







使用到的数据url:https://yunpan.cn/cPHQjv2zPtreC (提取码:fc50)
1.创建测试使用到的数据库,数据字段太多只统计ip
hive> create table blog(ip STRING)> ROW FORMAT DELIMITED> FIELDS TERMINATED BY '\t'> STORED AS TEXTFILE;OKTime taken: 2.832 seconds
2.从HDFS导入数据到HIVE
local data inpath 'HDFS路径' into table blog
本地导入
local data local inpath '本地路径' into table blog
3.分析数据并存储结果
1.
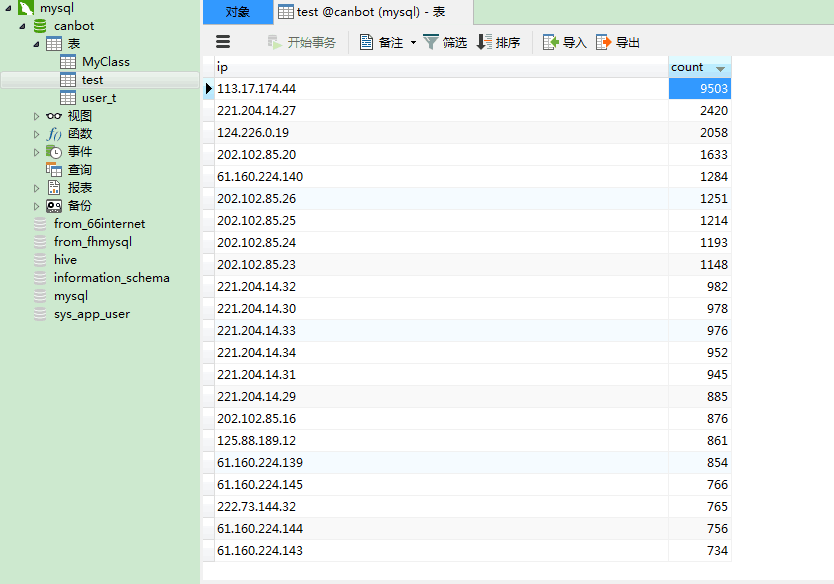
分析结果存储到新的table表中
错误语句
hive> create table hiveIpcount AS> SELECT blog.ip,COUNT(blog.ip) AS count FROM blog> GROUP BY blog.ip> ORDER BY count DESC;BUG后修改语句hive> create table hivecount > ROW FORMAT DELIMITED > FIELDS TERMINATED BY ',' > STORED AS TEXTFILE > AS > SELECT blog.ip,COUNT(blog.ip) AS count FROM blog > GROUP BY blog.ip > ORDER BY count DESC;
注:hive中可以创建带数据的table,所以将“blog”表条件查询出的结果直接导入到hiveIpcount表中
hive> desc hiveIpcount;
OK
ip string None
count bigint None
Time taken: 0.161 seconds, Fetched: 2 row(s)
可以看到分析结果的表已经创建好了,在HDFS中/user/hive/warehouse/
hiveipcount 表的目录存储的就是分析的结果元数据
Bug:
<span style="background-color: rgb(255, 255, 255);">Error: java.io.IOException: Can't export data, please check failed map task logs
at org.apache.sqoop.mapreduce.TextExportMapper.map(TextExportMapper.java:112)
at org.apache.sqoop.mapreduce.TextExportMapper.map(TextExportMapper.java:39)
at org.apache.hadoop.mapreduce.Mapper.run(Mapper.java:145)
at org.apache.sqoop.mapreduce.AutoProgressMapper.run(AutoProgressMapper.java:64)
at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:764)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:340)
at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:168)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1614)
at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:163)
Caused by: java.lang.RuntimeException: Can't parse input data: '183.60.214.2518'
at test.__loadFromFields(test.java:249)
at test.parse(test.java:192)
at org.apache.sqoop.mapreduce.TextExportMapper.map(TextExportMapper.java:83)
... 10 more
Caused by: java.util.NoSuchElementException
at java.util.ArrayList$Itr.next(ArrayList.java:854)
at test.__loadFromFields(test.java:244)
... 12 more</span>
该Bug主要是由于在
hive> create table hiveIpcount AS
> SELECT blog.ip,COUNT(blog.ip) AS count FROM blog
> GROUP BY blog.ip
> ORDER BY count DESC;
HIVE中查看数据显示是空格,但是使用HDFS fs -cat 命令查看却是 使用“
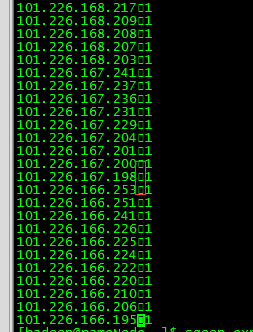
导致导入到MYSQL数据库中报错;
在使用HDFS fs -cat 命令查看元数据
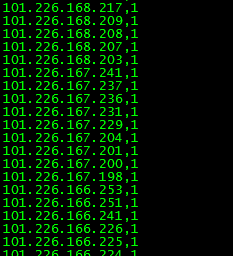















 8586
8586











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









