









前文:《如何做到优化引擎搜索SEO(有HTML,关键字,Ajax,url,内容顺序等)》
英文原文来源:clickhelp博客
英文原文:Online Documentation and SEO. Part 2 - Crawler-Friendly Pages
下文均为翻译+自己的注解和想法
(所有ClickHelp打广告部分用浅灰色注解)
翻译:
首先是,爬虫。网络爬虫被搜索引擎用于网页通过URL进行请求的应用。因此,大多数搜索引擎在加载页面时不运行任何脚本…
怎么理解呢。就像是当你在浏览器中禁用脚本,和浏览页面(比如谷歌浏览器有可以设置禁止运行javascript的),如果一些严重依赖页面脚本呈现其内容的(如果用js来控制页面某些内容的显示),网络爬虫就会不完整或不正确的地显示页面。这样就算你做了搜索引擎优化,但是因为爬虫又不运行脚本,你的页面显示不全,做了优化和没做优化的结果差别并不大。
一个标准的网络爬虫的架构的样子:
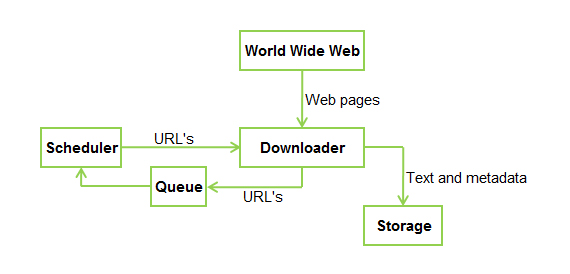
但这又不意味着你不能在你的在线文档中使用脚本。脚本可能会给一些不错的功能和视觉效果的帮助主题内容。在这一点上,对于搜索引擎来说,有一个禁止脚本的页面可以正确索引内容。
(然后就在ClickHelp,我们会注意这些细节,并确保网络爬虫获取主题内容正确。只要使用ClickHelp创建在线文档,你不需要担心网络爬虫不运行脚本啦~)【毕竟翻译人家的,顺便打个广告好做人嘛,但是就不放链接了】
另一个重要的注意——不要忘记metadata与robots name。这个meta标签的值可以显著改变web爬虫程序的行为。例如,<meta name = "googlebot" content = " noindex " / >可以防止页面被谷歌爬虫索引。
更重要的是注意有关robots的txt文件。(在第七篇)
自己的想法:
对于这一篇嘛。。爬虫没有接触过,也不了解它的机制是怎样的,根据图片,翻译下来是这样的
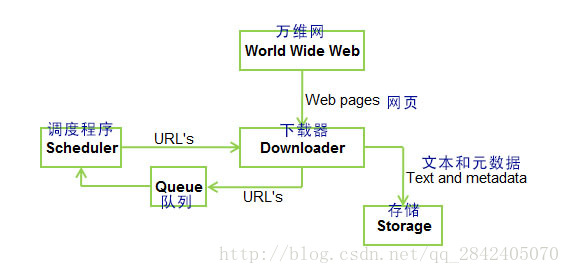
不了解爬虫,这篇无法解释,还请各位自己去看原博加以理解。














 667
667











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









