







Kafka是最初由Linkedin公司开发,是一个分布式、分区的、多副本的、多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/nginx日志、访问日志,消息服务等等,Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。
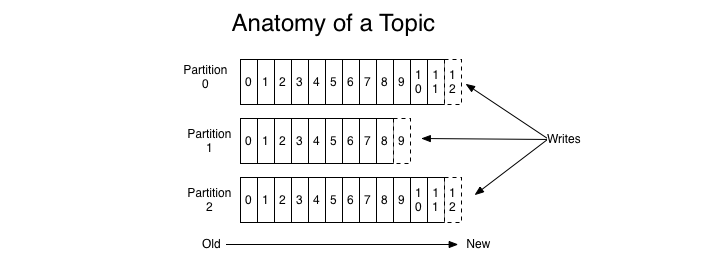
今天我会从几个重要的环节去介绍Kafka的一些基本特性。Kafka是分布式的,所以内容消息通常是分布在各个机器上,一般消息会发送到topic中,一个topic通常由多个partition,kafka把每个topic的每个partition均匀的分布在集群中的不同服务器上.所以从整体来看,Kafka的逻辑关系就是:生产者向topic中的某个partition发送消息,消费者从partition获取消息。
Kafka基本概念
- Broker:消息中间件处理结点,一个Kafka节点就是一个broker,多个broker可以组成一个Kafka集群。
- Topic:一类消息,例如page view日志、click日志等都可以以topic的形式存在,Kafka集群能够同时负责多个topic的分发。
- Partition:topic物理上的分组,一个topic可以分为多个partition,每个partition是一个有序的队列。
- Segment:partition物理上由多个segment组成。
- offset:每个partition都由一系列有序的、不可变的消息组成,这些消息被连续的追加到partition中。partition中的每个消息都有一个连续的序列号叫做offset,用于partition唯一标识一条消息。
Kafka消息发送的机制
每当用户往某个Topic发送数据时,数据会被hash到不同的partition,这些partition位于不同的集群节点上,所以每个消息都会被记录一个offset消息号,随着消息的增加逐渐增加,这个offset也会递增,同时,每个消息会有一个编号,就是offset号。消费者通过这个offset号去查询读取这个消息。
发送消息流程
首先获取topic的所有Patition
如果客户端不指定Patition,也没有指定Key的话,使用自增长的数字取余数的方式实现指定的Partition。这样Kafka将平均的向Partition中生产数据。
如果想要控制发送的partition,则有两种方式,一种是指定partition,另一种就是根据Key自己写算法。继承Partitioner接口,实现其partition方法。
Kafka消息消费机制
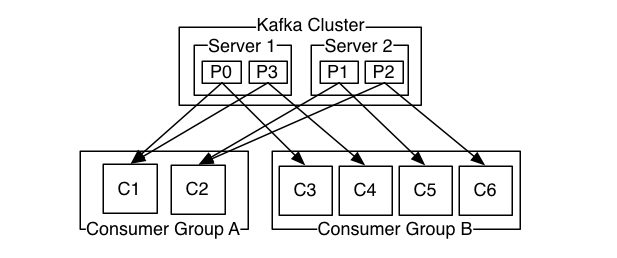
kafka 消费者有消费者族群的概念,当生产者将数据发布到topic时,消费者通过pull的方式,定期从服务器拉取数据,当然在pull数据的时候,,服务器会告诉consumer可消费的消息offset。
创建一个Topic (名为topic1),再创建一个属于group1的Consumer实例,并创建三个属于group2的Consumer实例,然后通过 Producer向topic1发送Key分别为1,2,3的消息。结果发现属于group1的Consumer收到了所有的这三条消息,同时 group2中的3个Consumer分别收到了Key为1,2,3的消息,如下图所示。
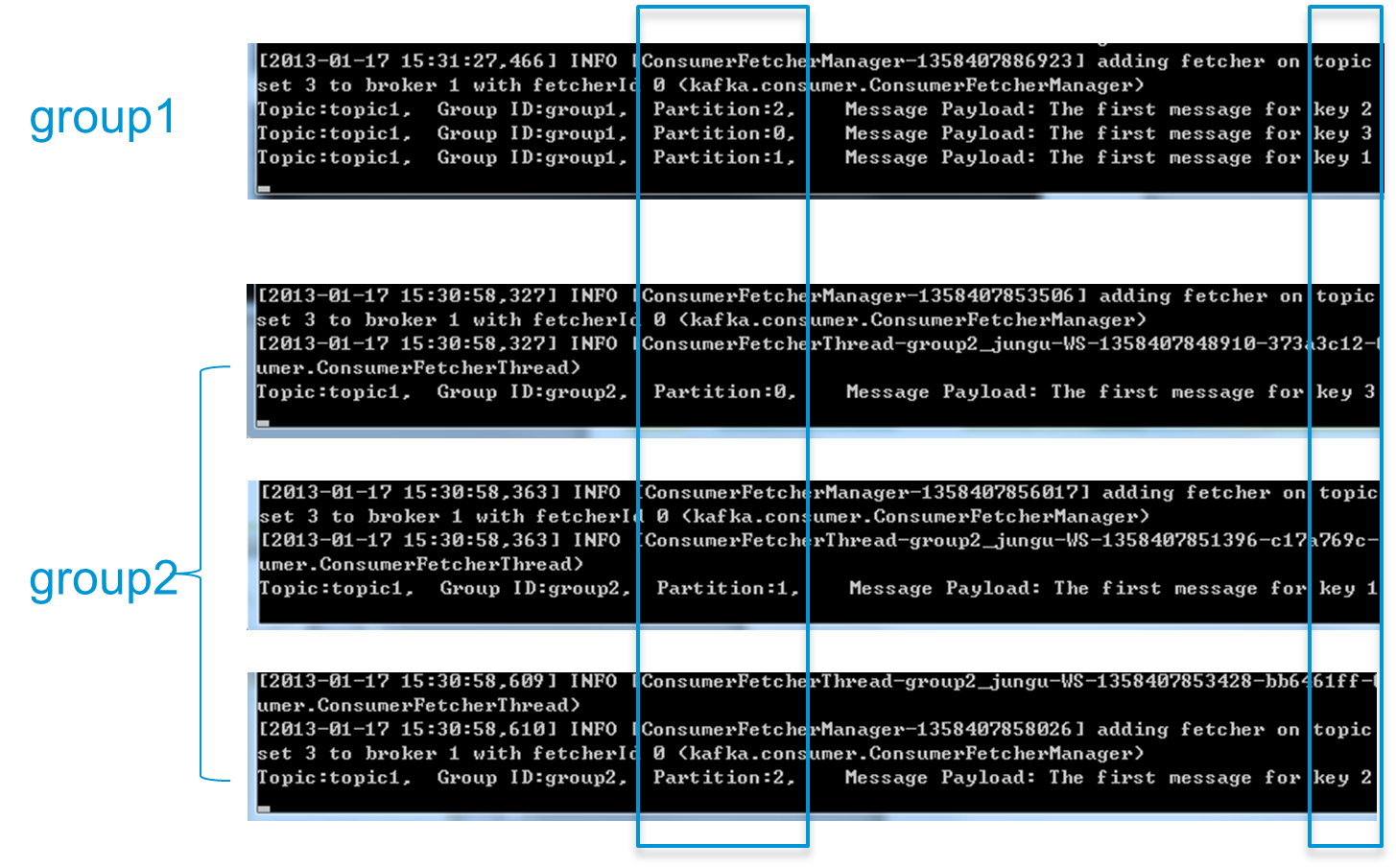
结论:不同 Consumer Group下的消费者可以消费partition中相同的消息,相同的Consumer Group下的消费者只能消费partition中不同的数据。
服务器会记录每个consumer的在每个topic的每个partition下的消费的offset,然后每次去消费去拉取数据时,都会从上次记录的位置开始拉取数据。比如0.8版本的用zookeeper来记录
/{comsumer}/{group_name}/{id}/{consumer_id} //记录id
/{comsumer}/{group_name}/{offset}/}{topic_name}/{partitions_id} //记录偏移量
/{comsumer}/{group_name}/{owner}/}{topic_name}/{partitions_id} //记录分区属于哪个消费者
当consumer和partition增加或者删除时,需要重新执行一遍Consumer Rebalance算法
Consumer Rebalance的算法如下
- 将目标Topic下的所有Partirtion排序,存于PT
- 对某Consumer Group下所有Consumer排序,存于CG,第i个Consumer记为Ci
- N=size(PT)/size(CG),向上取整
- 解除Ci对原来分配的Partition的消费权(i从0开始)
- 将第i∗N到(i+1)∗N−1个Partition分配给Ci
Kafka消息存储机制
kafka的消息是存储在磁盘的,所以数据不易丢失, 如上了解,partition是存放消息的基本单位,那么它是如何存储在文件当中的呢,如上:topic-partition-id,每个partition都会保存成一个文件,这个文件又包含两部分。 .index索引文件、.log消息内容文件。
index文件结构很简单,每一行都是一个key,value对
key 是消息的序号offset,value 是消息的物理位置偏移量. index索引文件 (offset消息编号-消息在对应文件中的偏移量)

比如:要查找.index文件中offseet 为7的 Message(全局消息为id 368776):
- 首先是用二分查找确定它是在哪个LogSegment中,自然是在第一个Segment中。
- 打开这个Segment的index文件,也是用二分查找找到offset小于或者等于指定offset的索引条目中最大的那个offset。自然offset为6的那个索引是我们要找的,通过索引文件我们知道offset为6的Message在数据文件中的位置为1407。
- 打开数据文件.log,从位置为1407的那个地方开始顺序扫描直到找到 .index文件中offseet 为7(全局消息为id 368776)的那条Message(offset 1508)。
这套机制是建立在offset是有序的。索引文件被映射到内存中,所以查找的速度还是很快的。
这是一种稀疏索引文件机制,并没有把每个消息编号和文件偏移量记录下来,而是稀疏记录一部分,这样可以方式索引文件占据过多空间。每次查找消息时,需要将整块消息读入内存,然后获取对应的消息。
比如消息offset编号在36,37,38的消息,都会通过38找到对应的offset
Kafka数据存储格式
从上述了解到.log由许多message组成,下面详细说明message物理结构如下:
参数说明:
| 关键字 | 解释说明 |
|---|---|
| 8 byte offset | 在parition(分区)内的每条消息都有一个有序的id号,这个id号被称为偏移(offset),它可以唯一确定每条消息在parition(分区)内的位置。即offset表示partiion的第多少message |
| 4 byte message size | message大小 |
| 4 byte CRC32 | 用crc32校验message |
| 1 byte “magic” | 表示本次发布Kafka服务程序协议版本号 |
| 1 byte “attributes” | 表示为独立版本、或标识压缩类型、或编码类型。 |
| 4 byte key length | 表示key的长度,当key为-1时,K byte key字段不填 |
| K byte key | 可选 |
| value bytes payload | 表示实际消息数据。 |
日志更新和清理
Kafka中如果消息有key,相同key的消息在不同时刻有不同的值,则只允许存在最新的一条消息,这就好比传统数据库的update操作,查询结果一定是最近update的那一条,而不应该查询出多条或者查询出旧的记录,当然对于HBase/Cassandra这种支持多版本的数据库而言,update操作可能导致添加新的列,查询时是合并的结果而不一定就是最新的记录。图3-27中示例了多条消息,一旦key已经存在,相同key的旧的消息会被删除,新的被保留。如下图,就是对日志更新然后压缩。
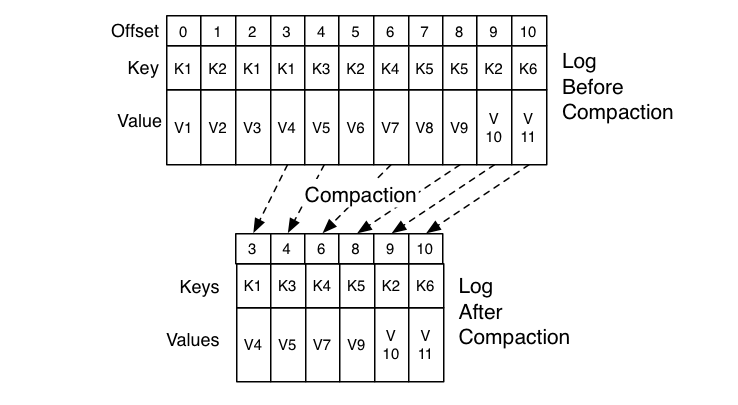
清理后Log Head部分每条消息的offset都是逐渐递增的,而Tail部分消息的offset是断断续续的。 LogToClean 表示需要被清理的日志
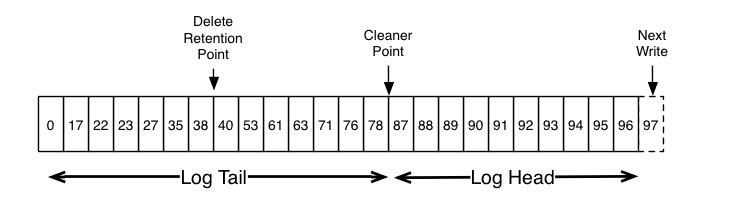
生产者客户端如果发送的消息key的value是空的,表示要删除这条消息, 发生在删除标记之前的记录都需要删除掉,而发生在删除标记(Cleaner Point)之后的记录则不会被删除。
消息检索过程示例
例如读取offset=368的消息
(1)找到第368条消息在哪个segment
从partition目录中取得所有segment文件的名称,就相当于得到了各个序号区间
例如有3个segment
00000000000000000000.index
00000000000000000000.log
00000000000000000300.index
00000000000000000300.log
00000000000000000600.index
00000000000000000600.log
根据二分查找,可以快速定位,第368条消息是在00000000000000000300.log文件中
(2)从00000000000000000300.index文件中找到其物理偏移量
读取 00000000000000000300.index 。以 68 (368-300的值)为key,得到value,如299,就是消息的物理位置偏移量
(3)到log文件中读取消息内容
读取 00000000000000000300.log 从偏移量299开始读取消息内容。完成了消息的检索过程
Kafka日志磁盘存储优于内存
其实Kafka最核心的思想是使用磁盘,而不是使用内存,可能所有人都会认为,内存的速度一定比磁盘快,我也不例外。在看了Kafka的设计思想,查阅了相应资料再加上自己的测试后,发现磁盘的顺序读写速度和内存持平。
而且Linux对于磁盘的读写优化也比较多,包括read-ahead和write-behind,磁盘缓存等。如果在内存做这些操作的时候,一个是JAVA对象的内存开销很大,另一个是随着堆内存数据的增多,JAVA的GC时间会变得很长,使用磁盘操作有以下几个好处:
- 磁盘缓存由Linux系统维护,减少了程序员的不少工作。
- 磁盘顺序读写速度超过内存随机读写。
- JVM的GC效率低,内存占用大。使用磁盘可以避免这一问题。
- 系统冷启动后,磁盘缓存依然可用。
另外可参考知乎的一篇文章:如何利用磁盘顺序读写快于内存随机读写这一现象?https://www.zhihu.com/question/48794778
Kafka 性能设计
一个topic就是个table,table会动态增长,而且只是追加,在集群中有很多table,访问时访问table中的数据,有个巨大的优势是,只会在最新的基础上追加数据,所以不会有冲突,不需要加锁。完全可以使用磁盘的顺序读写,比随机读写快10000倍。
Kafka中用到了sendfile机制,随机读写是每秒k级别的,如果是线性读写可能能到每秒上G,kafka在实现时,速度非常快,是因为会把数据立即写入文件系统的持久化日志中,不是先写在缓存中,再flush到磁盘中。也就是说,数据过来的时候,是传输在os kernel的页面缓存中,由os刷新到磁盘中。在os采用sendfile的机制,os可以从页面缓存一步发送数据到网络中,同时,kafka支持gzip和Snappy对数据进行压缩,这个对传输数据至关重要。
数据存储采用topic-partition-record的三层体系,是个树状数据结构。对于树的存储,比较常用的是B tree,运行时间是O(logN),但是在因为需要锁定机制,在磁盘层面,在高速交换、数据规模比较大的时候,性能损耗还是比较厉害的。Kafka的方式是把所有消息看成普通的日志,理念就是把日志内容简单的追加,采用offset读取数据,优势是性能完全是线性的,和数据大小没有关系,同时,读取操作和写入操作不会互相阻塞,性能能永远达到最大化。














 2039
2039











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









