







3:五子句
1:where子句
1:where原理
1:用来判断数据:筛选数据,where子句返回结果:0或者1,0代表false,1代表true,所以SQL语句是从1开始的
2:where是唯一一个是直接从磁盘获取数据的时候就开始判断的条件,从磁盘取出一条记录,开始进行where判断:判断的结果如果成立就保存到内存中,如果失败则直接放弃
2:SQL语法
1:所以条件判断需要运算符: >,<,<=,>=,=,like模糊,between and区域之间,in/not in
2:逻辑运算符
&&(and),||(or),|(not)
3:案例demo1
业务需求:
找出id为1,3,5的学生
1:使用逻辑判断
select *from 表名 where id=1 || id=3 || id=5
2:落在集合中in(1,3,5)
select * from 表名 where id(1,3,5)

4:案例demo2
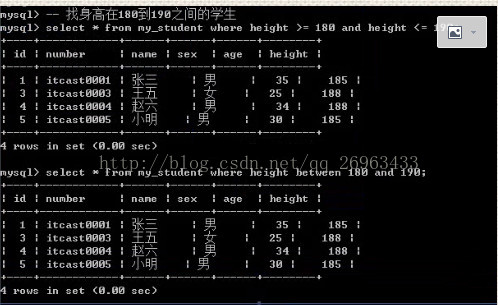
找出身高在180到190之间的学生
select * from my_student where height>=180 and height<=190;
select * from my_student where between 180 and190;
between本身是闭区间;between左边的值必须小于或者等于右边的值
2:group by 分组
1:概述
1:根据某个字段进行分组(相同的放一组,不同的放不同的组)
2:是为了统计数据(按组统计),按分组字段进行数据统计
2:SQL统计函数
1:count(): 统计分组后的记录数: 每一组有多少记录
2:Max() 统计每组中最大的值
3:Min() 统计最小值
4:Avg() 统计平均值
5:Sum() 统计和
1:分组后默认排序
3:案例demo
根据性别分组
1:创建数据库表
USE test
/**创建表*/
CREATE TABLE IF NOT EXISTS test.T_student(
id INT
NOT NULL,PRIMARY KEY (`id`),
number INT,
NAME VARCHAR(10),
gender VARCHAR(3),
age INT,
height LONG
)CHARSET utf8;
添加主键
ALTER TABLE t_student ADD PRIMARY KEY(id);
删除主键
ALTER TABLE t_student DROP PRIMARY KEY;
3:添加自增主键
ALTER TABLE t_student ADD PRIMARY KEY (id);
ALTER TABLE t_student MODIFY id INT AUTO_INCREMENT;
2:插入数据
INSERT INTO t_student(number,NAME,gender,age,height) VALUES(001,'刘菲菲','女',20,165);
INSERT INTO t_student(number,NAME,gender,age,height) VALUES(001,'梦梦','男',22,185);
INSERT INTO t_student(number,NAME,gender,age,height) VALUES(001,'林青霞','女',25,175);

3:查询
1:根据性别进行查询,发现数据丢失

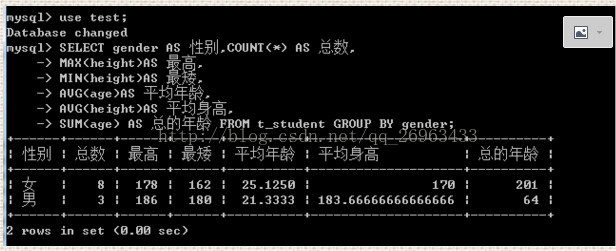
2:/*分组统计:身高,平均年龄,平均身高,总年龄*/
select gender as 性别,count(*) as 总数,
max(height)as 最高,
min(height)as 最矮,
avg(age)as 平均年龄,
avg(height)as 平均身高,
sum(age) as 总的年龄 from t_student group by gender;
2:group by 分组后会自动排序
默认是升序,group by 字段[asc/desc]; --对分组后的结果合并之后的整个结果进行了排序
1:降序
select gender as 性别,count(*) as 总数,
max(height)as 最高,
min(height)as 最矮,
avg(age)as 平均年龄,
avg(height)as 平均身高,
sum(age) as 总的年龄 from t_student group by gender desc;

3:多个字段分组排序
1:创建一个班级表
/**创建表*/
CREATE TABLE IF NOT EXISTS test.T_class(
NAME VARCHAR(20),
room VARCHAR(10)
)CHARSET utf8;
SELECT * FROM T_class;
2:添加主键
alter table t_class add id int primary key auto_increment;
3:插入数据
INSERT INTO T_class(NAME,room) VALUES('国语','201');
INSERT INTO T_class(NAME,room) VALUES('java','202');
INSERT INTO T_class(NAME,room) VALUES('计算机原理','203');
4:学生表添加外键c_id
ALTER TABLE t_student ADD c_id INT;
5:分组多字段查询
1:rand获取随机的id在1-3之间的班级,学生关联的班级是随机的
rand 0-3 ceil 向上取整 1-3
UPDATE T_student SET c_id=CEIL(RAND()*3);

2:多字段分组,先班级,后按男女
select c_id,gender,count(*)from T_student group by c_id,gender;
先根据有关字段进行分组,然后对分组后的结果再次按照其他字段进行连接

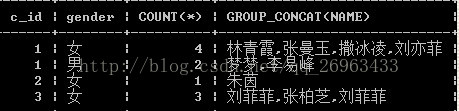
3:group_concat(字段)
完成对分组的结果中的某个字段进行字符串连接(保留改组所有的某个字段,例如学生表中的学生姓名)
SELECT c_id,gender,COUNT(*),GROUP_CONCAT(NAME)
FROM T_student GROUP BY c_id,gender;
4:回溯统计:with rollup
任何一个分组后都会有一个小组,最后都需要向上级分组进行汇报统计,根据当前分组的字段
回溯统计会将分组统计的
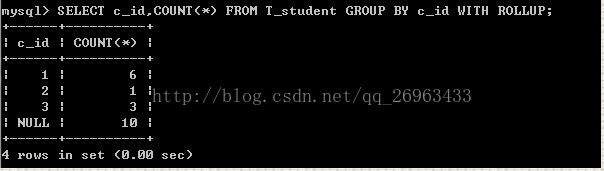
1:单个字段的回溯
select c_id,count(*) from 表名 group by c_id with rollup;
2:多字段回溯
分析第一层分组会有此回溯,第二次分组要看到第一次分组的组数,组数是多少,回溯就是多少,然后加上第一层回溯就行了
SELECT c_id,gender,COUNT(*),GROUP_CONCAT(NAME)
FROM T_student GROUP BY c_id,gender with rollup;

4:hanving 聚合查询
1:having与where的区别
1:having子句同where子句一样,进行条件判断
2:where是针对磁盘进行判断,进入到内存之后,会进行分组操作,分组的结果就需要having进行处理哟
3:having能做where能做的几乎所有的事情,但是where却不能做having能做的很多事情
4:,having能够使用字段别名:where不能,where是从磁盘中取出数据,而名字只可能是字段,别名是字段进行到内存后才会产生
2:案例demo
1:业务需求
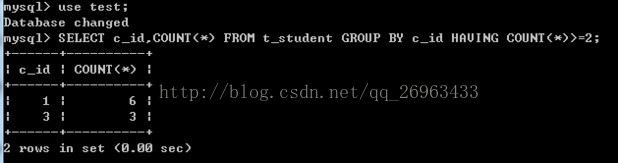
求出所有班级人数大于等于2的学生人数
2:查询语句
select c_id,count(*) from t_student group by c_id having count(*)>=2;
3:注意问题
假如将where放在前面
SELECT c_id,COUNT(*) FROM t_student WHERE COUNT(*)>=2 GROUP BY c_id;

3:案例demo2
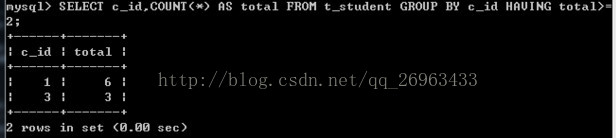
having能够使用字段别名:where不能,
SELECT c_id,COUNT(*) AS total FROM t_student GROUP BY c_id HAVING total>=2;
where不能使用字段别名,因为它是从表中查找
SELECT c_id,COUNT(*) AS total FROM t_student WHERE total>=2 GROUP BY c_id;

4:order by 子句
1:分组后就取一条记录,分组是为了统计
select * from t_student group by c_id;
2:排序,取出所有的记录
select * from t_student order by c_id;
3:排序可以进行多字段排序:
先根据某个字段进行排序,然后排序号的内容,再按照某个字段再次进行排序
1:先班级排序,再性别排序
select * from t_student order by c_id,gender desc;

5:Limit子句
limit子句是一种限制结果的语句:限制数量,主要是为了实现数据的分页:为用户节省时间,提交服务器的响应效率,减少资源的浪费,用户可以点击页面1.2.3.4实现页面的跳转
对于服务器来讲:根据用户选择的页面来获取不同的数据:limit offset,length
length:每页显示的数据量,基本不变的
offset:
offset=(页码-1)*每页显示条数

1:limit有两种使用方式
1:只用来限制长度(数据量);limit数据量
select * from t_student limit 6;
2:限制起始位置,限制数量:limit 起始位置,长度;
查询学生,前两个,记录数总0开始编号
select * from t_student limit 0,2;

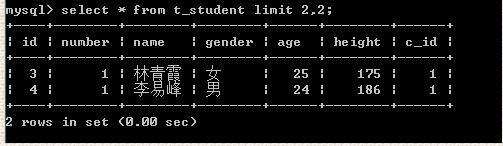
select * from t_student limit 2,2; 从3开始找














 610
610











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









