







一样的月光,一样的你和我……祝中秋快乐,每天有个好心情!!!
爬虫,一种可以自动获取网页信息的程序。
爬虫,根据具体的功能而言,有复杂的系统,也有简易的程序。
这里,我们将探讨一个简易的爬虫,一个简单的思路。
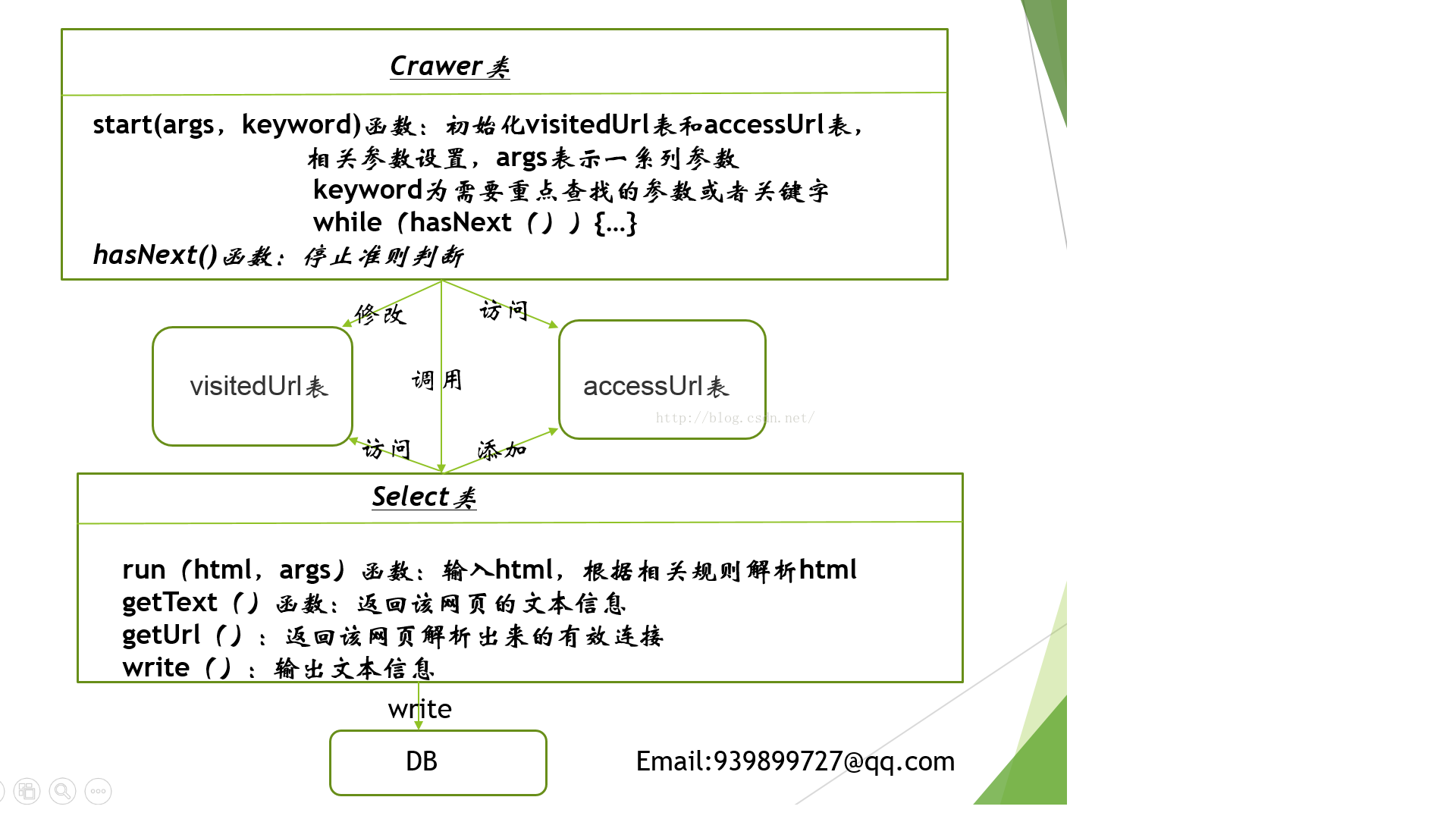
一个爬虫程序,它的功能主要由两部分组成:获取当前链接的网页信息和获取新的链接。
(一)获取当前的网页信息
根据一个具体的链接往往可以得到一个完整的html页面信息。通过对页面信息的分析,我们可以获取新的链接和该html本身的文档信息。
为了获取该文档的文本信息,需要我们对html的格式有一定的基础,这样我们才能解析该html(将这个解析类称为select类)
通过select类run函数的处理,可得到具体的文本信息和新生成的链接。同时假定获取文本信息的函数为getText,获取新链接的信息为getUrl。
(二)获取新的链接
爬虫程序往往会运行相当长的一段时间,直至满足停止条件(称爬虫程序的类为crawer类,检测是否满足停止条件的函数为hasNext函数)。
同时,往往我们会有两张表,一张保存爬虫程序已经访问的Url链接(visitedUrl表),一张保存爬虫程序需要继续访问的表(accessUrl表)。
通过crawer类的启动程序start函数,我们会初始化visitedUrl表和accessUrl表,装载待访问的链接到accessUrl表中,同时开始爬取网页内容。
start函数运行之后,针对每个网页的爬取都会检测是否满足停止条件,获取网页信息之后调用select类的run函数,通过getText和getUrl函数保存文本信息到数据库,同时更新visitedUrl表和accessUrl表。
(三)整个系统的结构
(四)本文仅仅提供一个简单的思路,没有具体的程序。同时在爬取百度搜索的结果时,遇到了一些问题,返回的html中包含有js片段,爬虫程序不能处理js请求等,笔者正在研究。
真诚欢迎各路小伙伴一起讨论。
限于本文作者水平,上诉内容难免有错误,还望大家帮忙纠正。
email:939899727@qq.com














 1834
1834











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









