







BPR 推荐模型基于贝叶斯理论在先验知识下极大化后验概率,实现从一个用户-项目矩阵训练出多个矩阵,且一个矩阵表示一个用户的项目偏好情况来获得用户多个项目的偏序关系下来进行排名的推荐系统。
目前比较主流的推荐系统模型
k近邻的协同过滤:传统的相似矩阵的计算会根据启发式的计算方法,比如皮尔逊相关系数,但是近些年研究,相似矩阵作为模型参数并且根据大量数据训练得出。矩阵分解:矩阵分解在显式反馈和隐式反馈中都是推荐系统中很热门的方法。在近些年研究中,奇异值分解(svd)作为获得特征矩阵的重要方法。但是svd分解存在模型过拟合的问题,正则项的提出解决了模型过拟合的问题。潜在语义模型也在推荐系统中得到应用,Schemdit-Thieme提出把推荐看作是多分类问题,用一些二元分类器来解决。
BPR 推荐模型的特点
*基于item-item推导出个性化i偏好排名。相对于一般的ranking,BPR强调个性化推荐。
*推导用于评估个性化推荐ranking的优化条件即后验概率,并用Roc曲线来类比证实BPR-OPT的可行性。
*为极大化BPR-OPT,提出了BPR-OPT的学习算法。基于随机梯度下降的learnBPR。
*一般的推荐算法是强调用户对项目的打分,只存在用户和单个项目的关系,不去考虑两个项目对用户的影响力。而BPR则从u,i,j出发来求解u,i的大小。
BPR 推荐模型
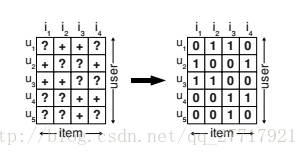
一般的ranking 可能通过对item进行打分高低来排名用户对item的喜欢程度,但是BPR不同,BPR对每一个u都重建一个>u的偏序关系。一般情况下,我们可以获得从大量的数据中制作一个下面这样的矩阵来作为训练集Ds,训练的数据集为三元组即[u,i,j]。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 700
700











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









