







Spark-Scala-RDD 入门问题汇总
最近一段时间一直在了解Spark。作为初学者在这记录一些自己的新的,方便自己以后查看。
系统运行版本是:Hadoop 2.7.2 / Spark 2.0.0 / Scala 2.11.8
编辑器: IDEA
1:在Spark上如何运行程序
编写的程序必须打包并在终端运行。不能直接在编辑器上运行,这是因为程序运行的时没有提交给spark集群。
2:搭建开发环境导入类似spark-assembly-0.8.1-incubating- hadoop2.2.0.jar
在这里你可以导入类似的spark-assembly-0.8.1-incubating- hadoop2.2.0.jar。在早期spark版本中,lib目录下自带该文件。但在目前我使用的spark2.0.0,没有找到该文件。
因此,必须自己生成该文件。同样也可以直接将jars目录下的所有包都引入程序当中。
打开 Project Structure,快捷方式 ctrl + alt + shift + s
导入:
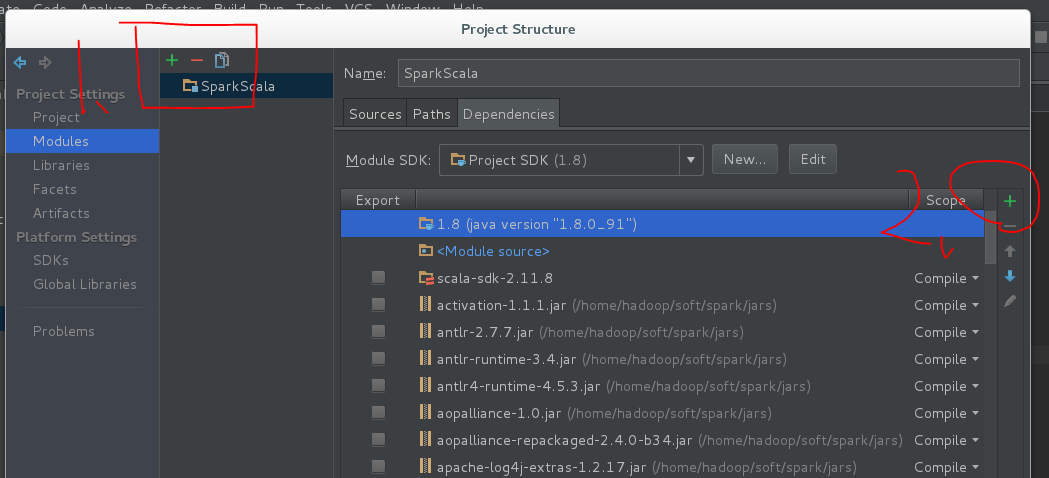
配置打包:按照下图先设置好打包的配置
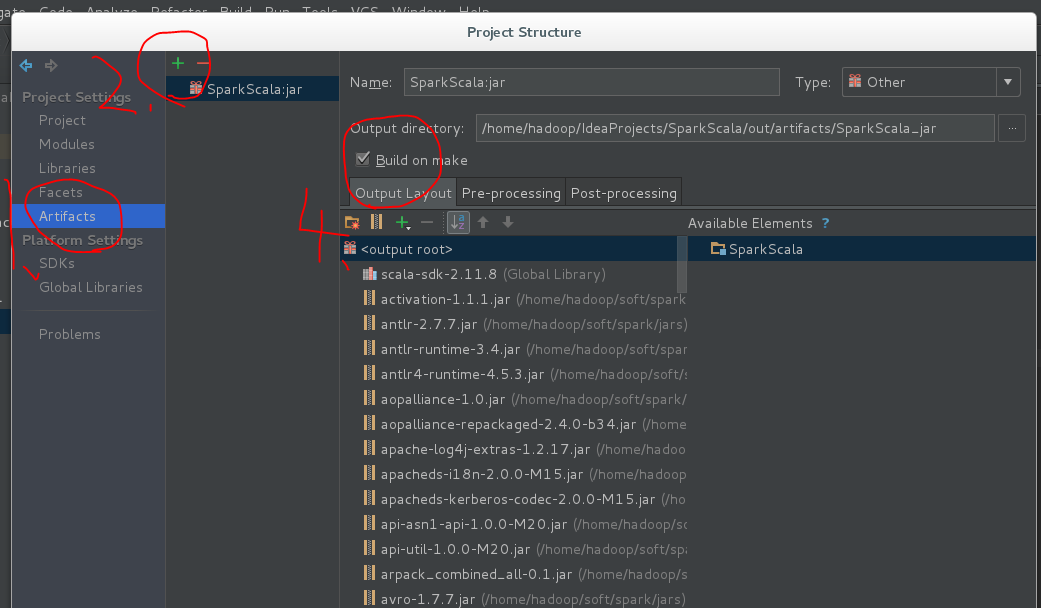
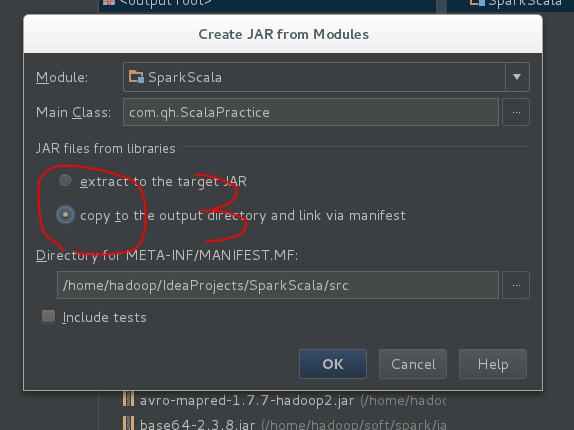
打包:build->Artifacts…->build
运行:在$SPARK_HOME/bin 目录下(或者配置了环境变量),同时如果没有在程序中配置master和appname,可以通过下述方式设置。设置方法自己查看 help
spark-submit –class com.qh.ScalaPractice SparkScala.jar
3:scala spark RDD
在网上可以找到很多关于scala编写spark程序的例子。但是经过自己的实验,发现和多的RDD操作函数是没有的。
可能是这个版本被舍弃掉了,也可能是自己使用方式不对。下例是自己根据网上的教程编写的wordCount,亲测有效
package com.qh
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by hadoop on 8/17/16.
* wordCount
*/
object wordCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("wordCount")
.setMaster("spark://master:7077")
val sc = new SparkContext(conf)
val file = sc.textFile("/DataBigZYS/file", 3)
val result = file
.flatMap(value => value.split("\\s+"))
.map(word => (word, 1))
.reduceByKey((value1, value2) => value1 + value2)
result.foreach(println)
result.saveAsTextFile("/DataBigZYS/file1")
}
}3:scala spark RDD 基础操作
package com.qh
import org.apache.hadoop.io.IntWritable
import org.apache.hadoop.io.Text
import org.apache.hadoop.mapred.{JobConf, TextOutputFormat}
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by zys on 8/17/16.
*/
object ScalaPractice {
private val path = "hdfs://master:9000/Spark/Practice"
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("ScalaTest")
.setMaster("spark://master:7077")
val sc = new SparkContext(conf)
val raw = sc.parallelize(1 to 9, 3)
// top 函数用于从RDD中,按照默认(降序)或者指定的排序规则,返回前num个元素
raw.top(3)
// take 用于获取RDD中从0到num-1下标的元素,不排序。
raw.take(3)
// takeOrdered 和top类似,只不过以和top相反的顺序返回元素。
raw.takeOrdered(3)
// first 返回RDD中的第一个元素,不排序
raw.first()
// count 返回RDD中的元素数量
raw.count()
// collect 将一个RDD转换成数组
raw.collect()
// reduce 对RDD中的元素进行二元计算,返回计算结果
raw.reduce((x1, x2) => x1 + x2)
// lookup 用于(K,V)类型的RDD,指定K值,返回RDD中该K对应的所有V值
raw.map(x => (x, x * x)).lookup(2) // 4
// countByKey 用于统计RDD[K,V]中每个K的数量
raw.map(x => (x, x * x)).countByKey() // 4
// foreach用于遍历RDD,将函数f应用于每一个元素
raw.foreach(x => x * 2)
// foreachPartition和foreach类似,只不过是对每一个分区使用
var Num = 0
raw.foreachPartition(iter => {
iter.foreach(x => Num += x)
})
// sortBy
// 根据给定的排序k函数将RDD中的元素进行排序
raw.sortBy(x => x) // 升须
raw.sortBy(x => x, ascending = false) // 降序
raw.map(x => (x, x * 2)).sortBy(x => x._2) // 根据value排序
// Map
// 对RDD中的每个元素都执行一个指定的函数来产生一个新的RDD
// 任何原RDD中的元素在新RDD中都有且只有一个元素与之对应
val map = raw.map(x => x * 2)
map.saveAsTextFile(path + "/map")
// mapPartitions
// 输入函数应用于每个分区,也就是把每个分区中的内容作为整体来处理的
// 处理的元素是当前分区所有元素之和组成的Iterator集合,并返回一个Iterator集合
raw.mapPartitions(x => {
var i = 0
x.foreach(arg => i += arg)
List[Int]().::(i).iterator
}
).saveAsTextFile(path + "/mapPartitions")
// mapPartitionsWithIndex
// 功能类似与mapPartitions 不同的是传入的参数是一个二元元组
// 元组成分为:(分区的index,当前处理的分区元素组成的Iterator) 返回一个同类型的二元元组
raw.mapPartitionsWithIndex((index, iter) => iter.map(x => (index, x)))
.saveAsTextFile(path + "/mapPartitionsWithIndex")
// mapValues
// 输入函数应用于RDD中Kev-Value的Value,原RDD中的Key保持不变,与新的Value一起组成新的RDD中的元素
// 输出和输入都是KV对
raw.map(x => (x, x)).mapValues(value => value * value)
.saveAsTextFile(path + "/mapValues")
// flatMapValues
// flatMapValues是针对[K,V]中的V值进行flatMap操作
raw.map(x => (x, x)).flatMapValues(x => 1 to x)
.saveAsTextFile(path + "/flatMapValues")
// flatMap
// 与map类似,区别是RDD中的元素经map处理后只能生成一个元素 flatMap处理后可生成多个元素来构建新RDD
// 注意:flatMap会将字符串看成是一个字符数组
raw.flatMap(x => 1 to x).saveAsTextFile(path + "/flatMap")
// reduceByKey
raw.map(x => (x, x * x)).reduceByKey((x1, x2) => x1 + x2)
.saveAsTextFile(path + "/reduceByKey")
// distinct
// 对RDD中的元素进行去重操作
raw.map(x => x % 5).distinct().saveAsTextFile(path + "/distinct")
// union
// 将两个RDD进行合并,不去重
val other = sc.parallelize(6 to 14, 3)
raw.union(other).saveAsTextFile(path + "/other")
// intersection
// 函数返回两个RDD的交集,并且去重。
// 可选参数numPartitions指定返回的RDD的分区数。
// 可选参数Partitioner用于指定分区函数
raw.intersection(other, 1).saveAsTextFile(path + "/intersection")
// subtract 类似intersection
// 返回在RDD中出现,并且不在otherRDD中出现的元素,不去重
raw.subtract(other, 1).saveAsTextFile(path + "/subtract")
// zip
// 将两个RDD组合成Key/Value形式的RDD,这里默认两个RDD的partition数量以及元素数量都相同,否则会抛出异常
raw.zip(other).saveAsTextFile(path + "/zip")
// zipPartitions
// 将多个RDD按照partition组合成为新的RDD,该函数需要组合的RDD具有相同的分区数,但对于每个分区内的元素数量没有要求
raw.zipPartitions(sc.parallelize(Seq('a', 'b', 'c'), 3)) {
(rdd1Iter, rdd2Iter) => {
// List在定义完之后不能添加元素,是一个不可变集合
// val result = List[String]()
val result = ListBuffer[String]()
while (rdd1Iter.hasNext && rdd2Iter.hasNext) {
result.append(rdd1Iter.next() + "_" + rdd2Iter.next())
}
result.iterator
}
}.saveAsTextFile(path + "/zipPartitions")
// zipWithIndex
// 将RDD中的元素和这个元素在RDD中的ID(索引号)组合成键/值对
raw.zipWithIndex().saveAsTextFile(path + "/zipWithIndex")
// zipWithUniqueId
// 将RDD中元素和一个唯一ID组合成键/值对,该唯一ID生成算法如下:
// 每个分区中第一个元素的唯一ID值为:该分区索引号,
// 每个分区中第N个元素的唯一ID值为:(前一个元素的唯一ID值) + (该RDD总的分区数)
raw.zipWithUniqueId().saveAsTextFile(path + "/zipWithUniqueId")
// aggregate(zeroValue)(seqOp, combOp) 聚合
// 首先通过seqOp对分区内的元素进行聚合操作并返回结果
// 随后通过combOp对所有分区的结果和初始值zeroValue进行聚合操作返回最终结果
raw.aggregate(1)({ (x, y) => x + y }, { (a, b) => a + b })
// fold是aggregate的简化,将aggregate中的seqOp和combOp使用同一个函数op
raw.fold(1)({ (x, y) => x + y })
// saveAsTextFile 将RDD以文本文件的格式存储到文件系统中,可以通过参数指定压缩类型
// saveAsSequenceFile 将RDD以SequenceFile的文件格式保存到HDFS上 用法同saveAsTextFile
// saveAsObjectFile 将RDD中的元素序列化成对象,存储到文件中 用法同saveAsTextFile
// saveAsHadoopFile 是将RDD存储在HDFS上的文件中,支持老版本Hadoop API
// 可以指定outputKeyClass outputValueClass以及压缩格式
// saveAsNewAPIHadoopFile用于将RDD数据保存到HDFS上,使用新版本Hadoop API
raw.zipWithUniqueId().saveAsHadoopFile(path + "/saveAsHadoopFile",
classOf[Text], classOf[IntWritable], classOf[TextOutputFormat[Text, IntWritable]])
// saveAsHadoopDataset 将RDD保存到除了HDFS的其他存储中,比如HBase
// 在JobConf中,通常需要关注或者设置五个参数:
// 文件的保存路径、key值的class类型、value值的class类型、RDD的输出格式(OutputFormat)、以及压缩相关的参数
// saveAsNewAPIHadoopDataset 同saveAsHadoopDataset,只不过采用新版本Hadoop API
val rdd1 = sc.makeRDD(Array(("A", 2), ("A", 1), ("B", 6), ("B", 3), ("B", 7)))
val jobConf = new JobConf()
jobConf.setOutputFormat(classOf[TextOutputFormat[Text, IntWritable]])
jobConf.setOutputKeyClass(classOf[Text])
jobConf.setOutputValueClass(classOf[IntWritable])
jobConf.set("mapred.output.dir", path + "/saveAsHadoopDataset")
rdd1.saveAsHadoopDataset(jobConf)
jobConf.set("mapred.output.dir", path + "/saveAsNewAPIHadoopDataset")
raw.zipWithUniqueId().saveAsNewAPIHadoopDataset(jobConf)
// filter 对元素进行过滤,对每个元素调用f函数,返回值为true的元素就保留在RDD中
raw.filter(_ > 5)
// groupBy 分组函数,对每个元素调用f函数,返回值作为分组的依据。
raw.groupBy(_ > 5)
// groupByKey
// 将RDD[K,V]中每个K对应的V值,合并到一个集合Iterable[V]中
// 可添加参数numPartitions用于指定分区数
// 可添加爱参数partitioner用于指定分区函数
// 推荐在生产环境中尽量不要使用groupByKey,最好使用reduceByKey
raw.map((_, 1)).groupByKey(1)
}
}













 1285
1285











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









