







基于支持向量机SVM的文本分类的实现
1 SVM简介
支持向量机(SVM)算法被认为是文本分类中效果较为优秀的一种方法,它是一种建立在统计学习理论基础上的机器学习方法。该算法基于结构风险最小化原理,将数据集合压缩到支持向量集合,学习得到分类决策函数。这种技术解决了以往需要无穷大样本数量的问题,它只需要将一定数量的文本通过计算抽象成向量化的训练文本数据,提高了分类的精确率。
支持向量机(SVM)算法是根据有限的样本信息,在模型的复杂性与学习能力之间寻求最佳折中,以求获得最好的推广能力支持向量机算法的主要优点有:
(1)专门针对有限样本情况,其目标是得到现有信息下的最优解而不仅仅是样本数量趋于无穷大时的最优值;
(2)算法最终转化为一个二次型寻优问题,理论上得到的是全局最优点,解决了在神经网络方法中无法避免的局部极值问题;
(3)支持向量机算法能同时适用于稠密特征矢量与稀疏特征矢量两种情况,而其他一些文本分类算法不能同时满足两种情况。
(4)支持向量机算法能够找出包含重要分类信息的支持向量,是强有力的增量学习和主动学习工具,在文本分类中具有很大的应用潜力。
2 基于SVM的文本分类过程
SVM 文本分类算法主要分四个步骤:文本特征提取、文本特征表示、归一化处理和文本分类。
2.1文本特征提取
目前,在对文本特征进行提取时,常采用特征独立性假设来简化特征选择的过程,达到计算时间和计算质量之间的折中。一般的方法是根据文本中词汇的特征向量,通过设置特征阀值的办法选择最佳特征作为文本特征子集,建立特征模型。(特征提取前,先分词,去停用词)。
本特征提取有很多方法,其中最常用的方法是通过词频选择特征。先通过词频计算出权重,按权重从大到小排序,然后剔除无用词,这些词通常是与主题无关的,任何类的文章中都有可能大量出现的,比如“的”“是”“在”一类的词,一般在停词表中已定义好,去除这些词以后,有一个新的序列排下来,然后可以按照实际需求选取权重最高的前8个,10个或者更多词汇来代表该文本的核心内容。
综上所述,特征项的提取步骤可以总结为:
(1)对全部训练文档进行分词,由这些词作为向量的维数来表示文本;
(2)统计每一类内文档所有出现的词语及其频率,然后过滤,剔除停用词和单字词;
(3)统计每一类内出现词语的总词频,并取其中的若干个频率最高的词汇作为这一类别的特征词集;
(4)去除每一类别中都出现的词,合并所有类别的特征词集,形成总特征词集。最后所得到的特征词集就是我们用到的特征集合,再用该集合去筛选测试集中的特征。
2.2文本特征表示
TF-IDF 公式来计算词的权值:
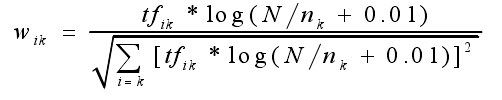
其中tfik表示特诊次tk在文档di中出现的频率,N为训练文档总数,nk为在训练集中出现词tk的文档数。由TF-IDF公式,一批文档中某词出现的频率越高,它的区分度则越小,权值也越低;而在一个文档中,某词出现的频率越高,区分度则越大,权重越大。
2.3归一化处理
归一化就是要把需要处理的数据经过处理后(通过某种算法)限制在你需要的一定范围内。
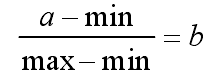
公式中a为关键词的词频,min为该词在所有文本中的最小词频,max为该词在所有文本中的最大词频。这一步就是归一化,当用词频进行比较时,容易发生较大的偏差,归一化能使文本分类更加精确。
2.4文本分类
经过文本预处理、特征提取、特征表示、归一化处理后,已经把原来的文本信息抽象成一个向量化的样本集,然后把此样本集与训练好的模板文件进行相似度计算,若不属于该类别,则与其他类别的模板文件进行计算,直到分进相应的类别,这就是SVM 模型的文本分类方式。
基于SVM的系统实现(如图所示)
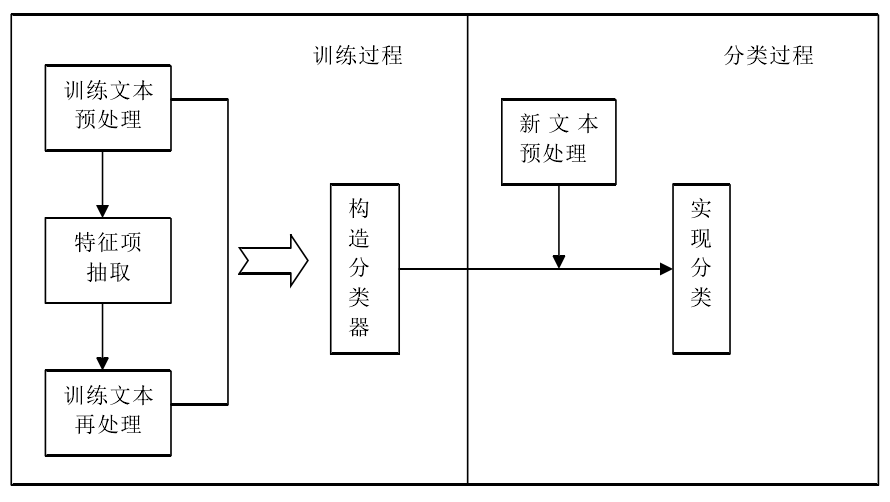
本实验采用libsvm工具包进行svm的分类,具体过程可参考使用libsvm实现文本分类














 804
804











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









