







这篇博客主要根据贺一加博客和svo论文来总结的。
对于svo我总结为3个步骤:
step1. Sparse directly Image Alignment
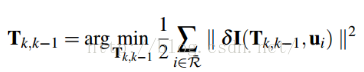
这个公式是直接法来求重投影残差的最小值。
上面的公式可也分为三个部分:第一步为根据图像位置和深度逆投影到三维空间,第二步将三维坐标点旋转平移到当前帧坐标系下(这里的旋转和平移T(k,k-1)就是优化变量),第三步再将三维坐标点投影回当前帧图像坐标
这里存在一个直接法的假设条件:在短时间内相邻两帧图像的相同像素点的亮度是不变的。
那么这个公式的目的就是:求T(k,k-1)的值使得I(k-1)帧和I(k)帧相同的特征块的亮度差最小。
step2. Feature Alignment
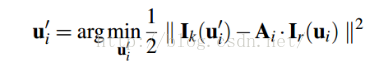
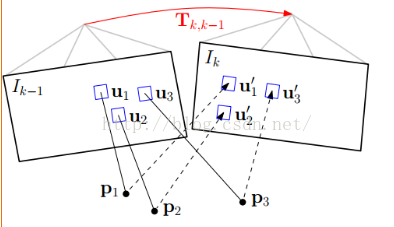
通过step1的帧间匹配能够得到当前帧相机的位姿,但是这种frame to frame估计位姿的方式不可避免的会带来累计误差从而导致漂移。所以,应该通过已经建立好的地图模型,来进一步约束当前帧的位姿。
首先看看svo的地图保存了些什么?
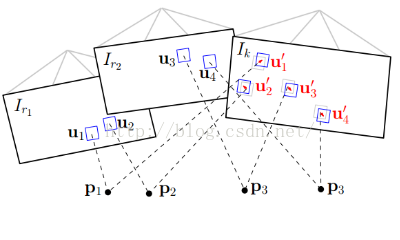
地图模型通常来说保存的就是三维空间点,因为每一个Key frame通过深度估计能够得到特征点的三维坐标,这些三维坐标点通过特征点在Key Frame中进行保存。所以SVO地图上保存的是Key Frame 以及还未插入地图的KF中的已经收敛的3d点坐标(这些3d点坐标是在世界坐标系下的),也就是说地图map不需要自己管理所有的3d点,它只需要管理KF就行了。先看看选取KF的标准是啥?KF中保存了哪些东西?当新的帧new frame和相邻KF的平移量超过场景深度平均值的12%时(比如四轴上升),new frame就会被当做KF,它会被立即插入地图。同时,又在这个新的KF上检测新的特征点作为深度估计的seed,这些seed会不断融合新的new frame进行深度估计。但是,如果有些seed点3d点位姿通过深度估计已经收敛了,怎么办?map用一个point_candidates来保存这些尚未插入地图中的点。所以map这个数据结构中保存了两样东西,以前的KF以及新的尚未插入地图的KF中已经收敛的3d点。
通过地图我们保存了很多三维空间点,很明显,每一个new frame都是可能看到地图中的某些点的。由于new frame的位姿通过上一步的直接法已经计算出来了,那么这些被看到的地图上的点可以被投影到这个new frame中了。由于位姿误差导致特征块在new frame中肯定不是真正的特征块所处的位置。所以需要Feature Alignment来找到地图中特征块在new frame中应该出现的位置,根据这个位置误差为进一步的优化做准备。基于光度不变性假设,特征块在以前参考帧中的亮度应该和new frame中的亮度差不多。所以可以重新构造一个残差,对特征预测位置进行优化即:
注意这里的优化变量是像素位置,这过程就是光流法跟踪嘛。并且注意,光度误差的前一部分是当前图像中的亮度值,后一部分不是 Ik−1
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









