiner绝不能改变最终的计算结果。所以,Combiner只应该用于那种Reduce的输入key/value与输出key/value类型完全一致,且不影响最终结果的场景。比如:累加,求最大值等。
- Combiner的使用一定要慎重,如果用好了,它对job执行效率有帮助,繁殖会影响reduce的最终结果。
(4)当map task真正完成时,内存缓冲区中的数据也全部溢写到磁盘中形成一个溢写文件。最终磁盘中会只要有一个这样的溢写文件存在,因为最终的文件只有一个,所以需要将这些溢写文件归并到一起,这个过程就叫做Merge。
1.3 Reduce端
Reducer真正运行之前,所有的时间都是在拉取数据,做merge,切不断重复地做。
(1)Copy阶段
Reduce进程启动一些数据copy线程(Fetcher),通过HTTP方式请求map task所在的TaskTracker获取map task的输出文件。因为map task早已结束,这些文件就归TaskTracker管理在本地磁盘中。
(2)Merge阶段
Copy过来的数据会先放入内存缓冲区中,这里的缓冲区大小要比map端的更为灵活,它基于JVM的heap size设置,因为Shuffle阶段Reducer不执行,所以应该把绝大部分的内存都给Shuffle用。
补充:
merger有三种形式:a) 内存到内存,b) 内存到磁盘, c) 磁盘到磁盘
- 默认情况下第一种形式不启用。
- 当内存中的数据量达到一定阀值,就启动内存到磁盘的merge。与map端类似,这要是溢写的过程,这个过程中,如果你设置有Combiner,也是会启动的,然后在磁盘中生成众多的溢写文件。
- 第二种方式一直在运行,直到没有map端的数据时才结束,然后启动第三种merge方式生成最终的那个文件。
- 最后一次合并的结果作为reduce的输入而不是写入到磁盘中。
(3)Reducer的输入文件。
不断地merge后,最后生成一个“最终文件”,这个文件可能存在于磁盘中,也可能存在于内存中。对我们来说,当然希望它存放在内存中,直接作为Reducer的输入。但默认情况下,这个文件是存在磁盘中的。(针对如何让这个文件存放在内存中,我会在后续的性能优化博文中介绍,这里专注于Shuffle)
当Reducer的输入文件已定,整个Shuffle才最终结束。然后就是Reducer执行,把结果放到HDFS上。
2 Hadoop中的压缩
Hadoop处理流程中的两个子阶段严重降低了其性能。第一个是map阶段产生的中间结果要写到磁盘上,这样做的主要目的是提高系统的可靠性,但代价是降低了系统的性能,实际上,Hadoop的改进版—MapReduce Online去除了这个阶段,而采用其他更高效的方式提高系统可靠性(见参考资料[1]);另一个是shuffle阶段采用HTTP协议从各个map task上远程拷贝结果,这种设计思路(远程拷贝,协议采用HTTP)同样降低了系统性能。实际上,Baidu公司正试图将该部分代码替换成C++代码来提高性能(见参考资料[2])。
在写磁盘的时候采用压缩的方式将map的输出结果进行压缩是一个减少网络开销很有效的方法!
2.1 Hadoop支持的压缩格式
Splitable: 表示压缩格式是否可以被分割,也就是说是否支持随机读。压缩数据是否能被mapreduce使用,压缩数据是否能被分割就很关键了。
2.2 压缩格式的特征比较
以下仅针对Hadoop中用得比较多的压缩格式:lzo, gzip, snappy, bzip2进行比较
2.3 Codec实现类

org.apache.hadoop.io.compress
CompressionCodec是压缩和解压缩的接口。以下是该接口的实现类:

(1)MR输出属性:

(2)Java代码设置压缩输出:
package compression;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.io.compress.CompressionOutputStream;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.util.ReflectionUtils;
public class CompressionExample {
public static void main(String[] args) throws IOException, ClassNotFoundException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "Codec");
job.setJarByClass(CompressionExample.class);
String codecClassName = "org.apache.hadoop.io.compress.BZip2Codec";
// String codecClassName = "org.apache.hadoop.io.compress.GzipCodec";
Class<?> cls = Class.forName(codecClassName);
CompressionCodec codec = (CompressionCodec) ReflectionUtils.newInstance(cls, conf);
String inputFile = "/tmp/data";
String outFile = inputFile + codec.getDefaultExtension();
FileOutputStream fos = new FileOutputStream(outFile);
CompressionOutputStream out = codec.createOutputStream(fos);
FileInputStream in = new FileInputStream(inputFile);
IOUtils.copyBytes(in, out, 4096, false);
in.close();
out.close();
}
}
如下方式亦可:

2.4 如何选择压缩算法?
(1)用一些包含了压缩并且支持splittable的文件格式,比如SequenceFile, RCFile或者Avro文件
(2)使用提供了splittable的压缩格式,比如: bzip2和索引后可以支持splittable的lzo
(3)提前把文件分成几个块,每个块单独压缩,这样就无需考虑splittable的问题了
(4)不要压缩文件,已不支持splittable的压缩格式存储一个很大的数据文件是不合适的,非本地处理效率会非常之低
Summary
1、什么是Shuffle? 针对多个map task的输出按照不同的分区(Partition)通过网络复制到不同的reduce task节点上的过程。
这一阶段是Hadoop中最核心的部分,因为涉及到Hadoop中最珍贵的网络资源,所以shuffle过程中会有很多可以调节的参数,也有很多策略可以研究。
2、主要有两个方面影响shuffle阶段的性能:
(1)数据完全是远程拷贝
(2)采用HTTP协议进行数据传输。
对于第一个方面,如果采用某种策略(修改框架),让reduce task也能有locality就好了;
对于第二个方面,用新的更快的数据传输协议替换掉HTTP,也许能更快些,如UDT协议(见参考材料[3]),它在MR的另一个C++开源实现Sector/Sphere(见参考材料[4])中被使用,效果不错!
3、map过程的输出是写入本地磁盘而不是HDFS,但是一开始数据并不是直接写入磁盘而是缓冲在内存中,缓存的好处是减少磁盘I/O的开销,提高合并和排序的速度。又因为默认的内存缓冲大小是100MB(可以配置),所以在编写map函数时要尽量减少内存的使用,为shuffle过程预留更多的内存,因为该过程是最耗时的过程。
【参考资料】
[5] 董西成,《Hadoop中shuffle阶段流程分析》: http://dongxicheng.org/mapreduce/hadoop-shuffle-phase/















 276
276











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











