







声明:
哈喽,大家好,我是谢老师。
今天来学习的是Distributed by 和sort by语法。
首先还是要来回顾一下上一讲所学的join和mapjoin操作。mapjoin会比join快很多,数据量很小的时候优势不明显,数据量很大的时候就快很多了。mapjoin其实就是join的优化。很多人都说Hive语法很简单,跟写sql语句差不多,但是hive优化就比较难了,这一点我也感觉到了。
那设置mapjoin的方式有哪些呢?有两种。我们重新来做一下实验,当做复习。
1 mapjoin的第一种方式:
set hive.auto.convert.join=true;
这里有两个表:
Time taken: 0.311 seconds
hive> select * from city;
OK
20130829234535 china henan nanyang
20130829234536 china henan xinyang
20130829234537 china beijing beijing
20130829234538 china jiang susuzhou
20130829234539 china hubei wuhan
20130829234540 china sandong weizhi
20130829234541 china hebei shijiazhuang
20130829234542 china neimeng eeduosi
20130829234543 china beijing beijing
20130829234544 china jilin jilin
Time taken: 0.169 seconds
hive> select * from province;
OK
20130829234535 china henan nanyang
20130829234536 china henan xinyang
20130829234537 china beijing beijing
20130829234538 china jiang susuzhou
20130829234539 china hubei wuhan
20130829234540 china sandong weizhi
20130829234541 china hebei shijiazhuang
20130829234542 china neimeng eeduosi
20130829234543 china beijing beijing
20130829234544 china jilin jilin
Time taken: 0.131 seconds
hive>
set hive.auto.convert.join=true;
hive> select m.city,n.province
> from
> (select province,city from city)m
> join
> (select province from province)n
> on m.province=n.province;
Total MapReduce jobs = 3
Ended Job = 28094960, job is filtered out (removed at runtime).
Ended Job = -243803491, job is filtered out (removed at runtime).
2016-06-06 06:30:11 Starting to launch local task to process map join; maximum memory = 518979584
2016-06-06 06:30:12 Processing rows: 8 Hashtable size: 8 Memory usage: 5107040 rate: 0.01
2016-06-06 06:30:12 Dump the hashtable into file: file:/tmp/root/hive_2016-06-06_06-30-06_575_9058687622373010883/-local-10002/HashTable-Stage-3/MapJoin-mapfile21--.hashtable
2016-06-06 06:30:12 Upload 1 File to: file:/tmp/root/hive_2016-06-06_06-30-06_575_9058687622373010883/-local-10002/HashTable-Stage-3/MapJoin-mapfile21--.hashtable File size: 752
2016-06-06 06:30:12 End of local task; Time Taken: 1.476 sec.
Execution completed successfully
Mapred Local Task Succeeded . Convert the Join into MapJoin
Mapred Local Task Succeeded . Convert the Join into MapJoin
Launching Job 2 out of 3
Number of reduce tasks is set to 0 since there's no reduce operator
16/06/06 06:30:14 INFO Configuration.deprecation: mapred.job.name is deprecated. Instead, use mapreduce.job.name
16/06/06 06:30:14 INFO Configuration.deprecation: mapred.system.dir is deprecated. Instead, use mapreduce.jobtracker.system.dir
16/06/06 06:30:14 INFO Configuration.deprecation: mapred.local.dir is deprecated. Instead, use mapreduce.cluster.local.dir
Job running in-process (local Hadoop)
Hadoop job information for null: number of mappers: 1; number of reducers: 0
2016-06-06 06:30:26,141 null map = 0%, reduce = 0%
2016-06-06 06:30:40,209 null map = 100%, reduce = 0%, Cumulative CPU 0.92 sec
2016-06-06 06:30:41,299 null map = 100%, reduce = 0%, Cumulative CPU 0.92 sec
2016-06-06 06:30:42,398 null map = 100%, reduce = 0%, Cumulative CPU 0.92 sec
MapReduce Total cumulative CPU time: 920 msec
Ended Job = job_1465200327080_0033
Execution completed successfully
Mapred Local Task Succeeded . Convert the Join into MapJoin
OK
nanyang henan
nanyang henan
xinyang henan
xinyang henan
beijing beijing
beijing beijing
susuzhou jiang
wuhan hubei
weizhi sandong
shijiazhuang hebei
eeduosi neimeng
beijing beijing
beijing beijing
jilin jilin
Time taken: 36.849 seconds
hive>
第二种方式:手动设置
hive> select /*+mapjoin(n)*/ m.city,n.province
> from
> (select province,city from city)m
> join
> (select province from province)n
> on m.province=n.province;
Total MapReduce jobs = 1
2016-06-06 06:32:45 End of local task; Time Taken: 1.648 sec.
Execution completed successfully
Mapred Local Task Succeeded . Convert the Join into MapJoin
Mapred Local Task Succeeded . Convert the Join into MapJoin
Launching Job 1 out of 1
Number of reduce tasks is set to 0 since there's no reduce operator
16/06/06 06:32:47 INFO Configuration.deprecation: mapred.job.name is deprecated. Instead, use mapreduce.job.name
16/06/06 06:32:47 INFO Configuration.deprecation: mapred.system.dir is deprecated. Instead, use mapreduce.jobtracker.system.dir
16/06/06 06:32:47 INFO Configuration.deprecation: mapred.local.dir is deprecated. Instead, use mapreduce.cluster.local.dir
Job running in-process (local Hadoop)
Hadoop job information for null: number of mappers: 1; number of reducers: 0
2016-06-06 06:33:04,292 null map = 0%, reduce = 0%
2016-06-06 06:33:16,471 null map = 100%, reduce = 0%, Cumulative CPU 0.94 sec
2016-06-06 06:33:17,592 null map = 100%, reduce = 0%, Cumulative CPU 0.94 sec
2016-06-06 06:33:18,711 null map = 100%, reduce = 0%, Cumulative CPU 0.94 sec
MapReduce Total cumulative CPU time: 940 msec
Ended Job = job_1465200327080_0034
Execution completed successfully
Mapred Local Task Succeeded . Convert the Join into MapJoin
OK
nanyang henan
nanyang henan
xinyang henan
xinyang henan
beijing beijing
beijing beijing
susuzhou jiang
wuhan hubei
weizhi sandong
shijiazhuang hebei
eeduosi neimeng
beijing beijing
beijing beijing
jilin jilin
Time taken: 47.668 seconds
hive>
有木有发现mapjoin的reducers都是0?
2 **接下来学习的是:
**Dirstribute分散数据
distribute by col按照col列把数据分散到不同的reduce
sorted排序
sort by col2 按照col列把数据排序
hive> select col,col2 from M
> distribute by col
> sort by col asc,col2 desc;
Total MapReduce jobs = 1
Launching Job 1 out of 1
Number of reduce tasks not specified. Estimated from input data size: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapred.reduce.tasks=<number>
16/06/06 06:38:36 INFO Configuration.deprecation: mapred.job.name is deprecated. Instead, use mapreduce.job.name
16/06/06 06:38:36 INFO Configuration.deprecation: mapred.system.dir is deprecated. Instead, use mapreduce.jobtracker.system.dir
16/06/06 06:38:36 INFO Configuration.deprecation: mapred.local.dir is deprecated. Instead, use mapreduce.cluster.local.dir
Job running in-process (local Hadoop)
Hadoop job information for null: number of mappers: 1; number of reducers: 1
2016-06-06 06:38:49,294 null map = 0%, reduce = 0%
2016-06-06 06:39:04,441 null map = 100%, reduce = 0%, Cumulative CPU 1.36 sec
2016-06-06 06:39:05,535 null map = 100%, reduce = 0%, Cumulative CPU 1.36 sec
2016-06-06 06:39:06,628 null map = 100%, reduce = 0%, Cumulative CPU 1.36 sec
2016-06-06 06:39:07,744 null map = 100%, reduce = 0%, Cumulative CPU 1.36 sec
2016-06-06 06:39:08,865 null map = 100%, reduce = 0%, Cumulative CPU 1.36 sec
2016-06-06 06:39:09,929 null map = 100%, reduce = 0%, Cumulative CPU 1.36 sec
2016-06-06 06:39:10,998 null map = 100%, reduce = 0%, Cumulative CPU 1.36 sec
2016-06-06 06:39:12,073 null map = 100%, reduce = 0%, Cumulative CPU 1.36 sec
2016-06-06 06:39:13,136 null map = 100%, reduce = 0%, Cumulative CPU 1.36 sec
2016-06-06 06:39:14,226 null map = 100%, reduce = 0%, Cumulative CPU 1.36 sec
2016-06-06 06:39:15,291 null map = 100%, reduce = 0%, Cumulative CPU 1.36 sec
2016-06-06 06:39:16,376 null map = 100%, reduce = 0%, Cumulative CPU 1.36 sec
2016-06-06 06:39:17,509 null map = 100%, reduce = 100%, Cumulative CPU 2.13 sec
2016-06-06 06:39:18,605 null map = 100%, reduce = 100%, Cumulative CPU 2.13 sec
2016-06-06 06:39:19,687 null map = 100%, reduce = 100%, Cumulative CPU 2.13 sec
MapReduce Total cumulative CPU time: 2 seconds 130 msec
Ended Job = job_1465200327080_0035
Execution completed successfully
Mapred Local Task Succeeded . Convert the Join into MapJoin
OK
A 1
B 2
C 5
C 3
Time taken: 52.716 seconds
hive>
两者结合出现,确保每个reduce的输出都是有序的。
3 【对比】
3.1distribute by 和group by
都是按照key值划分数据
都是使用reduce操作
唯一不同,distribute by 只是单纯的分散数据,而group by 把相同key的数据聚集到一起,后续必须是聚合操作
3.2order by 与sort by
order by 是全局排序
sort by 只是确保每个reduce上面输出的数据有序,如果只有一个reduce时,和order by作用一样
4 应用场景
map输出的文件大小不均
reduce输出文件大小不均
小文件过多
文件超大
5 ****cluseter by**把有相同值得数据聚集到一起,并排序**
效果:
cluster by col
distribute by col order by col
hive> desc city;
OK
time string
country string
province string
city string
Time taken: 2.9 seconds
hive>
创建表city3:
hive> create table city3(
> time string,
> country string,
> province string,
> city string
> )
> row format delimited fields terminated by '\t'
> lines terminated by '\n'
> stored as textfile;
OK
Time taken: 0.731 seconds
hive>
配置参数:
hive> set mapred.reduce.tasks=5; 结果会出现五个文件
hive>insert overwrite table city3
select time,
country,
province,
city
from city
distribute by province;
以province为元素将表格打散,最后会输出五个文件。有图作证。
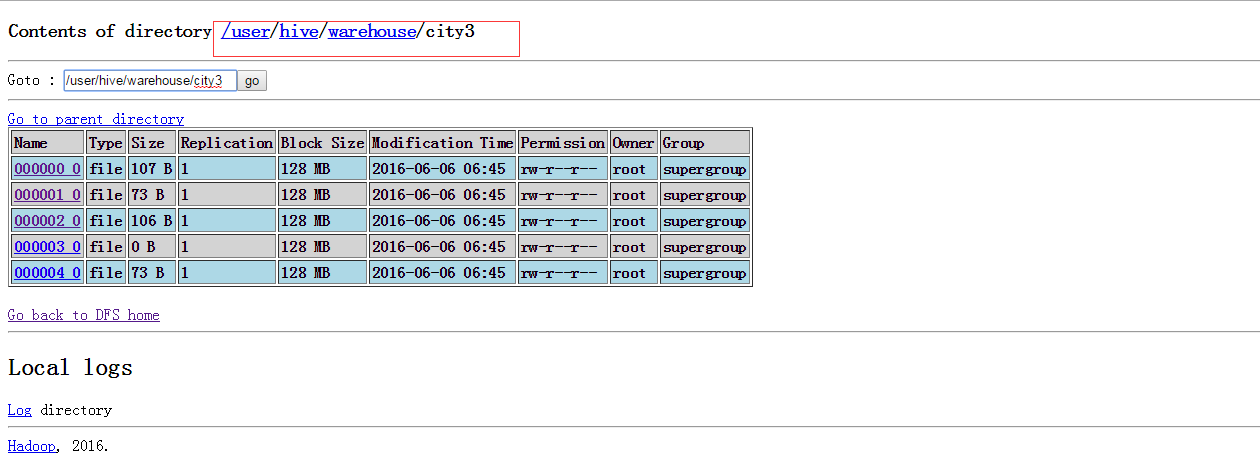
6 把小文件合成一个大文件
set mapred.reduce.tasks=1; 这样子就把文件合成一个了
insert overwrite table city1 partition(dt=‘20160519’)
select time,
country,
province,
city
from province
distribute by country;
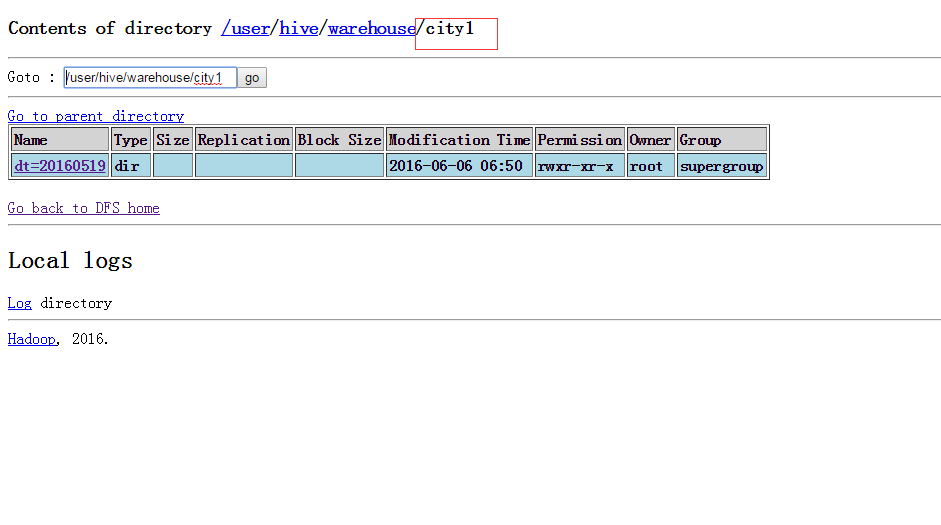
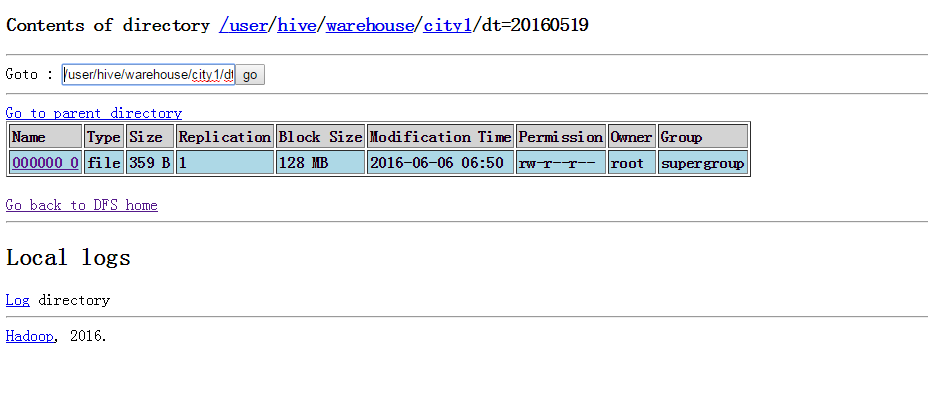
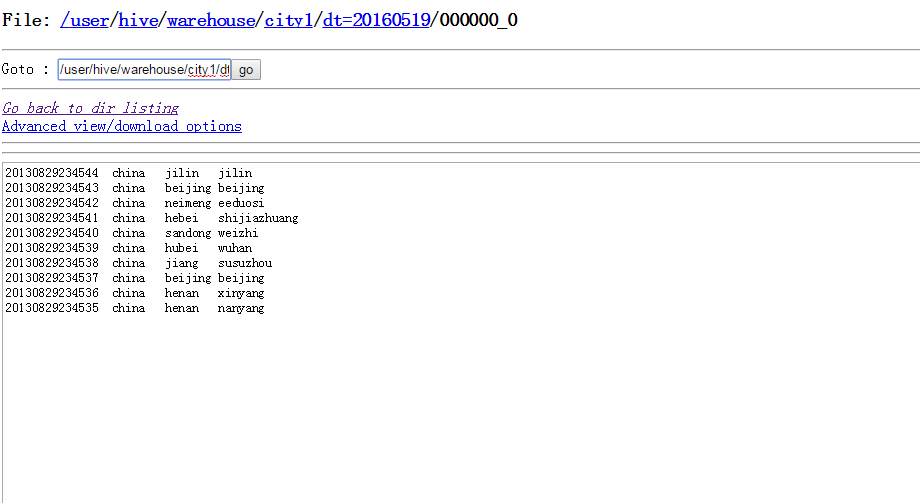
7 union all 操作
多个表的数据合并成一个表,hive不支持union,但是支持union all
样例:
select col
from(
select a as col from t1)
union all
select b as col from t2
)tmp
注意一下:要确保字段类型和别名都要一样。
union执行是比较快的,因为没有reduce操作,只有map操作。
要求:
字段名字一样
字段类型一样
字段个数一样
字段不能有别名
如果需要从合并之后的表中查询
union是不需要别名的,和join不一样
实验一下吧:
hive> select * from(
> select col,col2 from m
> union all
> select col,col3 as col2 from n
> )tmp
> ;
Total MapReduce jobs = 1
Launching Job 1 out of 1
Number of reduce tasks is set to 0 since there's no reduce operator
16/06/06 06:54:23 INFO Configuration.deprecation: mapred.job.name is deprecated. Instead, use mapreduce.job.name
16/06/06 06:54:23 INFO Configuration.deprecation: mapred.reduce.tasks is deprecated. Instead, use mapreduce.job.reduces
16/06/06 06:54:23 INFO Configuration.deprecation: mapred.system.dir is deprecated. Instead, use mapreduce.jobtracker.system.dir
16/06/06 06:54:23 INFO Configuration.deprecation: mapred.local.dir is deprecated. Instead, use mapreduce.cluster.local.dir
Job running in-process (local Hadoop)
Hadoop job information for null: number of mappers: 1; number of reducers: 0
2016-06-06 06:54:35,705 null map = 0%, reduce = 0%
2016-06-06 06:54:47,507 null map = 100%, reduce = 0%, Cumulative CPU 0.98 sec
2016-06-06 06:54:48,615 null map = 100%, reduce = 0%, Cumulative CPU 0.98 sec
2016-06-06 06:54:49,703 null map = 100%, reduce = 0%, Cumulative CPU 0.98 sec
2016-06-06 06:54:50,774 null map = 100%, reduce = 0%, Cumulative CPU 0.98 sec
MapReduce Total cumulative CPU time: 980 msec
Ended Job = job_1465200327080_0038
Execution completed successfully
Mapred Local Task Succeeded . Convert the Join into MapJoin
OK
C 4
D 5
A 6
A 1
C 5
B 2
C 3
Time taken: 31.35 seconds
hive>
好了,有点累了,今天就先玩到这里吧。如果你看到此文,想进一步学习或者和我沟通,加我微信公众号:名字:谢华东
















 428
428











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











