







1. 对http的原理还不是很清楚,只是个模糊的概念,准备把这块搞清楚。
参考博客:http://www.imooc.com/article/1851
传输层协议:
1.TCP: HTTP(大多数) ,FTP,SMTP
2.UDP:HTTP,XMPP.POP;
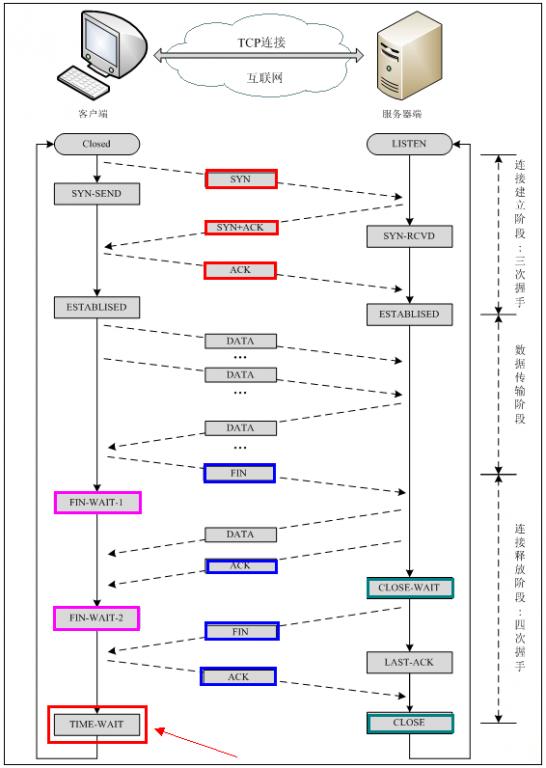
TCP:
1.面向连接;
2.三次握手 : 客户端 --SYN-->服务器--SYN(ACK)-->客户端 --ACK-->服务器
3.四次挥手: 客户端 --FIN-->服务器(close wait)--ACK-->客户端
服务器--FIN-->客户端 (TIME WAIT)--ACK-->服务器(CLOSE) 客户端 --->CLOSE
4.数据的可靠性(校验位)每一个包都带有上个包的校验位;
选择上:容错高,数据包小,承受丢包风险(音视频) 选择UDP,其他应该选择TCP
HTTP:
1.特点:无连接(每次只做一个请求处理,处理完毕即刻断开连接,节省传输时间)
无状态(对于事物处理没有记忆功能,后续需要前面的信息必须重新传,传输量增大)
2.消息格式(三个部分):
首行 :指出http的属性(固定格式),在请求和响应消息时略有区别 ------>>>>唯一必有
头部(header)
正文(body):传输的实际内容,格式任意。通常由content-type来指定
*Http消息主要是基于ASCII编码的消息体,指首行和正文的编码方式(文本流),而正文则是一般随意(字节流),较多的用UTF-8格式编码
http传输顺序首行,头部,正文,一个特殊的控制结构CRLF(/r/n)来控制每个部分的结束即:
首行 CRLF 头部 CRLF 正文CRLF 其中头部格式:head1CRLFhelder2CRLF 一个单独的CRLF(紧接着上一个CRLF)表示整个头部的结束
实例:
GET请求:没有请求正文,但可以包含querey-string
以明文的方式通过URL提交数据,数据在URL中可以看得见,提交数据最多不超过2kb。安全性低但是效率比post高。适合提交数据量不大,安全性不高的数据。
一个单独的CRLF(紧接着上一个CRLF)表示整个头部的结束
POST请求:带json格式正文的post请求
适合提交数据量大,安全性高的用户信息。
HTTP请求 (请求行,请求头部,请求正文)
1.请求行.基本格式: 方法 路径 版本 GET /simple.html HTTP/1.1
方法:GET,POST, 服务器对于方法的处理是没有强制的规范的。
路径:basic-path[?query-string] []为可选参数,采用key-value形式&连接多个参数,k= 和 k是被允许的
版本:生命HTTP消息的解析规则,不同版本在某些地方表现不同 但大多数都是1.1版本
/**
当键值对出现&和=这样的字符,我们只能用他的ASCII编码进行赋值
看
k1:& k2: =
k1=%26&k2=%3D
其中&的16进制是26,=的16进制表示是3D, 格式是%XX三个字符表示
**/
浏览器一般会对GET方法的请求资源做一些缓存,下次请求坑能从缓存去取,
但是服务器将获取资源的方法定义为post那么浏览器就不能对资源进行缓存了,即使是
同样的内容,都需要服务器重新发送一遍
Get方法请求是不能定义消息体的,HEADF方法请求是不包含消息体的,这些都是http协议对http的方法约束;
每个方法有自己的使用范围,和作用域。
Http请求头:
以冒号的键值对分开,如:
Accept: text/html
Accept-Language: zh-cn
Accept-Encoding: gzip, deflate
User-Agent: Mozilla/4.0
Host: localhost:8080
Connection: Keep-Alive
Content-Type: application/json
Http响应:响应首行,响应头部,响应正文
响应首行:版本号 状态码 状态文本
HTTP/1.1 200 OK
状态码一般分为5类:
1XX :信息
2XX:请求处理成功
3XX:重定向
4XX:客户端错误
5XX:服务器错误















 1897
1897

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









