






题目链接: http://poj.org/problem?id=1107
W's Cipher
| Time Limit: 1000MS | Memory Limit: 10000K | |
| Total Submissions: 5322 | Accepted: 2675 |
Description
Weird Wally's Wireless Widgets, Inc. manufactures an eclectic assortment of small, wireless, network capable devices, ranging from dog collars, to pencils, to fishing bobbers. All these devices have very small memories. Encryption algorithms like Rijndael, the candidate for the Advanced Encryption Standard (AES) are demonstrably secure but they don't fit in such a tiny memory. In order to provide some security for transmissions to and from the devices, WWWW uses the following algorithm, which you are to implement.
Encrypting a message requires three integer keys, k1, k2, and k3. The letters [a-i] form one group, [j-r] a second group, and everything else ([s-z] and underscore) the third group. Within each group the letters are rotated left by ki positions in the message. Each group is rotated independently of the other two. Decrypting the message means doing a right rotation by ki positions within each group.
Consider the message the_quick_brown_fox encrypted with ki values of 2, 3 and 1. The encrypted string is _icuo_bfnwhoq_kxert. The figure below shows the decrypting right rotations for one character in each of the three character groups.
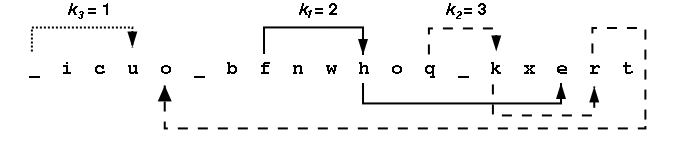
Looking at all the letters in the group [a-i] we see {i,c,b,f,h,e} appear at positions {2,3,7,8,11,17} within the encrypted message. After a right rotation of k1=2, these positions contain the letters {h,e,i,c,b,f}. The table below shows the intermediate strings that come from doing all the rotations in the first group, then all rotations in the second group, then all the rotations in the third group. Rotating letters in one group will not change any letters in any of the other groups.

All input strings contain only lowercase letters and underscores(_). Each string will be at most 80 characters long. The ki are all positive integers in the range 1-100.
Encrypting a message requires three integer keys, k1, k2, and k3. The letters [a-i] form one group, [j-r] a second group, and everything else ([s-z] and underscore) the third group. Within each group the letters are rotated left by ki positions in the message. Each group is rotated independently of the other two. Decrypting the message means doing a right rotation by ki positions within each group.
Consider the message the_quick_brown_fox encrypted with ki values of 2, 3 and 1. The encrypted string is _icuo_bfnwhoq_kxert. The figure below shows the decrypting right rotations for one character in each of the three character groups.
Looking at all the letters in the group [a-i] we see {i,c,b,f,h,e} appear at positions {2,3,7,8,11,17} within the encrypted message. After a right rotation of k1=2, these positions contain the letters {h,e,i,c,b,f}. The table below shows the intermediate strings that come from doing all the rotations in the first group, then all rotations in the second group, then all the rotations in the third group. Rotating letters in one group will not change any letters in any of the other groups.
All input strings contain only lowercase letters and underscores(_). Each string will be at most 80 characters long. The ki are all positive integers in the range 1-100.
Input
Input consists of information for one or more encrypted messages. Each problem begins with one line containing k1, k2, and k3 followed by a line containing the encrypted message. The end of the input is signalled by a line with all key values of 0.
Output
For each encrypted message, the output is a single line containing the decrypted string.
Sample Input
2 3 1 _icuo_bfnwhoq_kxert 1 1 1 bcalmkyzx 3 7 4 wcb_mxfep_dorul_eov_qtkrhe_ozany_dgtoh_u_eji 2 4 3 cjvdksaltbmu 0 0 0
Sample Output
the_quick_brown_fox abcklmxyz the_quick_brown_fox_jumped_over_the_lazy_dog ajsbktcludmv
题意:纯粹模拟,s [a-i] form one group, [j-r] a second group, and everything else ([s-z] and underscore) the third group.
每组字符串旋转ki个单位,然后取代原先字符串的位置
例如
拿第一组测试数据来说,分为3组分别为:
t1{i c b f h e}
t2{o n o q k r}
t3{_ u _ w _ x t}
k值分别为k1=2,k2=3, k3=1,t1,t2,t3分别向右旋转ki布后得到的新数据分别为:
t1'{h e i c b f}
t2'{q k r o n o}
t3'{t _ u _ w _ x }
然后取代原先位置即可
坑点:1 1 1
a
这种特殊情况要考虑,也就是并不是t1 t2 t3都可能有字符,在处理时要防止越界和数组为空的情况,否则会RE!

代码如下:
#include <cstdio>
#include <cstring>
#define N 81
char a[N],t1[N],t2[N],t3[N];
void fix(char str[],int k,int len)
{
int i,j;
char str1[81],str2[81];
k=len-k%len;
for(i=0;i<k;i++)
{
str1[i]=str[i];
}
str1[i]='\0';
j=0;
for(i=k;i<len;i++)
{
str2[j++]=str[i];
}
str2[j]='\0';
strcat(str2,str1);
strcpy(str,str2);
}
int main()
{
int i,k1,k2,k3,x,y,z,lena;
while(~scanf("%d%d%d",&k1,&k2,&k3))
{
if(k1+k2+k3==0) break;
scanf("%s",a);
memset(t1, '\0', sizeof(t1));
memset(t2, '\0', sizeof(t2));
memset(t3, '\0', sizeof(t3));
lena=strlen(a);
x=0,y=0,z=0;
for(i=0;i<lena;i++)
{
if(a[i]>='a' && a[i]<='i') t1[x++]=a[i];
else if(a[i]>='j' && a[i]<='r')t2[y++]=a[i];
else if( (a[i]>='s' && a[i]<='z' ) || a[i]=='_') t3[z++]=a[i];
}
//cout<<t1<<" "<<t2<<" "<<t3<<endl;
if(strlen(t1))
fix(t1,k1,strlen(t1));
if(strlen(t2))
fix(t2,k2,strlen(t2));
if(strlen(t3))
fix(t3,k3,strlen(t3));
//cout<<t1<<" "<<t2<<" "<<t3;
x=0,y=0,z=0;
for(i=0;i<lena;i++)
{
if(a[i]>='a' && a[i]<='i') a[i]=t1[x++];
else if(a[i]>='j' && a[i]<='r') a[i]=t2[y++];
else if( (a[i]>='s' && a[i]<='z' ) || a[i]=='_') a[i]=t3[z++];
}
printf("%s\n",a);
}
return 0;
}














 6995
6995











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









