






即时编译器概述
- 编译器在编译过程中通常会考虑很多因素。比如:汇编指令的顺序。假设我们要将两个寄存器的值进行相加,执行这个操作一般只需要一个CPU周期;但是在相加之前需要将数据从内存读到寄存器中,这个操作是需要多个CPU周期的。编译器一般可以做到,先启动数据加载操作,然后执行其它指令,等数据加载完成后,再执行相加操作。由于解释器在解释执行的过程中,每次只能看到一行代码,所以很难生成上述这样的高效指令序列。而编译器可以事先看到所有代码,因此,一般来说,解释性代码比编译性代码要慢。不过,解释性代码具有可移植性的优势。
- Java的实现在解释性和编译性之间进行了折中。Java代码是编译性的,它会被编译成一个平台独立的字节码程序。JVM负责加载、解释、执行这些字节码程序,在这个过程中,还可能会将这些字节码实时编译成目标机器码,以便提升性能。
- 在本章中,我们主要关注JVM是如何解释、执行、编译字节码的。
编译热点代码
- JVM在解释执行字节码的时候,不会立即对它进行编译。主要原因有两个:
- 如果代码只执行一次,对代码进行编译得不偿失(编译之后还要执行代码)。
- 代码执行的次数越多,JVM可以获取到的信息就越多。JVM就可以在编译代码的时候采用更多的优化手段。比如:JVM经常执行equals()方法,b = obj1.equals(obj2)。JVM需要根据obj1找到它的类型,然后才知道应该执行那个equals函数。这个过程是比较费时的,为了加快执行速度,编译代码的时候可以将类型查找的过程优化掉,直接执行String.equals(obj2)。不过,在实际代码中,可能不会这么简单,obj1的类型会发生变化。但是只要代码执行次数够多,优化后,性能就会有比较大的提升。
基本调优:Client 或 Server
- 即时编译器有两种类型,client和server。 一般情况下,对编译器进行优化,唯一要做的就是选择那一类编译器。
- 可以通过在启动java 的命令中,传入参数(-client 或 -server)来选择编译器(C1或C2)。这两种编译器的最大区别就是,编译代码的时间点不一样。client编译器(C1)会更早地对代码进行编译,因此,在程序刚启动的时候,client编译器比server编译器执行得更快。而server编译器会收集更多的信息,然后才对代码进行编译优化,因此,server编译器最终可以产生比client编译器更优秀的代码。
- 可能大家都有一个困扰,JVM为什么要将编译器分为client和server,为什么不在程序启动时,使用client编译器,在程序运行一段时间后,自动切换为server编译器? 其实,这种技术是存在的,一般称之为: tiered compilation。Java7 和Java 8可以使用选项-XX:+TieredCompilation来打开(-server选项也要打开)。在Java 8中,-XX:+TieredCompilation默认是打开的。
启动优化
- 对于不同类型的应用,使用不同编译器的启动时间:

可以看到,对于中等大小的GUI应用,使用client编译器,启动时间最短,有将近38.5%的提升。对于大型应用,使用各种编译器的启动时间差别不大。
批处理应用优化
- 下图是对第2章中股票应用的性能测试结果,第1列是股票的个数:

观察上图,可以得出以下结论:
1)当股票数比较少的时候(1~100),client编译器完成的最快。
2)当股票数很多的时候,使用server编译器就变得更快了。
3)tiered compilation总是比server编译器要快(和client比,即使在股票数很少的情况下,性能相差也不大),这是因为,tieredcompilation会对一些执行次数较少的代码也进行编译(编译后比解释执行要快)。
长时间运行的应用优化
- 还是利用第2章的例子,这次使用第2章提供的servlet,下图是在不同“warm-up period”下(也就是重要的代码段都被编译了)应用的吞吐量(每秒处理请求的数目)。

观察上图,可以得出以下结论:
1)由于测试周期是60秒,所以,即使warm-up period是0s,server编译器也有足够的时间来发现热点代码并进行编译,所以,server编译器总是比client编译器的吞吐量要高。
2)同样的tiered compilation总是比server编译器的吞吐量要高(原因见上文,批处理应用优化)。
Java和JIT 编译器版本
- JIT编译器主要有以下3大类:
- 32-bit的client版本(-client)
- 32-bit的server版本(-server)
- 64-bit的server版本(-d64)
- 那到底是选择32bit版本还是64bit版本呢? 是不是操作系统是64bit的就选择64位版本呢?
答案并不是这样的,而是需要根据情况确定。
使用32bit版本的优点主要有两个:1)占用内存少,因为对应引用都是32位的 2)性能高,因为CPU操作32位的内存引用要比操作64位的内存引用要快。缺点也有两个:1)使用堆内存的大小不能超过4GB(windows为3GB,Linux为3.5GB) 2)程序中,如果使用了大量的long和double变量,不能充分使用64位寄存器,不过这种情况比较少见。
一般来说,32bit JVM上的32bit编译器要比同样配置的64bit编译器要快5%~20%。
- 64bit版本的JVM无法使用32bit的编译器
- 如果在64bit JVM启动时,使用-client参数,JVM还是会使用server编译器; 如果在32-bit JVM启动时,使用-server参数,则会报错,提醒用户,JVM不支持对应的编译器。
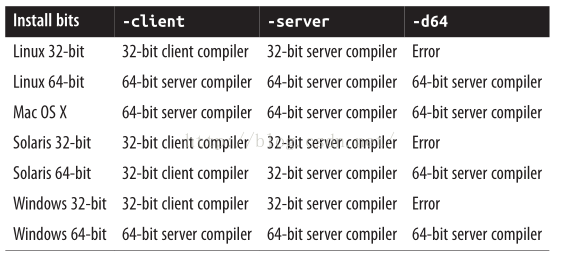
上图是对不同平台下,使用不同参数对应的编译器。
- 对于JAVA 8来说,server编译器是默认编译器,tiered compilation也是默认打开的。
- 对于不同平台,如果没有传入-server或-client参数,则会使用默认的编译器版本,具体如下图所示:

编译器的中间段优化
- 一般情况下,编译器的优化就是选择JVM启动的参数;但是在以下情况还是要进行额外优化的。
Code Cache优化
- JVM在编译代码的时候,会在Code Cache中保存一些汇编指令。由于Code Cache的大小是固定,一旦它被填充满了,JVM就无法编译其它代码了。如果Code Cache很小,就会导致部分热点代码没有被编译,应用的性能将会急剧下降(执行解释性代码)。
- 如果JVM使用了client或tiered compilation编译器,更可能会出现问题;因为它们会对很多类都进行编译。当Code Cache满了的时候,JVM会打印类似于下面的告警信息:
Java HotSpot(TM) 64-Bit Server VM warning: CodeCacheis full.
Compiler has been disabled.
Java HotSpot(TM) 64-Bit Server VM warning: Tryincreasing the
code cache size using -XX:ReservedCodeCacheSize=
- 各个版本的JVM,Code Cache的默认大小,如下图所示:

从上图可以看到,Java7的Code Cache 通常是不够的,一般都需要进行加大。到底增大到多少,这个比较难给出精确值,一般是默认值的2倍或4倍。
- Code Cache 的最大大小,可以通过 -XX:ReservedCodeCacheSize=N来指定,初始大小使用-XX:InitialCodeCacheSize=N来指定。有初始大小是会自动增加的,所以一般不需要设置-XX:InitialCodeCacheSize参数。
- 既然Code Cache 大小会有最大值,我们是否可以设定一个很大的值呢?这个主要看系统资源是否足够。对于32bit的JVM,由于虚拟内存总大小为4GB,所以这个值不能设置的太大;对于64bit的JVM,这个值的大小设置一般不受限制的。
编译阈值
- 是否对代码进行编译受两个计数器的影响:1)方法的调用次数 2)方法内循环的次数 。 当JVM执行一个JAVA方法的时候,它都会检查这两个计数器,以便确定是否需要对方法进行编译。
- 当JVM执行一个JAVA方法的时候,它会检查这两个计数器值的总和,然后确定这个方法是否需要进行编译。如果需要进行编译,这个方法会放入编译队列。这种编译没有官方的名字,一般称之为标准编译。
- 如果方法里面是一个循环,虽然方法只调用一次,但是循环在不停执行。此时,JVM会对这个循环的代码进行编译。这种编译称之为栈上替换OSR(on-stack replacement)。因为即使循环被编译了,这还不够,JVM还需要能够在循环正在执行的时候,转为执行编译后的代码。JVM采用的方式就是将编译后的代码替换当前正在执行的方法字节码。由于方法在栈上执行,所以这个操作又称之为:栈上替换。
- 可以通过配置 -XX:CompileThreshold=N来确定计数器的阈值,从而控制编译的条件。但是如果降低了这个值,会导致JVM没有收集到足够的信息就进行了编译,导致编译的代码优化不够(不过影响会比较小)。
- 如果-XX:CompileThreshold=N配置的两个值(一个大,一个小)在性能测试方面表现差不多,那么会推荐使用小一点的配置,主要有两个原因:
- 可以减小应用的warm-up period。
- 可以防止某个方法永远得不到编译。这是因为JVM会周期(每到安全点的时候)的对计数进行递减。如果阈值比较大,并且方法周期性调用的时间较长,导致计数永远达不到这个阈值,从而不会进行编译。
探寻编译过程
- 选项-XX:+PrintCompilation可以打开编译日志,当JVM对方法进行编译的时候,都会打印一行信息,什么方法被编译了。具体格式如下:
timestamp compilation_idattributes (tiered_level) method_name size deopt
- timestamp是编译时相对于JVM启动的时间戳
- compliation_id是内部编译任务的ID,一般都是递增的
- attributes由5个字母组成,用来显示代码被编译的状态:
- %:编译是OSR
- s:方法是synchronized的
- !:方法有异常处理
- b:编译线程不是后台运行的,而是同步的(当前版本的JVM应该不会打印这个状态了)
- n:表示JVM产生了一些辅助代码,以便调用native 方法
- tiered_level:采用tiered compilation编译器时才会打印。
- method_name:被编译的方法名称,格式是:classname::method
- size: 被编译的代码大小(单位:字节),这里的代码是Java字节码。
- deopt:如果发生了去优化,这里说明去优化的类型。(见下文的说明)
小技巧:使用jstat来查看编译器的行为
% jstat -compiler 5003
Compiled Failed Invalid Time FailedTypeFailedMethod
206 0 0 1.97 0
5003为JVM的进程ID,通过这个命令可以看到有多少个方法被编译了,编译失败有多少个,最后编译失败的方法名字是什么。
% jstat -printcompilation 50031000
CompiledSize Type Method
20764 1 java/lang/CharacterDataLatin1 toUpperCase
2085 1 java/math/BigDecimal$StringBuilderHelper getCharArray
还可以通过上面的命令来周期性(1000的单位为ms,也就是1秒执行一次)的打印编译信息,这样可以看到最后编译的方法名称。
- 编译日志还可以显示一些错误信息,格式如下:
timestamp compile_id COMPILESKIPPED: reason
发生错误的原因主要有两个:
1)Code cache filled:Code Cache空间已经满了,需要使用 ReservedCodeCache标志来增加空间
2)Concurrentclassloading:在编译的过程中,class发生了修改,JVM将会在后面重新编译它。
- 还是使用第2章中的Servlet为例,应用启动后,编译日志如下:
28015 850 net.sdo.StockPrice::getClosingPrice (5bytes)
28179 905 s net.sdo.StockPriceHistoryImpl::process(248 bytes)
28226 25 %net.sdo.StockPriceHistoryImpl::<init> @ 48 (156 bytes)
28244 935net.sdo.MockStockPriceEntityManagerFactory$MockStockPriceEntityManager::find(507 bytes)
29929 939net.sdo.StockPriceHistoryImpl::<init> (156 bytes)
106805 1568 ! net.sdo.StockServlet::processRequest(197 bytes)
通过上面的日志,可以得到下面的结论:
1)第一个方法getClosingPrice直到应用启动后的28s才进行了编译,之前已经有849个方法进行了编译。
2)process方法是synchronized
3)内部类的方法也会单独显示,比如:net.sdo.MockStockPriceEntityManagerFactory$MockStockPriceEntityManager::find
4)processRequest方法有异常处理
5)从StockPriceHistoryImpl的实现看,其中有一个大的loop,
public StockPriceHistoryImpl(String s, Date startDate, Date endDate) {
EntityManager em = emf.createEntityManager();
Date curDate = new Date(startDate.getTime());
symbol = s;
while (!curDate.after(endDate)) {
StockPrice sp = em.find(StockPrice.class, new StockPricePK(s, curDate));
if (sp != null) {
if (firstDate == null) {
firstDate = (Date) curDate.clone();
}
prices.put((Date)curDate.clone(), sp);
lastDate = (Date) curDate.clone();
}
curDate.setTime(curDate.getTime() + msPerDay);
}
}
这个loop执行的次数比构造函数本身多很多,因此这个loop会被采用OSR进行编译。因为OSR编译比较复杂(要在代码同时执行的时候进行编译,还要进行栈上替换),所以虽然它的编译ID很小(25,表明比较早就启动了编译),但是经过了较长时间才在编译日志中打印出来。
编译器的高级调优
- 这一小节主要是对编译器的工作机制细节进行深入讲解,在讲解的过程中会提到响应的调优机制,但是在一般情况,我们很少会对这些参数进行调优。只有JVM的开发人员才会调优这些参数,以便诊断JVM的行为。
编译线程
- 在上文,我们提到过,如果某个方法需要进行编译,它会被放入一个编译队列。这个队列有多个线程进行消费处理。这些线程就是编译线程。
- 编译队列不是严格的FIFO的,而是根据计数器的次数进行排序,这样执行次数最多的代码优先得到编译。
- 如果JVM使用的client编译器,那么,编译线程数目为1; 如果使用的是server编译器,那么,编译线程数目为2; 如果使用的是tiered compilation,那么线程数目和CPU数目相关,具体见下表(和CPU数目具有对数关系):

可以使用 -XX:CICompilerCount=N来调整编译线程的数目;如果使用的是tiered compilation,那么配置的1/3线程用于C1队列,其余的用于C2队列.
- 什么时候需要进行编译线程的调优呢?
- 当使用的单核CPU的时候,使用1个编译线程会提升性能。因为如果编译线程配置的比较多,会加大线程间的调度,降低性能。不过也只会影响“Warm-Up Period”,在这之后,编译线程会无事可做,进入睡眠。
- 当在多核CPU上面同时运行了多个CPU,并且采用了tiered compilation,此时,编译线程会比较多,此时可以适当减少编译线程(不过这么做会拉长“Warm-Up Period“,而且效果一般也不会很显著)
- 另外一个和编译线程相关的参数是:-XX:+BackgroundCompilation,它默认为true,也就是编译线程是后台运行的。如果设置为false,编译线程就是同步的了,也就是说如果方法没有编译完成,它就不会进行执行(也就是不使用解释执行)。如果设置了 -Xbatch参数,也会导致编译线程进入同步执行。
内联
- inline可以提升性能,特别是对于Java中经常使用的get和set方法(它们调用次数很多,并且代码量小),JVM一般都会将它们做内联处理。
- 我们可以通过设置 -XX:-Inline来取消内联,不过我们绝对不会这么做。
- 如何查看方法是否内联了呢?只有debug版本可以看到,加上+PrintInlining参数。
- JVM通过方法执行次数和大小来决定是否内联一个方法。执行次数一般是JVM内部来计算的,没有参数可以控制。对于大小,分为两种情况:
- 如果方法是经常执行的,默认情况下,方法大小小于325字节的都会进行内联(可以通过 -XX:MaxFreqInlineSize=N来设置这个大小)
- 如果方法不是经常执行的,默认情况下,方法大小小于35字节才会进行内联(可以通过 -XX:MaxInlineSize=N 来设置这个大小)
我们可以通过增加这个大小,以便更多的方法可以进行内联;不过一般情况下,调优这个参数对于服务端应用的性能影响不大。
逃逸分析
- 如果逃逸分析打开了(-XX:+DoEscapeAnalysis,默认是打开的),JVM会对代码做一些深度优化。
比如:下面是一个阶乘类,负责存放阶乘的值和起始值。
public class Factorial {
private BigIntegerfactorial;
private int n;
public Factorial(int n) {
this.n = n;
}
public synchronizedBigInteger getFactorial() {
if (factorial == null)
factorial = ...;
return factorial;
}
}
将前100个数的阶乘存入数组:
ArrayList<BigInteger> list = new ArrayList<BigInteger>();
for (int i = 0; i < 100; i++){
Factorial factorial = new Factorial(i);
list.add(factorial.getFactorial());
}
对象factorial只会在for循环内部使用,于是JVM会对这个对象做比较多的优化:
1)不需要对函数getFactorial加锁
2)不需要将字段n保存在内存中,可以存放在寄存器中;同样的,factorial对象也可以保存在寄存器中
3)实际上JVM不会分配任何factorial对象,只需要维护每个对象的字段即可。
逃逸分析默认是打开的,只有在极少数的情况下,逃逸分析会出现问题。
反优化
- 什么是反优化呢?反优化指的是编译器得删除之前编译的代码;它会导致应用的性能下降,直到JVM对代码进行了重新编译。有两种情况会导致反优化:"made not entrant" 和 "made zombie".
Not Entrant Code
- 有两个原因会导致代码不能进入执行。
- 一个和类、接口的工作方式有关。在第二章中,有一个接口StockPriceHistory,它有两种实现:StockPriceHistoryImpl 和 StockPriceHistoryLogger。在Servlet代码中,使用那个类来实例化接口,取决于Servlet传入的参数。
StockPriceHistory sph;
String log = request.getParameter("log");
if (log != null &&log.equals("true")) {
sph = new StockPriceHistoryLogger(...);
}
else {
sph = new StockPriceHistoryImpl(...);
}
// Then the JSP makes calls to:
sph.getHighPrice();
sph.getStdDev();
// and so on
如果开始有大量的 http://localhost:8080/StockServlet 调用(没有log参数),对象sph的真正类型就是StockPriceHistoryImpl 。JVM将会对这个类的构造函数进行内联,并做其它优化。
一段时间之后,有一个调用传入了log参数 http://localhost:8080/StockServlet?log=true , 这会导致之前的优化都变得无效(因为实现类发生了变化,变成StockPriceHistoryLogger) 。于是JVM会对原来编译的代码进行反优化,即:丢弃原来编译的代码,并对代码重新进行编译,然后替换原来编译的代码。上述过程的编译日志大致如下所示:
841113 25 %net.sdo.StockPriceHistoryImpl::<init> @ -2 (156 bytes) made not entrant
841113 937 snet.sdo.StockPriceHistoryImpl::process (248 bytes) made not entrant
1322722 25 %net.sdo.StockPriceHistoryImpl::<init> @ -2 (156 bytes) made zombie
1322722 937 snet.sdo.StockPriceHistoryImpl::process (248 bytes) made zombie
可以看到,OSR编译的构造函数和标准编译的process函数都首先进入made not entrant状态,一段时间后,进入到made zombie状态。
从名字上看,反优化不是一个好的事情,它应该会影响应用的性能。不过,根据实践证明,反优化对性能的影响有限。
- 另外一个就是tiered compilation了。如果JVM采用了tiered compilation,首先它会采用client编译器,随着代码的执行次数不断增加,最终会使用server编译器再次编译代码,并对原有代码进行替换。在替换的过程中,首先将原有代码设置为"not entrant",替换完成后再将原有代码设置为“zombie”。
40915 84 % 3net.sdo.StockPriceHistoryImpl::<init> @ 48 (156 bytes)
40923 3697 3net.sdo.StockPriceHistoryImpl::<init> (156 bytes)
41418 87 % 4net.sdo.StockPriceHistoryImpl::<init> @ 48 (156 bytes)
41434 84 % 3net.sdo.StockPriceHistoryImpl::<init> @ -2 (156 bytes) made not entrant
41458 3749 4net.sdo.StockPriceHistoryImpl::<init> (156 bytes)
41469 3697 3net.sdo.StockPriceHistoryImpl::<init> (156 bytes) made not entrant
42772 3697 3net.sdo.StockPriceHistoryImpl::<init> (156 bytes) made zombie
42861 84 % 3net.sdo.StockPriceHistoryImpl::<init> @ -2 (156 bytes) made zombie
看到上面有很多not entrant和zombie的消息,不要感到惊讶,这些都是正常的,说明JVM编译出了更高效的代码。
反优化Zombie Code
- 通过上面的例子,我们已经看到了什么是zombie code。将原来的代码标识为zombie是有好处的,因为这些代码都是存放在Code Cache当中,而Code Cache的大小是有限的,标识为zombie后,代码占用的空间随之被释放,有利于Code Cache编译其它代码。
Tiered Complication 级别
- 如果JVM采用了Tiered Complication编译器,那么在编译日志中会打印方法编译的层级(见上文的例子)。总共有五个层级,分别如下:
- 0:解释性代码(Interpreted code)
- 1:简单的C1编译代码(Simple C1 compiled code)
- 2:受限的C1编译代码(Limited C1 compiled code)
- 3:完整的C1编译代码(Full C1 compiled code)
- 4:C2编译代码(C2 compiled code)
- 在一般情况下,大部分方法首先在层级3进行编译,随着JVM收集的信息不断增多,最终代码会在层级4进行编译。原来层级3编译的代码会进入到not entrant状态(见上文例子)。
- 如果server队列满了,方法从server队列取出后,使用层级2进行编译(使用C1编译器,但是不会收集更多的信息以便做进一步的优化),使得编译更快,减轻server队列的压力。随着时间的推移,JVM收集到了更多的信息,代码最终会在层级3和层级4进行编译。
- 如果client队列满了,一些本来在等待使用层级3进行编译的方法,也许可以使用层级4进行编译了。此时,这个方法从队列取出后,先使用层级2进行编译(加快速度),随后,直接使用层级4进行编译(不经过层级3)。
- 对于非常小的方法,可能先采用层级2或3进行编译,最终会采用层级1进行编译。
- 如果由于某种原因,server编译器无法对代码进行编译,它会采用层级1进行编译。
- 在反优化的过程中,代码会进入到层级0(解释执行)。
- 如果编译日志中,经常采用层级2进行方法编译,此时需要考虑增加编译线程的数目(增加方法见上文)。














 1191
1191











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









