







awk
是一种优良的文本处理工具,Linux及Unix环境中现有的功能最强大的数据处理引擎之一。这种编程及数据操作语言的最大功能取决于一个人所拥有的知识。awk命名:Alfred Aho Peter Weinberger和brian kernighan三个人的姓的缩写。
最简单地说, AWK 是一种用于处理文本的编程语言工具。
任何awk语句都是由模式和动作组成,一个awk脚本可以有多个语句。模式决定动作语句的触发条件和触发时间。
语法结构
awk 'BEGIN{ print "start" } ‘pattern{ commands }’ END{ print "end" }' file
#BEGIN语句设置计数和打印头部信息,在任何动作之前进行
#END语句输出统计结果,在完成动作之后执行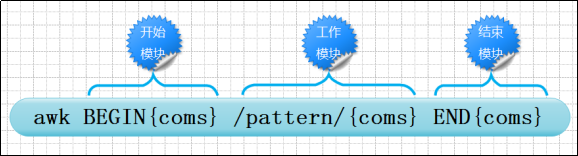
awk内置变量(预定义变量)
$n 当前记录的第n个字段,比如n为1表示第一个字段,n为2表示第二个字段
$0 这个变量包含执行过程中当前行的文本内容
-FILENAME 当前输入文件的名
FS 字段分隔符(默认是任何空格)
NF 表示字段数,在执行过程中对应于当前的字段数
NR 表示记录数,在执行过程中对应于当前的行号
OFS 输出字段分隔符(默认值是一个空格)
ORS 输出记录分隔符(默认值是一个换行符)
RS 记录分隔符(默认是一个换行符) 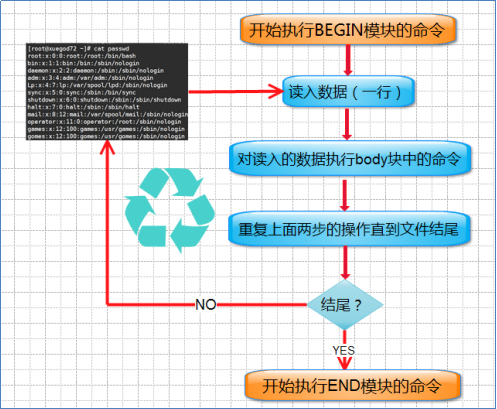
获取linux中eth0的IP地址
eth0 Link encap:Ethernet HWaddr 00:0C:29:18:4C:35
inet addr:192.168.75.130 Bcast:192.168.75.255 Mask:255.255.255.0
inet6 addr: fe80::20c:29ff:fe18:4c35/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:1322 errors:0 dropped:0 overruns:0 frame:0
TX packets:1093 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:147531 (144.0 KiB) TX bytes:134582 (131.4 KiB)
ifconfig eth0 |grep 'inet addr' |awk -F ":" '{print $2}'
192.168.75.130 Bcast
#可以看到后面多出来了一个Bcarst,可以打印出第一列
ifconfig eth0 |grep 'inet addr' |awk -F ":" '{print $2}'|awk '{print $1}'
192.168.75.130
ifconfig eth0|grep broadcast|awk '{print $2}'通过awk同时使用多个分隔符,然后通过正则匹配多个分隔符的方法来实现
ifconfig eth0 |awk -F '[ :]+' 'NR==2 {print $4}'
# [ :]+表示以空格和分号为分隔符,但是因为有可能有多个空格,所以用一个+表示重复前的,NR==2表示行号正则使用
打印出passwd中用户UID大于1000的用户名和登录shell
cat /etc/passwd|awk -F: '$3>=1000 {print $1,$7}'
nfsnobody /sbin/nologin
cat /etc/passwd|awk -F: '$3>=1000 {print $1"\t"$7}'
nfsnobody /sbin/nologin
#\t表示以tab键隔开awk在shell脚本中的应用
cat usecache.sh
#!/bin/bash
echo "此脚本可以用来查看当前系统的内存百分比"
use=$(free -m|grep Mem:|awk '{print $3}')
total=$(free -m|grep Mem:|awk '{print $2}')
useper=$( expr $use \* 100 / $total )
echo "系统当前内存使用百分比为:${useper}%"IF语句的使用
必须用在{}中,且比较内容用()扩起来
匹配文件中空行的行号
cat -n 8.txt
1 aaaaaaaa bbbbb ccccc dddddd eeeee ffffff
2 bbbbbbbb aaaaa ccccc dddddd eeeee
3 cccccccc bbbbb aaaaa dddddd
4
5 dddddddd bbbbb aaaaa
6
7 eeeeeeee fffff
8 ffffffff awk '{if($0 ~/^$/) print NR}' 8.txt sed
strem editor 流编辑器
sed编辑器是一行一行的处理文件内容的。正在处理的内容存放在模式空间(缓冲区)内,处理完成后按照选项的规定进行输出或文件的修改。
sed 是一种在线编辑器,它一次处理一行内容。处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”(pattern space),接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。文件内容并没有改变,除非你使用重定向存储输出。Sed主要用来自动编辑一个或多个文件;简化对文件的反复操作;
语法结构
sed [options] ‘[command]’ filename
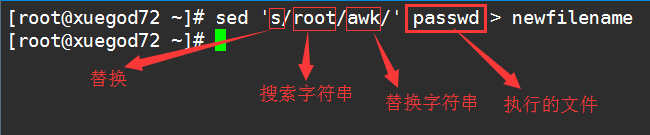
s/../../是分隔符,分割符 “/” 可以用别的符号代替 , 比如 “,” “|” “_“等 .
sed 默认只替换搜索字符串的第一次出现 , 利用 /g 可以替换搜索字符串所有
参数列表可以参考下面
options:
-n 抑制自动(默认的) 输出 *** 读取下一个输入行
-e 执行多个sed指令
-f 运行脚本
-i 编辑文件内容 ***
-i.bak 编辑的同时创造.bak的备份
-r 使用扩展的正则表达式
command:
a 在匹配后追加 *
i 在匹配前插入
p 打印
d 删除
r/R 读取文件/一行
w 另存
s 查找
c 替换
y 替换
h/H 复制拷贝/追加模式空间(缓冲区)到存放空间
g/G 粘贴 从存放空间取回/追加到模式空间
x 两个空间内容的交换
n/N 拷贝/追加下一行内容到当前
D 删除\n之前的内容
P 打印\n之前的内容
b 无条件跳转
t 满足匹配后的跳转
T 不满足匹配时跳转
显示文件除前三行之外的全部内容
sed -n '1,3!p' passwd把文件第三行替换成“bbb”
sed '3cbbb' b.txt 删除空行
sed '/^$/d' passwd > c.txt
#将匹配的行记录到新的文件中把fstab中包含xfs的记录(行)写入新的文件中
sed '/xfs/w newfstab' /etc/fstabsed 的-i选项可以直接修改文件中的内容
sed -i 's/root/rm/' passwdgrep
Linux系统中grep命令是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹 配的行打印出来。grep全称是Global Regular Expression Print,表示全局正则表达式版本,它的使用权限是所有用户。
语法格式
grep [options]
[options]主要参数:
-c:只输出匹配行的计数。
-I:不区分大 小写(只适用于单字符)。
-h:查询多文件时不显示文件名。
-l:查询多文件时只输出包含匹配字符的文件名。
-n:显示匹配行及 行号。
-s:不显示不存在或无匹配文本的错误信息。
-v:显示不包含匹配文本的所有行。
pattern正则表达式主要参数:
\: 忽略正则表达式中特殊字符的原有含义。
^:匹配正则表达式的开始行。
$: 匹配正则表达式的结束行。
\<:从匹配正则表达 式的行开始。
\>:到匹配正则表达式的行结束。
[ ]:单个字符,如[A]即A符合要求 。
[ - ]:范围,如[A-Z],即A、B、C一直到Z都符合要求 。
. :匹配除换行符\n之外的任意字符
* :匹配0或多个正好在它之前的那个字符要用好grep这个工具,其实就是要写好正则表达式,所以这里不对grep的所有功能进行实例讲解,只列几个例子,讲解一个正则表达式的写法。
ls -l | grep \'^a\'
#通过管道过滤ls -l输出的内容,只显示以a开头的行。
grep \'test\' d*
#显示所有以d开头的文件中包含test的行。
grep \'test\' aa bb cc
#显示在aa,bb,cc文件中匹配test的行。
grep \'[a-z]{5}\' aa
#显示所有包含每个字符串至少有5个连续小写字符的字符串的行。
grep \'w(es)t.*1\' aa
#如果west被匹配,则es就被存储到内存中,并标记为1,然后搜索任意个字符(.*),这些字符后面紧跟着另外一个es(1),找到就显示该行。如果用egrep或grep -E,就不用""号进行转义,直接写成\'w(es)t.*1\'就可以了。














 891
891











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









