






一、前言:之前的博客已经提到xml主要是用来存储、传输数据的,那么我们如何得到这些数据呢?也就是说怎么来解析xml呢?xml主要有两种解析方式。
二、解析方式原理:
DOM解析:在程序开始执行的时候,先将整个xml文件加载到内存中,在内存中形成一棵Dom树,通过节点以及节点之间的关系来解析xml文件。
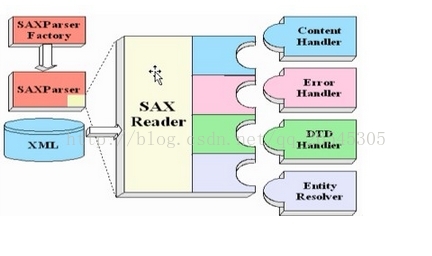
SAX解析:允许读取文档的时候,即对文档进行处理,而不必等到整个文档装载完才进行处理。采用事件处理方式解析xml文件。涉及两部分:解析器和事件处理器。
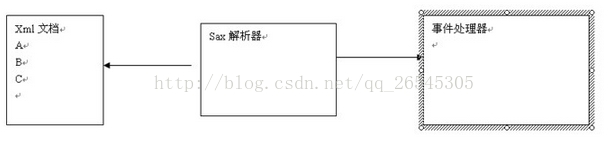
解析器采用SAX方式在解析某个xml文档时,它只要解析到xml文档的一个组成部分,都会去调用事件处理器的一个方法,解析器在调用事件处理器的方法时,会吧当前解析到的xml文件内容作为方法的参数传递给事件处理器。
三、优缺点:
1)DOM解析:
①优点:灵活,适合做曾删改操作,因为整个Dom树都在内存当中。
②缺点:一棵dom树会有很多对象,内存占用大。如果xml文件过大,很可能会导致内存溢出(可以调整JVM内存大小解决)
2)SAX解析:
①优点:占用内存小,解析速度快。
②缺点:只适合读取文档,不适合对文档进行增删改操作。
四、解析开发包:
我们并没有必要亲自编写解析程序,只需要调用解析开发包即可。常见的解析开发包有Jaxp、Jdom、dom4j。其中Jaxp是sun公司的官方解析方式。目前最常见得是dom4j。
五、实例:
实例一:使用Jaxp进行sax解析:
package cn.itcast.sax;
import java.io.IOException;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import org.xml.sax.Attributes;
import org.xml.sax.ContentHandler;
import org.xml.sax.Locator;
import org.xml.sax.SAXException;
import org.xml.sax.XMLReader;
public class Demo1 {
/**
* 使用Jaxp进行 sax 解析xml文档
* @throws SAXException
* @throws ParserConfigurationException
* @throws IOException
*/
public static void main(String[] args) throws ParserConfigurationException, SAXException, IOException {
// TODO Auto-generated method stub
//创建解析工厂
SAXParserFactory factory = SAXParserFactory.newInstance();
//得到解析器
SAXParser sp = factory.newSAXParser();
//得到读取器
XMLReader reader = sp.getXMLReader();
//设置内容处理器
reader.setContentHandler(new ListHandler());
//读取xml文档内容
reader.parse("src/book.xml");
}
}//得到xml文档所有内容
class ListHandler implements ContentHandler{
public void characters(char[] ch, int start, int length) throws SAXException {
System.out.print(new String(ch,start,length));
}
public void endDocument() throws SAXException {
}
public void endElement(String uri, String localName, String name)
throws SAXException {
System.out.print("</"+ name +">");
}
public void endPrefixMapping(String arg0) throws SAXException {
}
public void ignorableWhitespace(char[] arg0, int arg1, int arg2)
throws SAXException {
}
public void processingInstruction(String arg0, String arg1)
throws SAXException {
}
public void setDocumentLocator(Locator arg0) {
}
public void skippedEntity(String arg0) throws SAXException {
}
public void startDocument() throws SAXException {
}
public void startElement(String uri, String localName, String name,
Attributes atts) throws SAXException {
System.out.print("<" + name + ">");
//如何迭代当前 这个对象 Attributes
for(int i=0;atts!=null && i<atts.getLength();i++){ //null,抛空置异常 。巧用for循环
String attName = atts.getQName(i);
String attValue = atts.getValue(i);
System.out.print(attName + "=" + attValue);
}
}
public void startPrefixMapping(String arg0, String arg1)
throws SAXException {
}
}输出结果为:
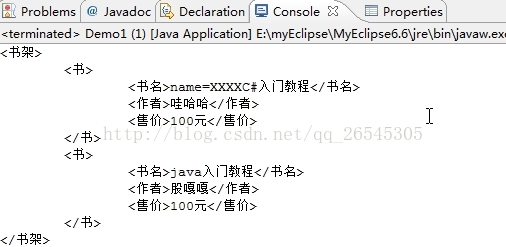
这是将整个xml文档解析出来,当然也可以解析出xml文档的一部分。
实例二:使用dom4j基于sax方式读取xml
package cn.itcast.sax;
import java.io.File;
//使用dom4j方式进行解析
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
public class Demo6 {
public static void main(String[] args) throws DocumentException{
//创建SAX解析器对象
SAXReader reader = new SAXReader();
//读取xml文件
Document document =reader.read(new File("src/book.xml"));
//获取根元素
Element rootElement=document.getRootElement();
System.out.println("根节点的名字:" + rootElement.getName());
}
}
输出结果:

五、总结:
xml的两种解析方式各有优缺点:当需要频繁对xml文件进行增删改操作时,我们选用dom方式进行解析。当仅仅需要读取xml文件时,我们选用sax方式解析。














 2640
2640











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









