








文档:https://docs.timescale.com/v0.9/introduction/architecture
概述
TimescaleDB作为PostgreSQL的扩展实现,这意味着Timescale数据库在整个PostgreSQL实例中运行。 该扩展模型允许数据库利用PostgreSQL的许多属性,如可靠性,安全性以及与各种第三方工具的连接性。 同时,TimescaleDB通过在PostgreSQL的查询规划器,数据模型和执行引擎中添加钩子,充分利用扩展可用的高度自定义。
从用户的角度来看,TimescaleDB公开了一些看起来像单数表的称为hypertable的表,它们实际上是一个抽象或许多单独表的虚拟视图,这些表包含称为块的数据。
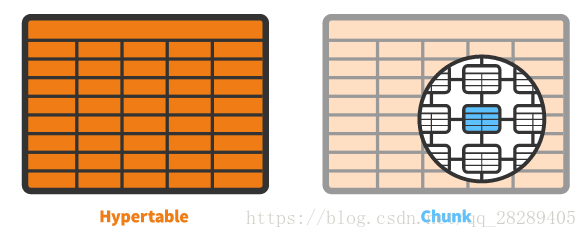
通过将hypertable的数据划分为一个或多个维度来创建块:所有可编程元素按时间间隔进行分区,并且可以通过诸如设备ID,位置,用户ID等的关键字进行分区。我们有时将此称为分区 横跨“时间和空间”。
Hypertables
与数据交互的主要点是一个可以抽象化的跨越所有空间和时间间隔的单个连续表,从而可以通过标准SQL查询它。
实际上,所有与TimescaleDB的用户交互都是使用可调整的。 创建表格和索引,修改表格,插入数据,选择数据等都可以(也应该)在hypertable上执行。 [跳转到基本的SQL操作]
一个带有列名和类型的标准模式定义了一个hypertable,其中至少一列指定了一个时间值,另一列(可选)指定了一个额外的分区键。
提示:请参阅我们的数据模型,进一步讨论各种组织数据的方法,这取决于用例。最简单和最自然的是在“宽表”中,就像许多关系数据库一样。
单个TimescaleDB部署可以存储多个超表,每个超表具有不同的模式。
在TimescaleDB中创建一个超表需要两个简单的SQL命令:创建表(使用标准SQL语法),然后选择CLEATEYHYTABLE()。
可以在超级表上自动创建时间索引和分区键,但也可以创建附加索引(TimescaleDB支持PostgreSQL索引类型的完整范围)。
chunks
在内部,TimescaleDB自动将每个可分区块分割成块,每个块对应于特定的时间间隔和分区键空间的一个区域(使用散列)。 这些分区是不相交的(非重叠的),这有助于查询计划人员最小化它必须接触以解决查询的组块集合。
每个块都使用标准数据库表来实现。 (在PostgreSQL内部,这个块实际上是一个“父”可变的“子表”。)
块是正确的大小,确保表的索引的所有B树可以在插入期间驻留在内存中。 这可以避免在修改这些树中的任意位置时发生颠簸。
此外,通过避免过大的块,我们可以避免根据自动化保留策略删除删除的数据时进行昂贵的“抽真空”操作。 运行时可以通过简单地删除块(内部表)来执行这些操作,而不是删除单独的行。
单点与集群
TimescaleDB在单节点部署和集群部署(开发中)上执行这种广泛的分区。 虽然分区传统上只用于在多台机器上扩展,但它也允许我们扩展到高写入速率(并改进了并行查询),即使在单台机器上也是如此。
TimescaleDB的当前开源版本仅支持单节点部署。 值得注意的是,TimescaleDB的单节点版本已经在商用机器上基于超过100亿行的超级变量进行了基准测试,而且没有插入性能的损失。
单节点分区的好处
在单台计算机上扩展数据库性能的常见问题是内存和磁盘之间的显着成本/性能折衷。最终,我们的整个数据集不适合内存,我们需要将我们的数据和索引写入磁盘。
一旦数据足够大以至于我们无法将索引的所有页面(例如B树)放入内存中,那么更新树的随机部分可能涉及从磁盘交换数据。像PostgreSQL这样的数据库为每个表索引保留一个B树(或其他数据结构),以便有效地找到该索引中的值。所以,当您索引更多列时,问题会复杂化。
但是由于TimescaleDB创建的每个块本身都存储为单独的数据库表,因此它的所有索引都只能建立在这些小得多的表中,而不是代表整个数据集的单个表。所以,如果我们正确地确定这些块的大小,我们可以将最新的表(和它们的B-树)完全放入内存中,并避免交换到磁盘的问题,同时保持对多个索引的支持。
有关TimescaleDB自适应空间/时间组块的动机和设计的更多信息,请参阅我们的技术博客文章。














 292
292











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









