






关于Jsoup的基础知识点这里就不说了,个人认为很多大牛写的很详细也比较全面,这里就简单举一个使用例子玩玩,社长也比较喜欢拿例子来理解一些知识点。
给几个有用的链接:
1、jsoup下载地址
2、待会儿会用到,主要用来测试一些选择器之类的是否选择到数据,还可以查询当前浏览器user-Agent
废话不多说,以泡在网上的日子Android分类内容为例子。
页面地址:
点击F12或者右键查看网页元素去分析需要抓取的数据所在位置
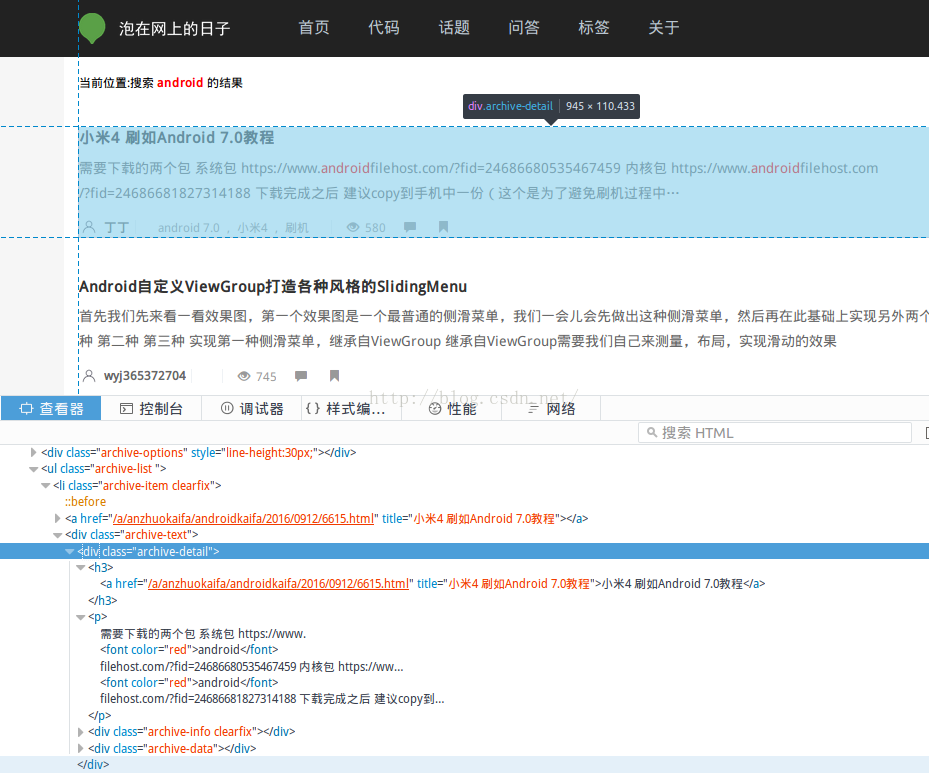
可以注意到几个比较重要的标签<div class="archive-detail">和子元素<h3>包含了抓取数据的链接和标题;<p>包含了抓取内容的简介。现在可以去刚才推荐的第二个网址内测试一下。当然也可以不测。
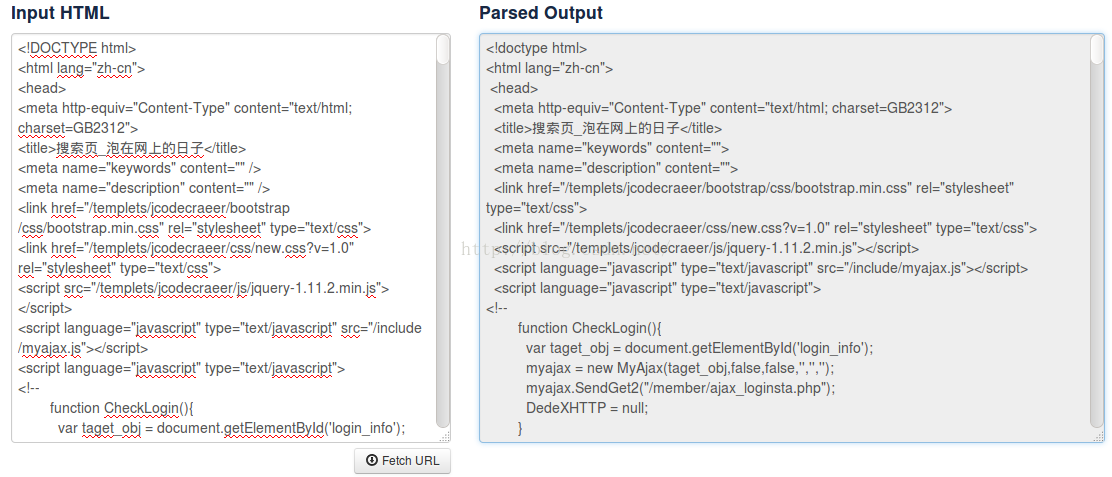
点击Fetch URL把抓取数据的网页地址复制进来。
在搜索框中输入dic.archive-detail
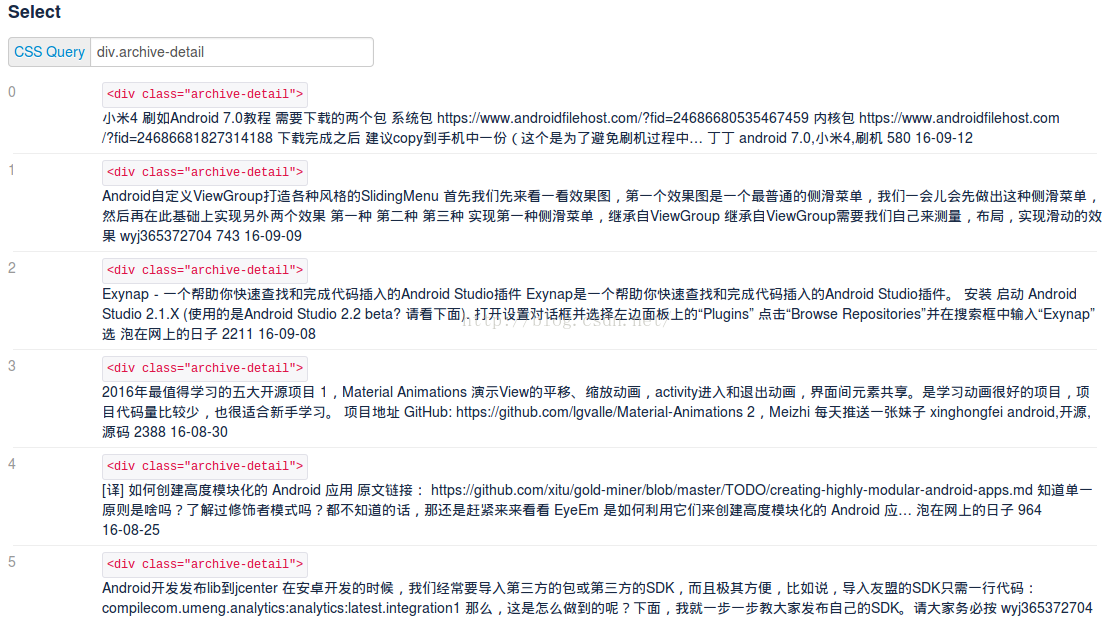
成功了,说明<div class="archive-detail">可以获取选择到我们需要的内容。
抓取网页数据最重要的就是去分析数据所在位置。其次就是用Jsoup的api去获取得到数据。那么接下来着手代码。
//获取抓取内容
public void getSelectData(String url) throws IOException {
Document doc = Jsoup.connect(url).timeout(60 * 1000)
.userAgent("Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:48.0) Gecko/20100101 Firefox/48.0")
.get();
//实例div.archive-detail元素集合
Elements links = doc.select("div.archive-detail");
//遍历集合下<a>标签包含的href和title值
for(int i=0;i<links.size();i++){
Elements a = links.get(i).select("a");
Log.i("shezhang","标题 = "+a.attr("title"));
Log.i("shezhang","链接 = "+a.attr("abs:href"));
//获取<p>标签包含的内容
Elements p = links.get(i).select("p");
Log.i("shezhang","简介 = "+p.text());
}
}
private void findViewById(){
btnTest = (Button) findViewById(R.id.btn_test);
btnTest.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View v) {
new Thread(){
@Override
public void run() {
try {
for(int i=1;i<=30;i++){
try {
Log.i("jiawei","第"+i+"页");
getData(url+i);
sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
}.start();
}
});
}代码很简单,过个过场。因为泡在网上的日子请求有时间限制,所有我的线程中睡3秒再继续请求下一页的内容 一共有30页。从刚才给出的泡在上网的日子的第一页网址可以看出只要改改最后那个页码就好哈哈。比较重要的就是getSelectData()中的获取数据的代码。
首先实例Document对象,然后获得主要元素,
Elements links = doc.select("div.archive-detail");这个div就是包含了各个文章链接啊标题啊简介啊的部分,然后通过遍历这个div元素去获得我们想要的链接啊标题啊巴拉巴拉。先得到子元素
Elements h3 = links.get(i).select("a");然后通过a元素去获得a里面的内容,包括链接啊标题啊。
Log.i("shezhang","标题 = "+h3.attr("title"));
Log.i("shezhang","链接 = "+h3.attr("abs:href"));简介被包含在<p>标签中
<span style="font-size:18px;">Elements p = links.get(i).select("p");
Log.i("shezhang","简介 = "+p.text());</span>OK!运行得到:搞定!步骤还是挺简单的,社长写的内容呢比较粗略。代码粗略。图片粗略。。。。如果同学们项目需要用到的话,不妨把请求数据部分另外开个专门的类异步封装好点,把请求的数据封装成bean对象勉强就可以用啦。这里就做个简单例子,学习了基本用法的时候看一些案例可以加深理解。














 2540
2540











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









