







这里我们要爬起豆瓣读书Top250,并保存每本书的书名,信息,简要介绍和作者信息.
这里,仍然分为三步:
1.url分析
2.数据分析
3.爬取数据
1.url分析
豆瓣读书Top250的url分析和豆瓣电影Top250类似:
豆瓣读书Top250的url基本都是这样的:
所以,同样我也是利用urlparse的urljoin函数来拼接自己所需要的url,传入urlopen()
2.数据分析
利用urlopen,我们得到response对象,接着传入BeautifulSoup得到BeautifulSoup对象.接下来便分析数据了.
查看源代码,我们发现每本书的名字都包含在具有title属性的a标签中,同时令我们惊喜的时,a标签中还有href属性,这样我们就可以直接获取这本书的名字和它所对应豆瓣网页,为我们接下来获取这本书的详细介绍打下基础.
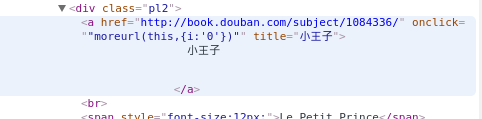
于是,我们可以利用find_all()函数来查找所有具有title属性的a标签.同样,在这里find_all()函数也是在html文档树中从上到下查找,所以我们也不需要担心Top顺序,找到之后,我们还可以判断a标签是否含有href属性,如果有的话,就可以提取href属性对应的url来获取这本书的详细介绍了
代码介绍
在我的代码里,我主要声明了两
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 539
539











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









