







为了更好地压榨GPU和CPU,很多时候都使用异步并行的方法让主机端与设备端并行执行,即控制在设备没有完成任务请求前就被返回给主机端。
异步执行的意义在于:首先,处于同一数据流内的计算与数据拷贝都是依次进行的,但一个流内的计算可以和另一个流的数据传输同时进行,因此通过异步执行就能够使GPU中的执行单元与存储器单元同时工作,更好地压榨GPU的性能;其次,当GPU在进行计算或者数据传输时就返回给主机线程,主机不必等待GPU运行完毕就可以进行进行一些计算,更好地压榨了CPU的性能。
之前,单单使用GPU的同步函数,会使设备在完成请求任务前,不会返回主机线程,主机线程将进入让步(yield)、阻滞(block)或者自旋(spin)。
下面一个SDK简单的异步并行执行的程序:
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
#include <memory.h>
#include<time.h>
#include"helper_timer.h"
__global__ void increment_kernel(int *g_data, int inc_value)
{
int idx = blockIdx.x*blockDim.x + threadIdx.x;
g_data[idx] = g_data[idx] + inc_value;
}
int correct_output(int *data, const int n, const int x)
{
for (int i = 0; i < n; i++)
if (data[i] != x)
return 0;
}
int main(int argc, char *argv[])
{
cudaDeviceProp deviceProps;
cudaGetDeviceProperties(&deviceProps, 0);
printf("CUDA device [%s]\n", deviceProps.name);
int n = 16 * 1024 * 1024;
int nbytes = n*sizeof(int);
int value = 26;
int *a = 0;
cudaMallocHost((void**)&a, nbytes);
memset(a, 0, nbytes);
int *d_a = 0;
cudaMalloc((void**)&d_a, nbytes);
cudaMemset(d_a, 255, nbytes);
dim3 threads = dim3(512, 1);
dim3 blocks = dim3(n / threads.x, 1);
cudaEvent_t startGPU, stopGPU;
cudaEventCreate(&startGPU);
cudaEventCreate(&stopGPU);
StopWatchInterface *timer = NULL;
sdkCreateTimer(&timer);
sdkResetTimer(&timer);
cudaThreadSynchronize();
float gpu_time = 0.0f;
sdkStartTimer(&timer);
cudaEventRecord(startGPU, 0);
cudaMemcpyAsync(d_a, a, nbytes, cudaMemcpyHostToDevice, 0);
increment_kernel << <blocks, threads, 0, 0 >> >(d_a, value);
cudaMemcpyAsync(a, d_a, nbytes, cudaMemcpyDeviceToHost, 0);
cudaEventRecord(stopGPU, 0);
sdkStopTimer(&timer);
unsigned long int counter = 0;
while (cudaEventQuery(stopGPU) == cudaErrorNotReady)
{
counter++;
}
cudaEventElapsedTime(&gpu_time, startGPU, stopGPU);
printf("time spent executing by the GPU:%.2f\n", gpu_time);
printf("time spent by CPU in CUDA calls:%.8f\n", sdkGetTimerValue(&timer));
printf("GPU execute %d iteration while waiting forGPU to finish\n", counter);
printf("-------------------------------------------------------------------------\n");
if (correct_output(a, n, value))
printf("TEST PASSED\n");
else
printf("Test FAILED\n");
cudaEventDestroy(startGPU);
cudaEventDestroy(stopGPU);
cudaFreeHost(a);
cudaFree(d_a);
getchar();
cudaThreadExit();
return 0;
}执行结果:
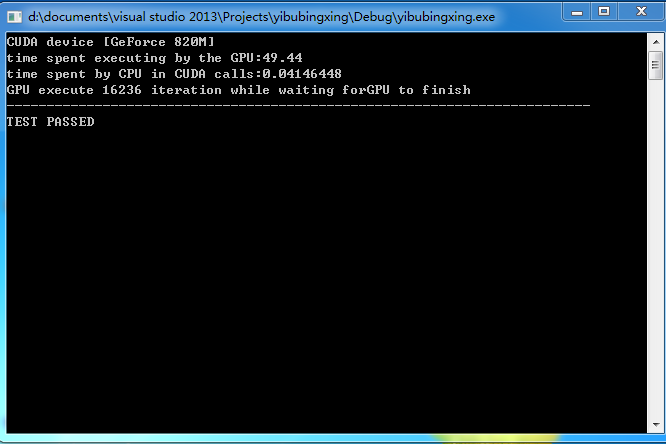
代码中
GPU上执行的是对每一个数据进行加26的处理,在CPU上执行加1迭代,
执行结果依次是GPU执行的时间,异步时CPU调用GPU所用的时间,以及在GPU上进行计算时CPU进行迭代的次数。
其中:
void *memset(void *s, int ch, size_t n);
函数解释:将s中前n个字节替换为ch并返回s;
memset:作用是在一段内存块中填充某个给定的值,它是对较大的结构体或数组进行清零操作的一种最快方法。
helper_timer.h在C:\ProgramData\NVIDIA Corporation\CUDA Samples\v7.5\common\inc下是在CUDA取消了cutil.h后包含计时的一个文件
cudaThreadSynchronize()函数是是CPU与GPU同步














 8130
8130











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









