







 本文介绍了如何使用BloomFilter进行大数据去重,并结合Redis的Bitmap实现持久化,以解决ElasticSearch去重导致的性能问题。讨论了BloomFilter的原理、优缺点以及关键公式,最后提供了结合Redis的实现方案。
本文介绍了如何使用BloomFilter进行大数据去重,并结合Redis的Bitmap实现持久化,以解决ElasticSearch去重导致的性能问题。讨论了BloomFilter的原理、优缺点以及关键公式,最后提供了结合Redis的实现方案。
BloomFilter(大数据去重)+Redis(持久化)策略
背景
之前在重构一套文章爬虫系统时,其中有块逻辑是根据文章标题去重,原先去重的方式是,插入文章之前检查待插入文章的标题是否在ElasticSearch中存在,这无疑加重了ElasticSearch的负担也势必会影响程序的性能!
BloomFilter算法
- 简介:布隆过滤器实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
- 原理:当一个元素被加入集合时,通过K个散列函数将这个元素映射成一个位数组中的K个点,把它们置为1。检索时,我们只要看看这些点是不是都是1就(大约)知道集合中有没有它了:如果这些点有任何一个0,则被检元素一定不在;如果都是1,则被检元素很可能在。
- 优点:相比于其它的数据结构,布隆过滤器在空间和时间方面都有巨大的优势。布隆过滤器存储空间和插入/查询时间都是常数(O(k))。而且它不存储元素本身,在某些对保密要求非常严格的场合有优势。
- 缺点:一定的误识别率和删除困难。
结合以上几点及去重需求(容忍误判,会误判在,在则丢,无妨),决定使用BlomFilter。
思想
位数组和k个散列函数
- 位数组
初始状态时,BloomFilter是一个长度为m的位数组,每一位都置为0。
- 添加元素(k个独立的hash函数)
添加元素时,对x使用k个哈希函数得到k个哈希值,对m取余,对应的bit位设置为1。
判断元素是否存在
判断y是否属于这个集合,对y使用k个哈希函数得到k个哈希值,对m取余,所有对应的位置都是1,则认为y属于该集合(哈希冲突,可能存在误判),否则就认为y不属于该集合。
图中y1不是集合中的元素,y2属于这个集合或者是一个false positive。
BloomFilter有以下参数:- m 位数组的长度
- n 加入其中元素的数量
- k 哈希函数的个数
- f False Positive

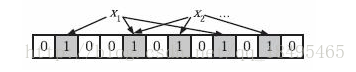
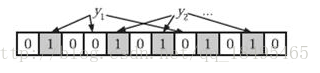
问题:如何根据输入元素个数n,确定位数组的大小m和哈希函数的个数k?
BloomFilter的f满足下列公式:
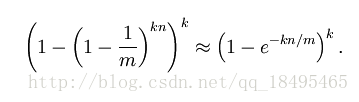
在给定m和n时,能够使f最小化的k值为:
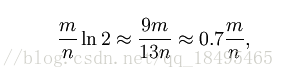
此时给出的f为:

根据以上公式,对于任意给定的f,我们有:
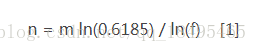
同时,我们需要k个hash来达成这个目标:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 30万+
30万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









