







(1)Partitioner组件可以让Map对Key进行分区,从而可以根据不同的key来分发到不同的reduce中去处理;
(2)你可以自定义key的一个分发股则,如数据文件包含不同的省份,而输出的要求是每个省份输出一个文件;
(3)提供了一个默认的HashPartitioner。
自定义Partitioner:
(1)继承抽象类Partitioner,实现自定义的getPartition()方法;
(2)通过job.setPartitionerClass()来设置自定义的Partitioner;
Partitioner类见org.apache.hadoop.mapreduce.Partitioner类。
Partitioner应用场景:
需求:分别统计每种商品的周销售情况
site1的周销售清单(
a.txt):
shoes
hat
stockings 30
clothes
......
site2的周销售清单(
b.txt):
shoes
hat
stockings 90
clothes
......
汇总结果:
shoes
hat
stockings 120
clothes
新建项目TestPartitioner,包com.Partitioner,
源代码MyMapper.java:
package com.partitioner;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class MyMapper extends Mapper {
@Override
protected void map(LongWritable key, Text value,Contextcontext)
throws IOException, InterruptedException {
String[] s = value.toString().split("\\s+");
context.write(new Text(s[0]), newIntWritable(Integer.parseInt(s[1])));
}
}
源代码MyReduer.java:
package com.partitioner;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class MyReduer extends Reducer {
@Override
protected void reduce(Text key, Iterable value,Contextcontext)
throws IOException, InterruptedException {
int sum = 0;
for(IntWritable val:value){
sum += val.get();
}
context.write(key, new IntWritable(sum));
}
}
源代码MyPartitioner.java:
package com.partitioner;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
public class MyPartitioner extends Partitioner {
@Override
public int getPartition(Text key, IntWritable value, intnumPartitons) {
return 3;
}
}
源代码TestPartitioner.java:
package com.partitioner;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
importorg.apache.hadoop.mapreduce.lib.input.FileInputFormat;
importorg.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class TestPartitioner {
}
将此项目打包为TestPartitioner.jar,并将上面提到的a.txt和b.txt上传到hdfs上的/input文件夹下,
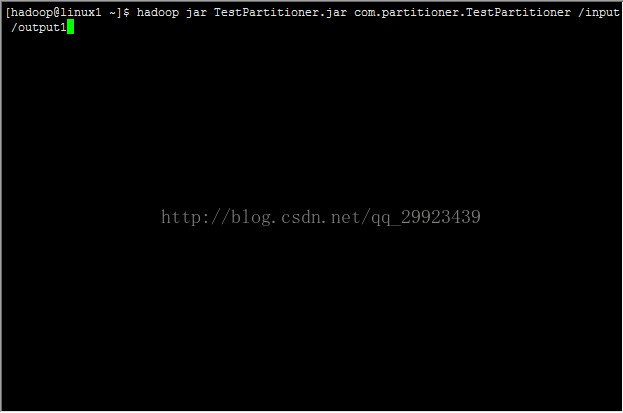
运行TestPartitioner.jar:
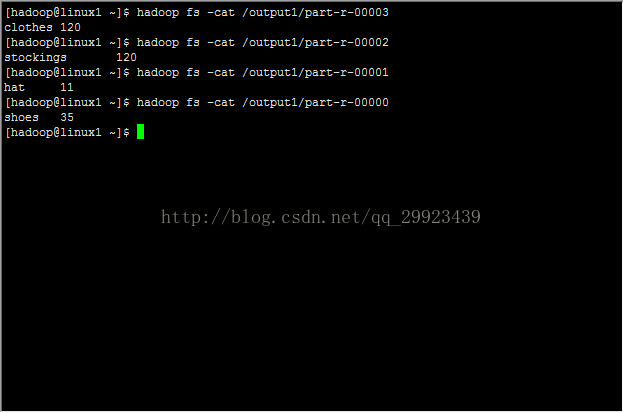
可以看到四个reducer产生的文件:
其中内容,可见统计结果分开了:














 256
256











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









