






1、你认为Java最有意思的是什么
作为一名JAVA的
程序员,首先你是一名发明家,因为你可以new出无数个对象,其次你是一位皇帝,你可以派你new出来的对象去做任何事情。
在这些对象中,我们首先要给对象分类,就像世间万物,物以类聚,人以群分。
作为地球的霸主,人来说,我们都是同一个类,叫做人类。和Java的类一样,都具有继承,多态,封装和抽象等特征。
Java的四大特性是继承,封装,多态和抽象。这就好比人的出生一样,我们是被父母给New出来的,所以,我们继承了他们的基因,我们出生后,不需要知道是如何被New出来的,因为整个出生的过程,都已经被父母和医生,以及生理的变化给封装起来,当来到这个世界以后,我们学会了哭,学会了笑,这就是多态,同一个人,有着不同的表现形式。对于刚刚来到这个世界,我们一无所知,正因为我们的无知,才有了抽象的方法。所以那些抽象的方法并不能被实例化,除非等到我们慢慢的长大,才可以重写他们的方法。
2、如何把写的类打包成jar包,让别人调用
如果其他类需要调用,可将这个jar包导入工程就可以使用jar包里的类了
先把编译好的文件在你本地的doc环境打包
jar -cvf .....
把包导入到你的项目lib下
3、写一个类需要注意的是什么
1.首先一个java文件中至多只能有一个类被声明为public(可以没有public类),且所在java文件名需要与这个public类同名.
2.一般的规范是类名首字母大写,如果类名包括若干个单词比如HelloWorld,则所有单词的首字母需要大写
3.字段(又称变量):说明属性、特征,设计时要考虑字段名、数据类型、访问权限等方面,还可以设置初始值。出于保护数据的需要,多声明为private权限;
方法(也称函数):说明行为、功能,设计时要包含方法名、参数、返回值的数据类型、访问权限等内容,方法名后的圆括号不能省略。
类中的方法首字母应小写(构造方法除外,因为构造方法与类同名),如果方法名包含若干个单词,比如doSomething,则应除首字母小写外,方法名中的其它单词首字母应大写
4、用户登录怎么访问浏览器,动作是什么
假设你用一个全新的浏览器(第一次启动的那种),访问百度(
http://www.baidu.com/),在你敲入网址并按下回车之后,将会发生以下神奇的事情:
1、浏览器先尝试从Host文件中获取
http://www.baidu.com/对应的IP地址,如果能取到当然万事大吉大家都能嗨,如果不能,就使用DNS协议来获取IP咯。
2、在DNS协议中,PC会向你的本地DNS服务器求助(一般是路由器),希望从本地DNS服务器 那里得到百度的IP,得到就好,得不到还得向更高层次的DNS服务器求助,最终总能得到百度的IP。
3、得到百度的IP,下一步是使用TCP协议,建立TCP连接。
4、在TCP协议中,建立TCP需要与百度服务器握手三次,你先告诉服务器你要给服务器发东西 (SYN),服务器应答你并告诉你它也要给你发东西(SYN、ACK),然后你应答服务器(ACK),总共来回了3次,称为3次握手。
5、不过,建立TCP连接有个前提(或者说给服务器发消息有个前提):你必须能成功地把消息发到服务器上。虽然已经知道IP,但并无啥用(比如说,你在广东,你知道北京的地理坐标经纬度就能到北京了?你得知道有哪些路通往北京吧你得准备盘缠吧你得花时间吧)。
6、为了将消息从你的PC上传到服务器上,需要用到IP协议、ARP协议和OSPF协议。
我们都知道,你的PC和百度服务器之间一般会有许多路由器之类的东西,IP协议指定了出发地(你的PC)和目的地(服务器);你的数据会经过一个又一个路由器,OSPF决定了会经过那些路由器(用一种叫路由算法的玩意,找出最佳路径);从一个路由器怎么传给下一个路由器?这是ARP协议的JOB,ARP负责求下一个节点的地址(我们不止是要目的地,还要中间节点的地址)。
7、IP协议使用的是IP地址,整个发送过程中只涉及出发地和目的地2个IP地址,而ARP协议使用的是MAC地址,整个发送过程中涉及到每一个节点的MAP地址
8、现在,我们能和服务器通信,还建立了TCP连接,下一步干嘛,当然是用HTTP协议请求网页内容咯。
9、你发个HTTP请求报文给服务器,如果服务器禁止你访问它就给你回个"Forbidden",如果它暂时挂掉了就给你回个“内部服务错误”,如果它正常才给你回个“OK“并将你要的数据传给你;如果你还需要其它的东西再去跟它要(它一般还会给你的-_-)。
10、你收到了服务器的回复,是一坨HTML形式的文本。浏览器必须要能够理解文本的内容,并快速地渲染到屏幕上,渲染出来后,你就看到百度的首页了
5、B树和B+树的区别
B-
树
性质:
是一种多路搜索树(并不是二叉的):
1.
定义任意非叶子结点最多只有
M
个儿子;且
M>2
;
2.
根结点的儿子数为
[2, M]
;
3.
除根结点以外的非叶子结点的儿子数为
[M/2, M]
;
4.
每个结点存放至少
M/2-1
(取上整)和至多
M-1
个关键字;(至少
2
个关键字)
5.
非叶子结点的关键字个数
=
指向儿子的指针个数
-1
;
6.
非叶子结点的关键字:
K[1], K[2], …, K[M-1]
;且
K[i] < K[i+1]
;
7.
非叶子结点的指针:
P[1], P[2], …, P[M]
;其中
P[1]
指向关键字小于
K[1]
的子树,
P[M]
指向关键字大于
K[M-1]
的子树,其它
P[i]
指向关键字属于
(K[i-1], K[i])
的子树;
8.
所有叶子结点位于同一层;
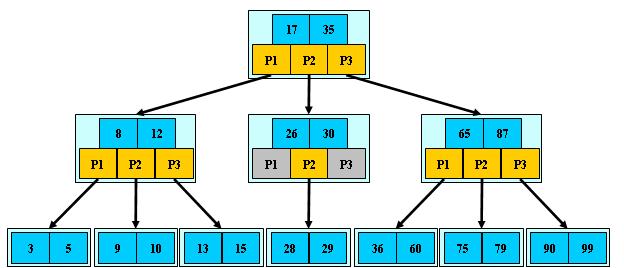
搜索:从根结点开始,对结点内的关键字(有序)序列进行二分查找,如果命中则结束,否则进入查询关键字所属范围的儿子结点;重复,直到所对应的儿子指针为空,或已经是叶子结点;
1.
关键字集合分布在整颗树中;
2.
任何一个关键字出现且只出现在一个结点中;
3.
搜索有可能在非叶子结点结束;
4.
其搜索性能等价于在关键字全集内做一次二分查找;
5.
自动层次控制;
6.
由于限制了除根结点以外的非叶子结点,至少含有
M/2
个儿子,确保了结点的至少利用率,其最底搜索性能为lgN;
7.B-
树的性能总是等价于二分查找(与
M
值无关),没有
B
树平衡的问题;
8.
由于
M/2
的限制,在插入结点时,如果结点已满,需要将结点分裂为两个各占
M/2
的结点;删除结点时,需将两个不足
M/2
的兄弟结点合并;
B+
树
性质:B+
树是
B-
树的变体,也是一种多路搜索树:
1.
其定义基本与
B-
树同,除了:
2.
非叶子结点的子树指针与关键字个数相同;
3.
非叶子结点的子树指针
P[i]
,指向关键字值属于
[K[i], K[i+1])
的子树(
B-
树是开区间);
4.
为所有叶子结点增加一个链指针;
5.
所有关键字都在叶子结点出现;
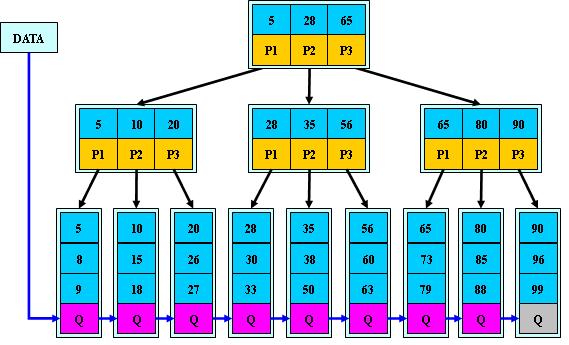
B+
的搜索与
B-
树也基本相同,区别是
B+
树只有达到叶子结点才命中(
B-
树可以在
非叶子结点命中),其性能也等价于在关键字全集做一次二分查找;
B+
的特性:
1.
所有关键字都出现在叶子结点的链表中(稠密索引),且链表中的关键字恰好是有序的;
2.
不可能在非叶子结点命中;
3.
非叶子结点相当于是叶子结点的索引(稀疏索引),叶子结点相当于是存储(关键字)数据的数据层;
4.
更适合文件索引系统;
B*
树
是
B+
树的变体,在
B+
树的非根和非叶子结点再增加指向兄弟的指针;
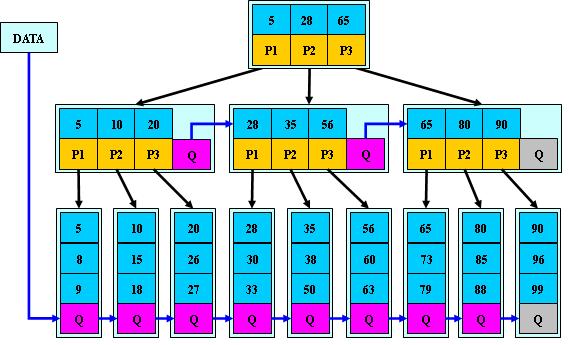
B*
树定义了非叶子结点关键字个数至少为
(2/3)*M
,即块的最低使用率为
2/3
(代替
B+
树的
1/2
);
B+
树的分裂:当一个结点满时,分配一个新的结点,并将原结点中
1/2
的数据复制到新结点,最后在父结点中增加新结点的指针;
B+
树的分裂只影响原结点和父结点,而不会影响兄弟结点,所以它不需要指向兄弟的指针;
B*
树的分裂:当一个结点满时,如果它的下一个兄弟结点未满,那么将一部分数据移到兄弟结点中,再在原结点插入关键字,最后修改父结点中兄弟结点的关键字(因为兄弟结点的关键字范围改变了);如果兄弟也满了,则在原结点与兄弟结点之间增加新结点,并各复制
1/3
的数据到新结点,最后在父结点增加新结点的指针;
所以,
B*
树分配新结点的概率比
B+
树要低,空间使用率更高;
小结:
B
树:二叉树,每个结点只存储一个关键字,等于则命中,小于走左结点,大于走右结点;
B-
树:多路搜索树,每个结点存储
M/2
到
M
个关键字,非叶子结点存储指向关键字范围的子结点;所有关键字在整颗树中出现,且只出现一次,非叶子结点可以命中;
B+
树:在
B-
树基础上,为叶子结点增加链表指针,所有关键字都在叶子结点中出现,非叶子结点作为叶子结点的索引;
B+
树总是到叶子结点才命中;
B*
树:在
B+
树基础上,为非叶子结点也增加链表指针,将结点的最低利用率从
1/2
提高到
2/3
。
6、用户怎么持久的和浏览器的交互
7、线程对同一资源的访问














 530
530











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









