







1、 爬用户的信息
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3088.4 Safari/537.36'}
Cookies={'Cookie':'ALF=1496922421; SCF=Arp26DLiVfzVu5csW81QpVvZyGluHHNLIe8z6eVFr9c7gA6g38fGoFXC6FTk2hwAWieSwX1UOz333tyjm9GipnI.; + \
SUB=_2A250FboODeRhGeRN41QZ8y_FwjmIHXVX-cZGrDV6PUJbktBeLUTykW1mqpP-7J46zMkHwLZNZMejo05wbw..; + \
SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9WWgX0wXfSMCzFQ9GvxhMXZc5JpX5o2p5NHD95QEe0nc1hep1K.fWs4DqcjTHsyL9svV9NWjqgRt; SUHB=0P1NBKwWiWd4ug; SSOLoginState=1494338142;+ \
_T_WM=3a3a0875977ca7524e9ecdd21c980cb0; M_WEIBOCN_PARAMS=featurecode%3D20000320%26oid%3D4100400447924616% +\
26luicode%3D10000011%26lfid%3D2302831655128924%26fid%3D1005051655128924%26uicode%3D10000011'}
def get_user_info(user_id):
url = 'http://m.weibo.cn/api/container/getIndex?type=uid&value={user_id}'.format(user_id=user_id)
resp = requests.get(url,headers=headers,cookies=Cookies)
jsondata = resp.json()
#print(jsondata)
nickname = jsondata.get('userInfo').get('screen_name')
mlog_num = jsondata.get('userInfo').get('statuses_count')
verified = jsondata.get('userInfo').get('verified')
verified_reason = jsondata.get('userInfo').get('verified_reason')
descreption = jsondata.get('userInfo').get('description')
gender = jsondata.get('userInfo').get('gender')
urank = jsondata.get('userInfo').get('urank') # 用户等级
mbrank = jsondata.get('userInfo').get('mbrank')
followers_counts = jsondata.get('userInfo').get('followers_count')
follow_counts = jsondata.get('userInfo').get('follow_count')
try:
uid = jsondata.get('userInfo').get('toolbar_menus')[0].get('params').get('uid')
fid = jsondata.get('userInfo').get('toolbar_menus')[1].get('actionlog').get('fid')
oid = jsondata.get('userInfo').get('toolbar_menus')[2].get('params').get('menu_list')[0].get('actionlog').get('oid')
cardid = jsondata.get('userInfo').get('toolbar_menus')[1].get('actionlog').get('cardid')
except:
uid = ''
fid = ''
oid = ''
cardid = ''
containerid = jsondata.get('tabsInfo').get('tabs')[1].get('containerid')
user_info = {'nickname':nickname,'mlog_num':mlog_num,'verified':verified,'verified_reason':verified_reason,
'gender':gender,'urank':urank,'mbrank':mbrank,'followers_count':followers_counts,
'follow_count':follow_counts,'uid':uid,'fid':fid,
'cardid':cardid,'containerid':containerid,'oid':oid,'desc':descreption}
print(user_info)
return user_info
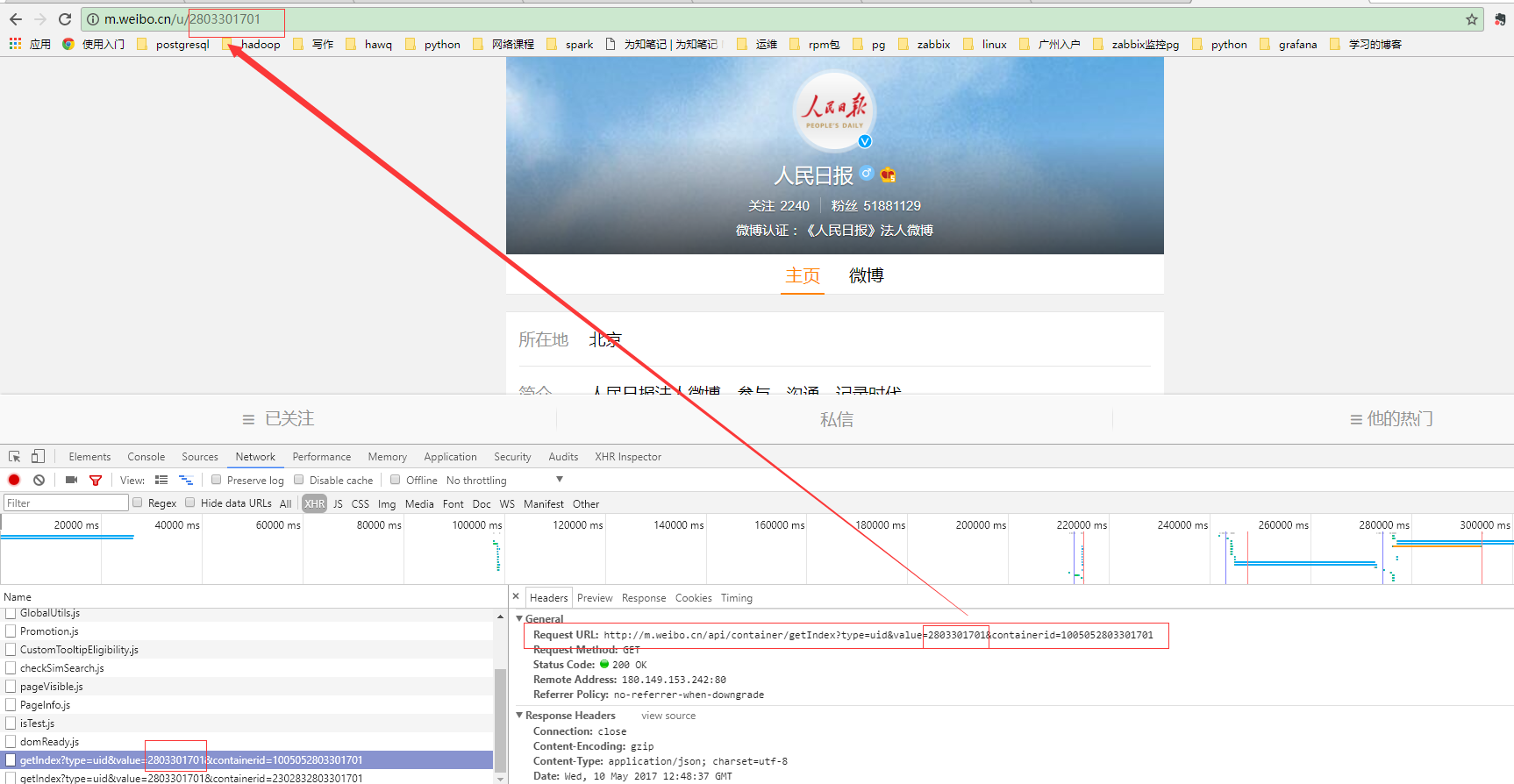
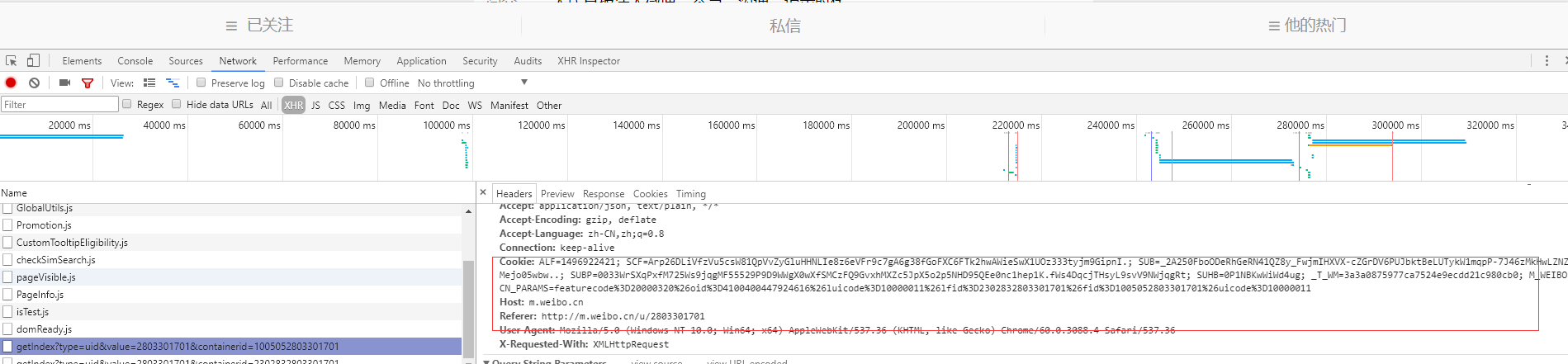
###1-1. 哪里找cookies?
输入网址:http://m.weibo.cn/u/2803301701
###1-2. 哪里找用户信息?
用Firefox打开:http://m.weibo.cn/api/container/getIndex?type=uid&value=2803301701&containerid=1005052803301701
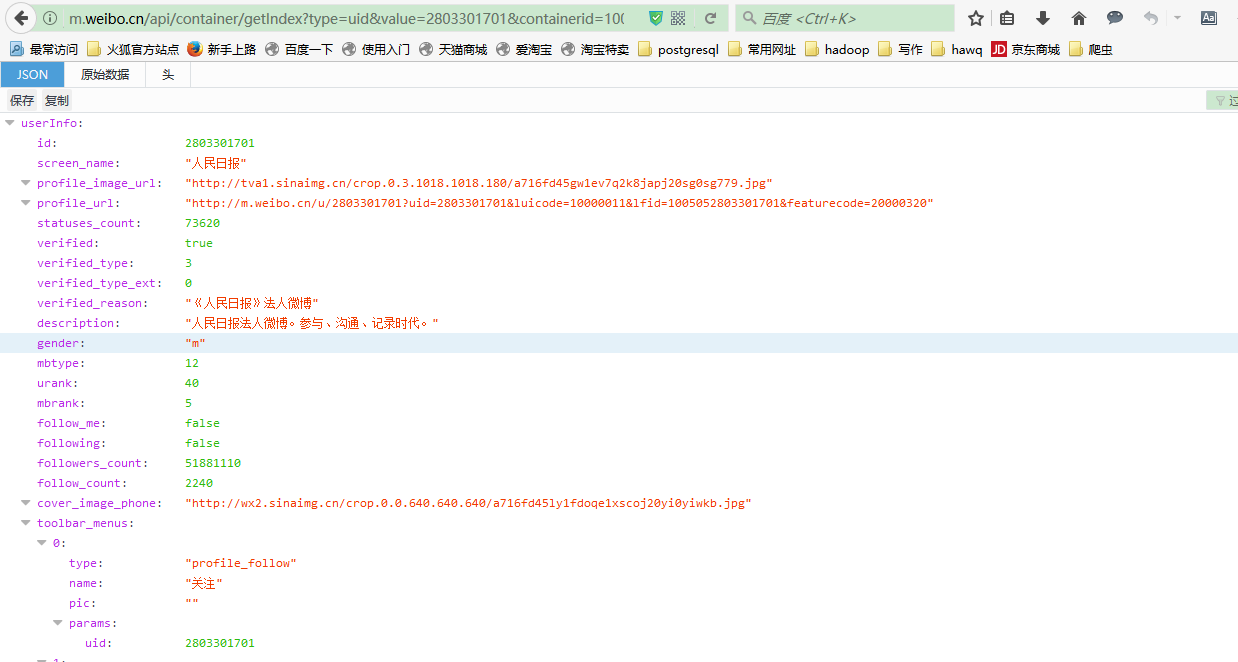
发现全部都是以json的数据格式,然后解析就行了。
2、 爬用户发过的所有博客
#获取素有热门微博信息(所发微博内容,每条微博的评论id,转发数,评论数.....)
def mlog_list(uid,oid):
Mlog_list = []
base_url = 'http://m.weibo.cn/api/container/getIndex?type=uid&value={uid}&containerid={oid}'
page_url = 'http://m.weibo.cn/api/container/getIndex?type=uid&value={uid}&containerid={oid}&page={page}'
url = base_url.format(uid = uid,oid = oid)
print(url)
resp = requests.get(url,headers=headers,cookies=Cookies)
resp.encoding='gbk'
response = resp.json()
#print(response)
#热门微博total
total = response['cardlistInfo']['total']
print(total)
#热门微博网页数
page_num = int(int(total) / 10) + 1
print(page_num)
for i in range(1, page_num + 1):
p_url = page_url.format(oid=oid, uid=uid, page=i)
#print(i,p_url)
page_resp = requests.get(p_url,headers=headers,cookies = Cookies)
page_data = page_resp.json()
#print(page_data)
try:
cards = page_data['cards']
for card in cards:
mblog = card['mblog']
created_at = mblog['created_at']
id = mblog['id']
dirty_text = mblog['text']
cleaned1 = re.sub(r'<span.*?</span>','',dirty_text)
text = re.sub(r'<a.*?></a>','',cleaned1)
reposts_count = mblog['reposts_count']
comments_count = mblog['comments_count']
attitudes_count = mblog['attitudes_count']
mblog_data = {'created_at': created_at, 'id': id, 'text': text, 'reposts_count': reposts_count,
'comments_count': comments_count, 'attitudes_count': attitudes_count}
Mlog_list.append(mblog_data)
print('*'*10,mblog_data)
except:
continue
time.sleep(1)
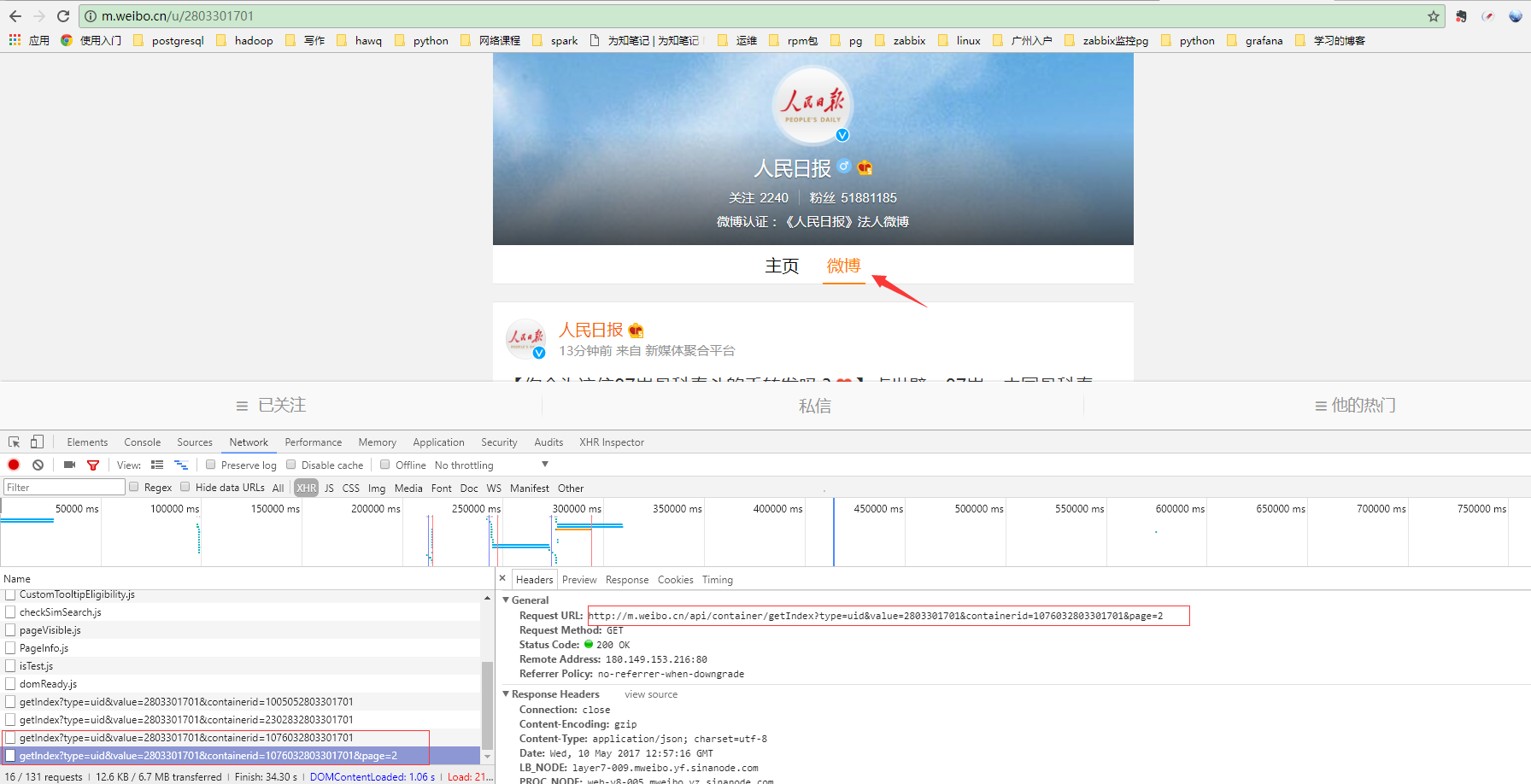
2-1.哪里找url入口?
入口:
http://m.weibo.cn/api/container/getIndex?type=uid&value=2803301701&containerid=1076032803301701
http://m.weibo.cn/api/container/getIndex?type=uid&value=2803301701&containerid=1076032803301701&page=2
比较以上两个url,发现value={},containerid={},page={}是有规律的。
2-2.怎么得到博客数据?
用Firefox打开以上两个url:
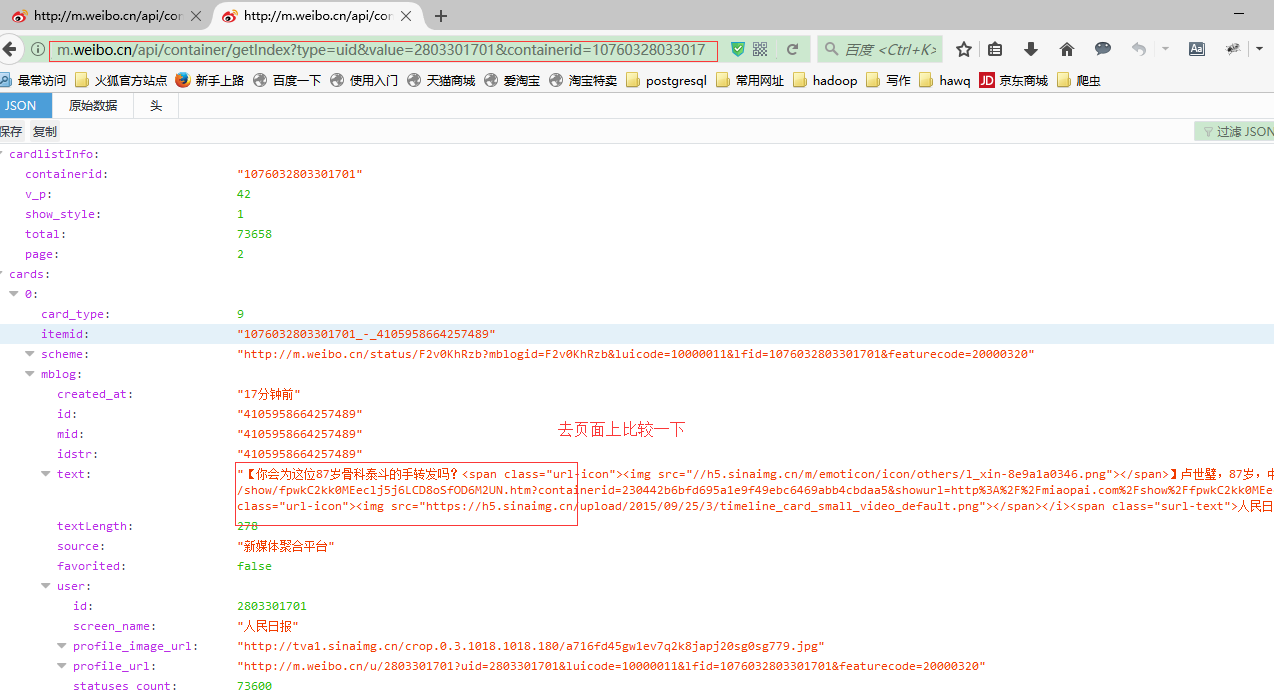
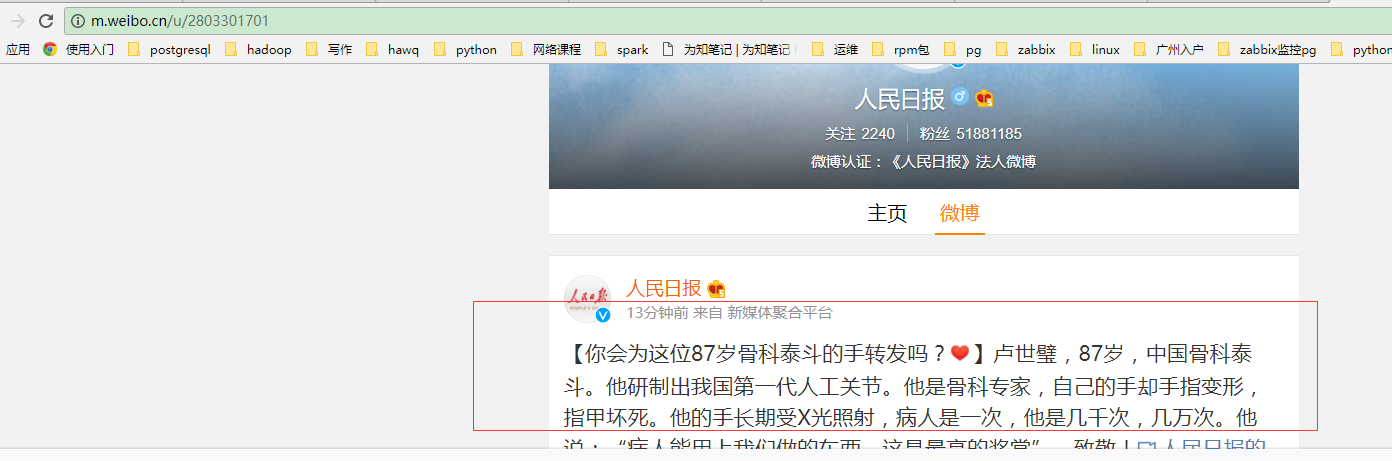
发现全部是json数据,然后解析就行了。
解析完了保存为字典格式。
3、 主函数
def main():
#user_id= '1655128924'
#user_id='2736225585'
#user_id = '2386831995'
user_id= '2368289191'
user_info = get_user_info(user_id)
uid = user_info.get('uid')
oid = user_info.get('containerid')
print(uid,oid)
mlog_list(uid,oid)
main()
4、 所有代码
import requests
import time
import re
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3088.4 Safari/537.36'}
Cookies={'Cookie':'ALF=1496922421; SCF=Arp26DLiVfzVu5csW81QpVvZyGluHHNLIe8z6eVFr9c7gA6g38fGoFXC6FTk2hwAWieSwX1UOz333tyjm9GipnI.; + \
SUB=_2A250FboODeRhGeRN41QZ8y_FwjmIHXVX-cZGrDV6PUJbktBeLUTykW1mqpP-7J46zMkHwLZNZMejo05wbw..; + \
SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9WWgX0wXfSMCzFQ9GvxhMXZc5JpX5o2p5NHD95QEe0nc1hep1K.fWs4DqcjTHsyL9svV9NWjqgRt; SUHB=0P1NBKwWiWd4ug; SSOLoginState=1494338142;+ \
_T_WM=3a3a0875977ca7524e9ecdd21c980cb0; M_WEIBOCN_PARAMS=featurecode%3D20000320%26oid%3D4100400447924616% +\
26luicode%3D10000011%26lfid%3D2302831655128924%26fid%3D1005051655128924%26uicode%3D10000011'}
def get_user_info(user_id):
url = 'http://m.weibo.cn/api/container/getIndex?type=uid&value={user_id}'.format(user_id=user_id)
resp = requests.get(url,headers=headers,cookies=Cookies)
jsondata = resp.json()
#print(jsondata)
nickname = jsondata.get('userInfo').get('screen_name')
mlog_num = jsondata.get('userInfo').get('statuses_count')
verified = jsondata.get('userInfo').get('verified')
verified_reason = jsondata.get('userInfo').get('verified_reason')
descreption = jsondata.get('userInfo').get('description')
gender = jsondata.get('userInfo').get('gender')
urank = jsondata.get('userInfo').get('urank') # 用户等级
mbrank = jsondata.get('userInfo').get('mbrank')
followers_counts = jsondata.get('userInfo').get('followers_count')
follow_counts = jsondata.get('userInfo').get('follow_count')
try:
uid = jsondata.get('userInfo').get('toolbar_menus')[0].get('params').get('uid')
fid = jsondata.get('userInfo').get('toolbar_menus')[1].get('actionlog').get('fid')
oid = jsondata.get('userInfo').get('toolbar_menus')[2].get('params').get('menu_list')[0].get('actionlog').get('oid')
cardid = jsondata.get('userInfo').get('toolbar_menus')[1].get('actionlog').get('cardid')
except:
uid = ''
fid = ''
oid = ''
cardid = ''
containerid = jsondata.get('tabsInfo').get('tabs')[1].get('containerid')
user_info = {'nickname':nickname,'mlog_num':mlog_num,'verified':verified,'verified_reason':verified_reason,
'gender':gender,'urank':urank,'mbrank':mbrank,'followers_count':followers_counts,
'follow_count':follow_counts,'uid':uid,'fid':fid,
'cardid':cardid,'containerid':containerid,'oid':oid,'desc':descreption}
print(user_info)
return user_info
#获取素有热门微博信息(所发微博内容,每条微博的评论id,转发数,评论数.....)
def mlog_list(uid,oid):
Mlog_list = []
base_url = 'http://m.weibo.cn/api/container/getIndex?type=uid&value={uid}&containerid={oid}'
page_url = 'http://m.weibo.cn/api/container/getIndex?type=uid&value={uid}&containerid={oid}&page={page}'
url = base_url.format(uid = uid,oid = oid)
print(url)
resp = requests.get(url,headers=headers,cookies=Cookies)
resp.encoding='gbk'
response = resp.json()
#print(response)
#热门微博total
total = response['cardlistInfo']['total']
print(total)
#热门微博网页数
page_num = int(int(total) / 10) + 1
print(page_num)
for i in range(1, page_num + 1):
p_url = page_url.format(oid=oid, uid=uid, page=i)
#print(i,p_url)
page_resp = requests.get(p_url,headers=headers,cookies = Cookies)
page_data = page_resp.json()
#print(page_data)
try:
cards = page_data['cards']
for card in cards:
mblog = card['mblog']
created_at = mblog['created_at']
id = mblog['id']
dirty_text = mblog['text']
cleaned1 = re.sub(r'<span.*?</span>','',dirty_text)
text = re.sub(r'<a.*?></a>','',cleaned1)
reposts_count = mblog['reposts_count']
comments_count = mblog['comments_count']
attitudes_count = mblog['attitudes_count']
mblog_data = {'created_at': created_at, 'id': id, 'text': text, 'reposts_count': reposts_count,
'comments_count': comments_count, 'attitudes_count': attitudes_count}
Mlog_list.append(mblog_data)
print('*'*10,mblog_data)
except:
continue
time.sleep(1)
def main():
#user_id= '1655128924'
#user_id='2736225585'
#user_id = '2386831995'
user_id= '2368289191'
user_info = get_user_info(user_id)
uid = user_info.get('uid')
oid = user_info.get('containerid')
print(uid,oid)
mlog_list(uid,oid)
main()
谢谢各位收看的朋友。这篇文章,我也是参考了别人的写法,然后自己研究了一把。写得不好的地方,欢迎留言和联系。谢谢
















 778
778











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











