








文章:https://docs.timescale.com/v0.9/using-timescaledb/hypertables
TimescaleDB中的Hypertable(超表)被设计为易于管理,并且可以向熟悉标准PostgreSQL表的用户预测行为。 沿着这些路线,在TimescaleDB中创建,更改或删除(超)表的SQL命令与PostgreSQL中的相同。 即使可改变的是由许多相互关联的“块”表组成,对于可改变的自动传播的命令改变为属于该可改变的所有块。
创建一个超表
创建超表有两个步骤:
1、创建一个标准表(PostgreSQL文档)
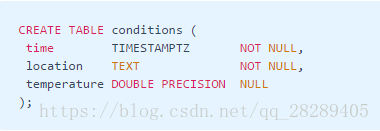
2、然后,在这个新创建的表(API文档)上执行TimescaleDB create_hypertable命令。
提示:如果您需要将现有表中的数据迁移到可更改的表,请务必在调用函数时将migrate_data参数设置为true。 如果您希望更好地控制index的形成和hypertable的其他方面,请按照这些迁移说明进行操作。
警告:使用migrate_data参数转换非空表可以将表锁定很长时间,具体取决于表中的数据量。
提示:create_hypertable函数中使用的'time'列支持时间戳,日期或整数类型,因此您可以使用一个不明确基于时间的参数,只要它可以递增即可。 例如,一个单调递增的id会起作用。
============================================================================
改变hypertable(超表)
可以针对hypertable(PostgreSQL文档)执行标准的ALTER TABLE命令。

然后,TimescaleDB将自动将这些模式更改传播到构成这个可改写的块的块。
警告:如果任何其他列的默认值设置为NULL,则更改表格架构非常有效。 如果默认值设置为非空值,则TimescaleDB将需要为属于该可改写值的所有行(属于所有块)填写此值。============================================================================
删除hypertable(超表)
这只是标准的DROP TABLE命令,其中TimescaleDB将相应地删除属于hypertable的所有块。

============================================================================
最佳实践
TimescaleDB的用户通常有两个常见问题:
1、应该配置多少时间分区间隔?
2、应该使用空间分区吗?应该使用多少个空间分区?时间间隔:TimescaleDB的当前版本不执行自适应时间间隔(尽管这在工作中)。 因此,用户必须通过设置chunk_time_interval(或使用默认值1个月)来创建超级可配置时对其进行配置。 用于新块的间隔可通过调用set_chunk_time_interval来更改。
选择时间间隔的关键属性是,属于最近时间间隔(或使用空间分区时的块)的块(包括索引)适合内存。 因此,我们通常建议设置间隔,以使这些块不超过主存储器的25%。
提示:确保您计划将所有活动的可调整内容放入主内存的25%,而不是每个可调整内容的25%。
要确定这一点,您需要对数据速率有一个大致的了解。 如果您每天大概写入2GB数据并拥有64GB内存,则将时间间隔设置为一周将会很好。 如果您每天在同一台机器上写入10GB,则将时间间隔设置为一天将是适当的。 如果批量加载数据,例如,您每周大容量加载70GB数据,并且数据与整个星期的记录相对应,则此间隔也可以保持。
虽然将块分成小块而非大块通常更安全,但设置间隔太小可能会导致很多块,这对应于某些类型查询的计划延迟增加。
提示:需要注意的是,总块大小实际上取决于基础数据大小和任何索引,因此如果大量使用昂贵的索引类型(例如某些PostGIS地理空间索引),可能需要小心。 在测试期间,您可能会通过块关系大小函数检查您的总块大小。
空间分区:使用额外的分区是一个非常特殊的用例。 大多数用户不需要使用它。
空间分区使用散列:每个不同的项目散列到N个存储桶之一。 请记住,我们已经使用(灵活)时间间隔来管理块大小; 空间分区的主要目的是使并行I / O达到相同的时间间隔。
并行I / O可以在两种情况下受益:(a)两个或更多并发查询应该能够并行读取不同的磁盘,或者(b)单个查询应该能够使用查询并行来并行读取多个磁盘。
注意,PostgreSQL 9.6(和10)中的查询并行化不支持并行查询不同的超表块;查询并行化仅适用于单个物理表(因此是单个块)。我们可能会为此添加自己的支持,但目前不支持。
因此,寻找并行I/O的用户有两种选择:
1、在多个物理磁盘上使用RAID设置,并将单个逻辑磁盘暴露到超表(即,通过单个表空间)。
2、对于每个物理磁盘,向数据库中添加一个单独的表空间。TimescaleDB允许您实际上将多个表空间添加到单个超表中(尽管在覆盖之下,每个基础块将由TimescaleDB映射到单个表空间/物理磁盘)。
我们建议在可能的情况下设置RAID,因为它支持上述两种形式的并行化(即,单独的磁盘查询、并行的多个磁盘的单个查询)。多表空间方法只支持前者。在RAID设置中,不需要空间分区。
也就是说,当使用空间分区时,我们建议每个磁盘使用1个空间分区。
TimescaleDB不会从大量的空间分区中受益(例如分区字段中期望的唯一项的数量)。 大量这样的分区导致较差的每分区负载均衡(使用散列将项目映射到分区),以及某些类型查询的计划延迟大大增加。














 556
556











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









